Working with NULLs
Working with NULLs
- TRY_CAST and TRY_CONVERT Functions
- ISNULL and COALESCE Functions
- NULLIF Function
Joining Tables on Nullable columns
Subqueries and NULLs
Set Operators and NULLs
Enforcing Uniqueness with NULLs
Handling NULLs when creating tables and constraints
Working with NULLs:
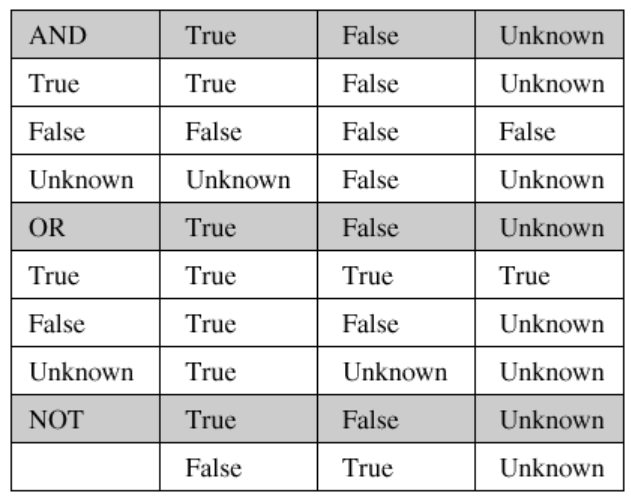
Two-valued predicate logic limits values to be True or False. However, missing values are neither True or False; they are evaluated as Unknown. SQL supports the implementation of three-valued predicate logic, where a predicate can be evaluated as either True, False, or Unknown. Edward Codd took this further and evangelized four-valued predicate logic, which considers two different cases for missing values: missing but applicable (A-Values marker) and missing but inapplicable (I-Values marker). SQL supports only the generic instance of missing values and does not recognize the two distinctions for cases for the missing values.
SQL and T-SQL utilizes three-valued predicate logic where predicates can evaluate to TRUE, FALSE, or UNKNOWN. NULLs represent missing values. Non-NULL values evaluate to TRUE or FALSE, whereas NULL values evaluate to UNKNOWN. For query filters (like WHERE or HAVING clauses), SQL accepts records that are TRUE, while both FALSE and UNKNOWN records are rejected. For CHECK constraints, SQL “rejects FALSE”, meaning records that evaluate to either TRUE or UNKNOWN are accepted. With three-valued predicate logic, “accept TRUE” rejects UNKNOWNs, while “reject FALSE” accepts UNKNOWNs. In other words, all records that are NULL in query filters will get discarded because they are not evaluated to TRUE but rather UNKNOWN. However, since CHECK constraints just rejects FALSE, NULLs are accepted because they are not FALSE but rather UNKNOWN.
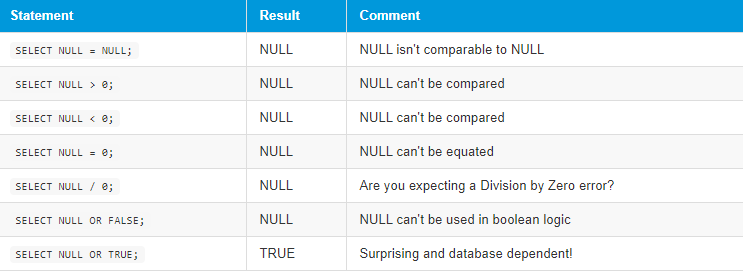
A NULL value represents the absence of data, in other words, data that is missing or unknown. When coding queries, stored procedures, or any other T-SQL, it is important to keep in mind the nullability of data because it will affect many aspects of your logic. For example, the result of any operator (for example, +, -, AND, and OR) when either operand is NULL is NULL.
- NULL + 10 = NULL
- NULL OR TRUE = NULL
- NULL OR FALSE = NULL
Missing values and empty values are two different things. An integer whose value is missing is not the same as an integer whose value is zero. A null string is not the same as a zero-length string or one containing only blanks. This distinction is important because comparisons between empty values and missing values always fail. In fact, NULL values aren’t even equal to one another in such comparisons. The possibility of missing values in relational data indicates that there are three possible outcomes for any comparison: True, False, and Unknown.
When we see a nullable field, it means that most records will have data in the field but by design the table is flexible enough to allow exceptions to the rule. Conversely, when a column in a database table(s) is defined as NOT NULL, it must reject any record that does not contained any value.
Because NULLs represent missing values, SQL can’t determine if one missing value is equal to another. Therefore, SQL provides us with the IS NULL and IS NOT NULL predicates, which should be used instead of = NULL and <> NULL respectively.
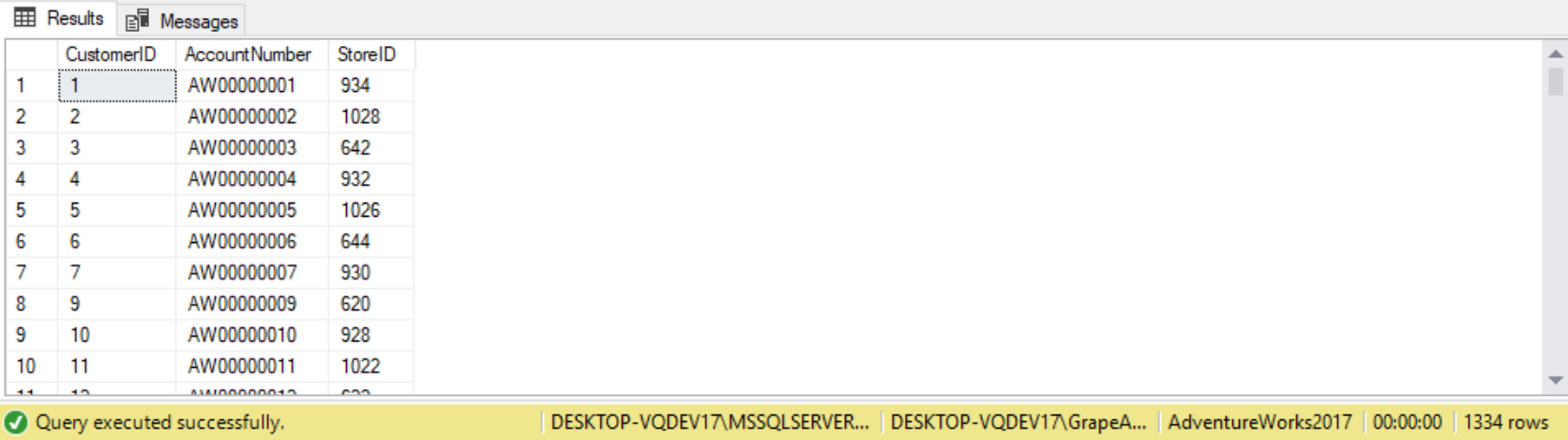
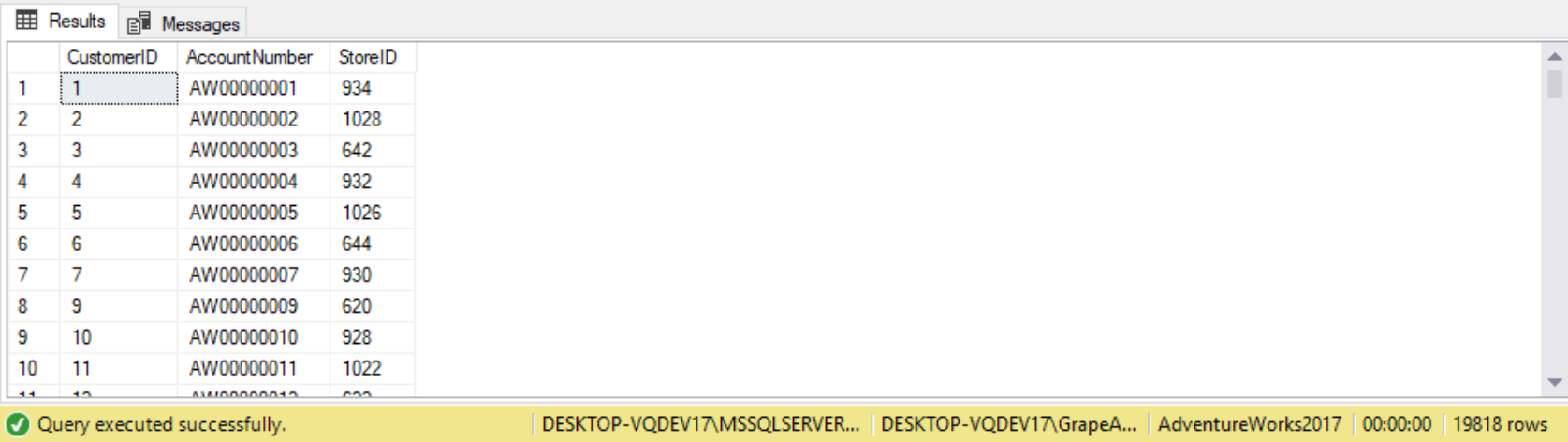
For example, the Sales.Customer table has three attributes storing customer location information: country, region, and city. Some values in the region attribute is missing but applicable. The following query returns all customers where the region is equal to WA:
SELECT CustomerID,
AccountNumber,
StoreID
FROM Sales.Customer
WHERE StoreID = '1024';

Out of the 91 records in the table, only three records evaluate to TRUE and are returned in the result set. All records that are missing (UNKNOWN) or different from WA (FALSE) are discarded. The following query returns all records where the region is different from WA:
SELECT CustomerID,
AccountNumber,
StoreID
FROM Sales.Customer
WHERE StoreID != '1024';
Because a query filter only accepts records that evaluate to TRUE, the above query did not return any rows where the region is equal to WA or NULL. The same result would be returned if we used NOT(region =N’WA’) in our query.
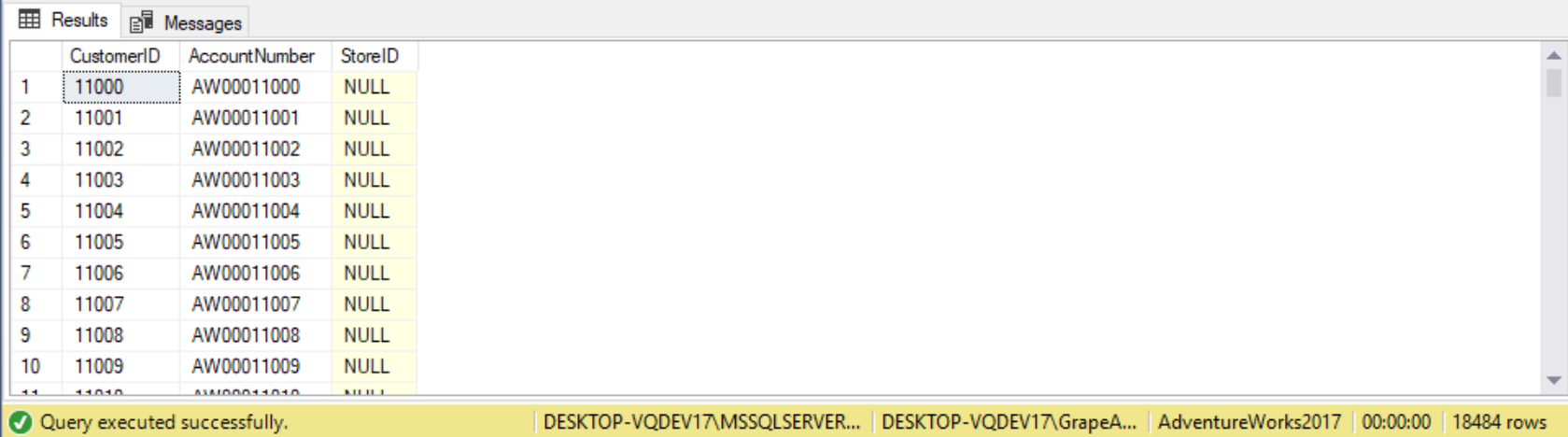
It is not recommended to use “=NULL” to return records that are NULL, because the expression it returns records that evaluate to UNKNOWN – whether present or missing. For example, the following query returns an empty set:
SELECT CustomerID,
AccountNumber,
StoreID
FROM Sales.Customer
WHERE StoreID = NULL;

We should, instead use the IS NULL predicate:
SELECT CustomerID,
AccountNumber,
StoreID
FROM Sales.Customer
WHERE StoreID IS NULL;
If we wish to return all regions different from WA, including records that are NULL, we need to explicity include that in our query:
SELECT CustomerID,
AccountNumber,
StoreID
FROM Sales.Customer
WHERE StoreID != '1024'
OR StoreID IS NULL;
NULL is a data value, while UNKNOWN represents a logical value. The distinction is the reason you must use …WHERE column IS NULL rather than …WHERE column = NULL if you want your SQL to behave sensibly. (T-SQL doesn’t forbid the latter syntax, but since one NULL never equals another—or even itself—it never returns True).
When filtering for NULLs in queries, we use IS NULL or IS NOT NULL operators. Since NULL denotes the absence of a value, the = or != operators do not recognize NULLs. There is nothing that can be equal to a NULL. Not even a NULL can be equal to a NULL! The only time an equal sign is used with a NULL (SET attribute =NULL) is when assigning NULL to a field. Here the equal sign is not acting as a comparison operator, so it does not conflict with the rule about NULL and comparison operators. We can set a NULL field to a real value or replace a real value with a NULL.
When we create a table, we can specify each field as NULL or NOT NULL. If no specification is made, then SQL Server defaults NULLs to ON (nullable) for those fields. The “ANSI NULL default” standard specifies that if we don’t explicitly specify nullability for a field then it should be NOT NULL. SQL Server does the opposite of this and sets the “ANSI NULL default” to OFF (non-nullable).
As with simple expressions, most functions involving NULL values as input return NULL, so SELECT SIGN(NULL) returns NULL, as do SELECT ABS(NULL) and SELECT LTRIM(NULL). The exceptions to this are functions designed to work with NULL in the first place. In addition to aggregates, built-in functions that SQL Server provides to overcome some of the hurdles associated with working with work with NULLs include: TRY_CAST, TRY_CONVERT, ISNULL, COALESCE, and NULLIF.
Suppose we have a table with a nullable column. You would like to return rows where that column is NULL or where the column is not NULL. Te first hurdle to overcome when working with NULLs is to remove this WHERE clause from your mind: WHERE SomeColumn = NULL. Te second hurdle is to remove this clause: WHERE SomeCol <> NULL. NULL is an “unknown” value. Because the value is unknown, SQL Server cannot evaluate any operator where an input to the operator is unknown. To search for NULL values, we use the unary operators IS NULL and IS NOT NULL. Specifically, IS NULL returns true if the operand is NULL, and IS NOT NULL returns true if the operand is defined. Take the following statement:
DECLARE @value INT= NULL;
SELECT CASE
WHEN @value = NULL
THEN 1
WHEN @value <> NULL
THEN 2
WHEN @value IS NULL
THEN 3
ELSE 4
END;

This simple CASE statement demonstrates that the NULL value stored in the variable @value cannot be evaluated with traditional equality operators. Te IS NULL operator evaluates to true, and the result of the
statement is the following:
SELECT TOP 5 LastName,
FirstName,
MiddleName
FROM Person.Person
WHERE MiddleName IS NULL;

Te IS NULL operator evaluates one operand and returns true if the value is unknown. Te IS NOT NULL operator evaluates on operand and returns true if the value is defined. Previous recipes in this chapter introduced the ISNULL and COALESCE functions. Te ISNULL function is often confused with the IS NULL operator. After all, the names differ by only one space. Functionally, the ISNULL operator may be used in a WHERE clause; however, there are some differences in how the SQL Server query plan optimizer decides how to execute statements with IS NULL vs. ISNULL used as a predicate in a SELECT statement. Look at the following three statements that query the JobCandidate table and return the JobCandidate rows that have a non-NULL BusinessEntityID. All three statements return the same rows, but there is a difference in the execution plan. The first statement uses ISNULL to return 1 for NULL values and returns all rows where ISNULL does not return 1.
SET SHOWPLAN_TEXT ON;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE ISNULL(BusinessEntityID, 1) <> 1;
GO
SET SHOWPLAN_TEXT OFF;
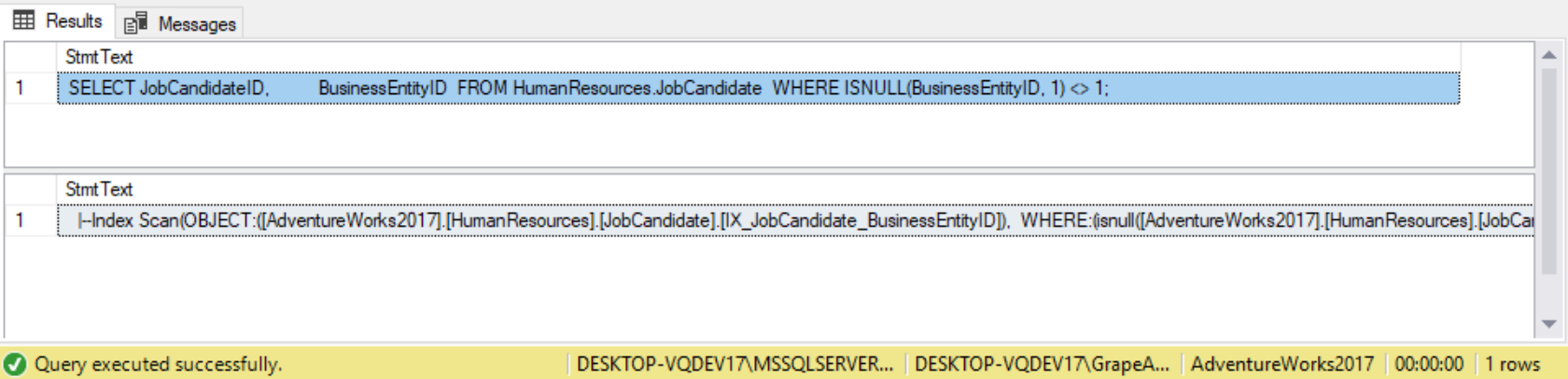
Te execution plan contains an index scan. In this case, SQL Server will look at every row in the index to satisfy the results. Maybe the reason for this is the inequality operator (<>). Te query may be rewritten as follows:
SET SHOWPLAN_TEXT ON;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE ISNULL(BusinessEntityID, 1) = BusinessEntityID;
GO
SET SHOWPLAN_TEXT OFF;
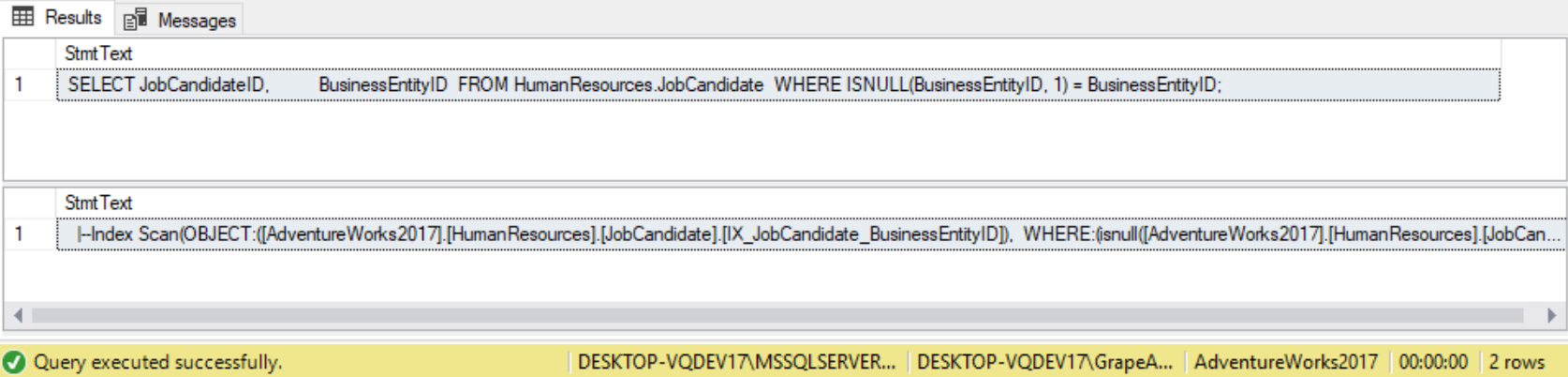
Again, the query optimizer chooses to use an index scan to satisfy the query. What happens when the IS NULL operator is used instead of the ISNULL function?
SET SHOWPLAN_TEXT ON;
GO
SELECT JobCandidateID,
BusinessEntityID
FROM HumanResources.JobCandidate
WHERE BusinessEntityID IS NOT NULL;
GO
SET SHOWPLAN_TEXT OFF;
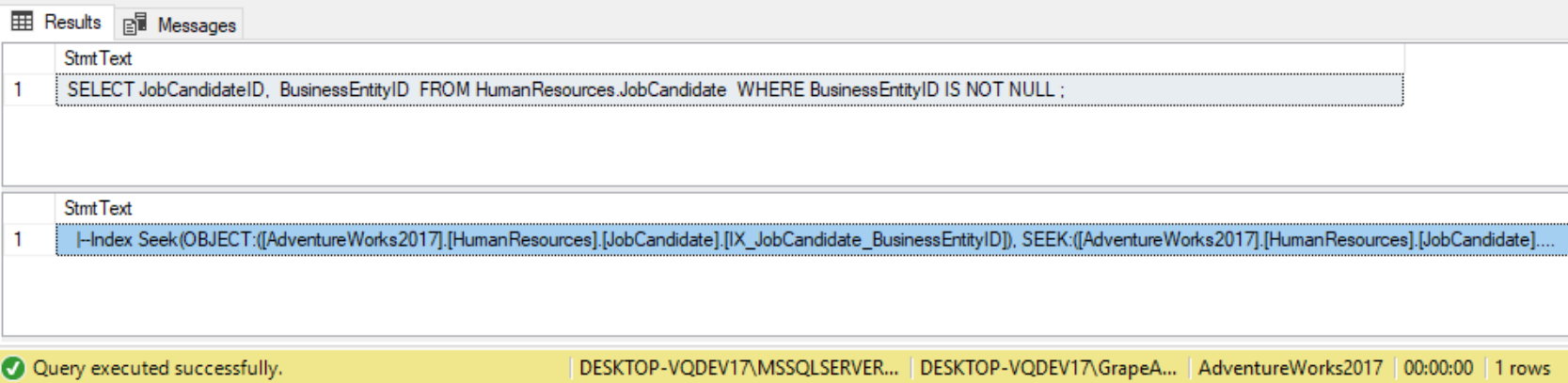
By using the IS NULL operator, SQL Server is able to seek on the index instead of scan the index. ISNULL() is a function, when a column is passed into a function SQL Server must evaluate that function for every row and is not able to seek on an index to satisfy the WHERE clause.
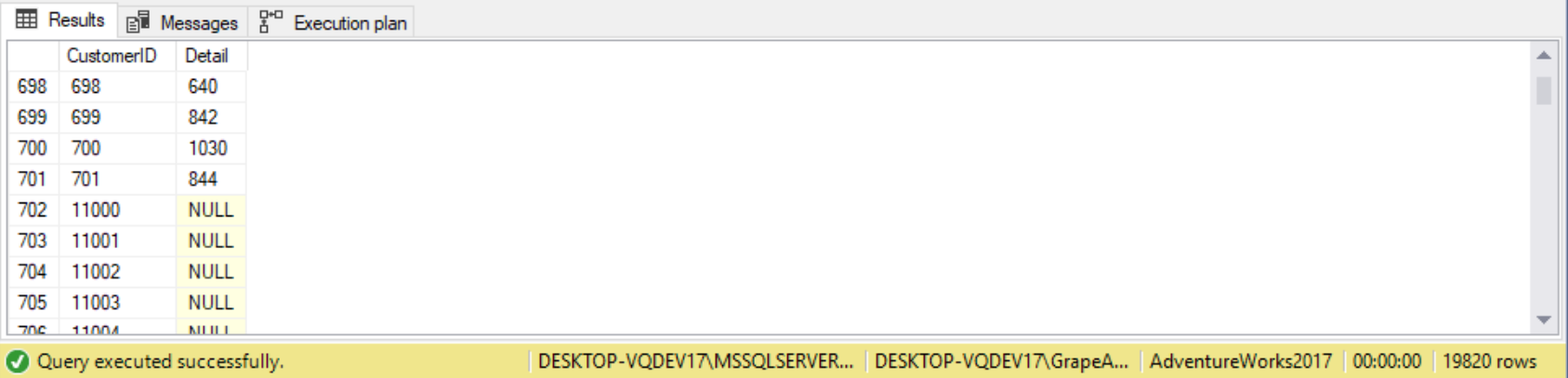
By default in T-SQL, concatenation with a NULL will return a NULL:
SELECT CustomerID,
+N' '+StoreID AS Detail
FROM Sales.Customer;
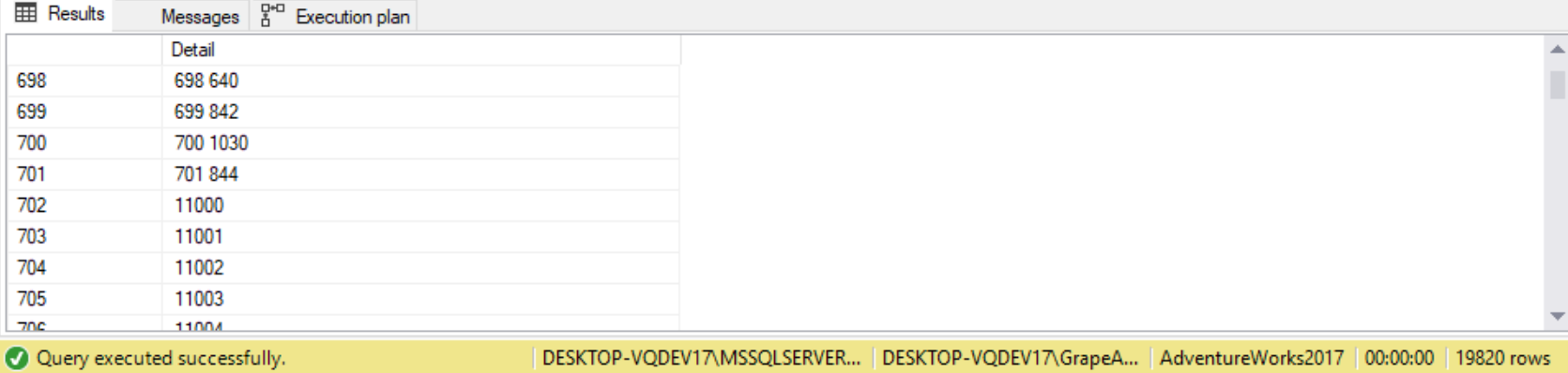
The CONCAT function accepts a list of inputs to be concatenated and automatically substitutes NULLs with empty strings. For example, the following query concatenates the customer’s location elements using the CONCAT function, replacing NULLs with empty strings:
SELECT CONCAT(CustomerID, N' ', StoreID) AS Detail FROM Sales.Customer;
Aggregate functions ignore NULLs, with the exception of COUNT(*). The following is an example of using the DISTINCT option with an aggregate function:
(Include code from Single Table Query section of visualizeright website)
For grouping and sorting purposes, all NULLs are considered equal. The GROUP BY clause will arrange all NULLs into a single group, and the ORDER BY clause sorts all NULLs together. ANSI SQL leave it to the RDBMS vendor to determine whether NULLs should be sorted before or after non-NULL records. T-SQL sorts NULLs before all non-NULL records or groups. While enforcing the UNIQUE constraint, standard SQL treats NULLs as different from each other, so to allow multiple NULLs. UNIQUE constraints in T-SQL treats all NULLs as equal, allowing only one NULL.
If there is no ELSE clause, the CASE expression defaults to ELSE NULL. For example, in the following query the CASE expression in the SELECT clause produces a description for the categoryid column in the Production.ProductCategory table:
(Include code from Single Table Query section of visualizeright website)
The ISNULL and COALESCE functions are abbreviations of the CASE expression.
TRY_CAST and TRY_CONVERT:
TRY_ functions accepts the same arguments as their counterparts and returns the same conversions, except that it returns NULL if the input is not convertible to the target data type. TRY_CAST and TRY_CONVERT functions are used to detect potential errors in our data. For example, suppose we have a source from which we’re bringing data in, and we’re taking the string type from a source column and converting that to dates. If a user is entering data manually on the source and they input values that the RDBMS doesn’t allow conversion to dates, then by default the RDBMS will return an error when the CAST or CONVERT functions are applied to convert the manually inputted data to dates. So, everything breaks automatically, and our code will not run as we expect it to. TRY_CAST and TRY_CONVERT allows us to mitigate such scenarios because these consider potentially bad data and mistakes from user-entry forms. So, if our code involves converting string values to dates and the RDBMS is not converting that the way we would expect it to, then it will return NULLs instead of an error message.
TRY_CONVERT, like the traditional CONVERT, will also give you those additional styling options. For example, TRY_CONVERT will return dates in any format we wish. TRY_CAST does not provide this additional functionality.
TRY_CASE has all compatibility levels and is even supported in Windows Azure SQL Database. TRY_CONVERT is compatible with SQL Server 2012 or greater and is not supported in Windows Azure.
/* Cannot return string as an integer
unless string NOT alpha characters */
SELECT CAST('TEST' AS INT) AS Test; --Returns error message
SELECT CONVERT(INT, 'TEST') AS Test; --Returns error message

--Returns NULL instead of error message
SELECT TRY_CAST('TEST' AS INT) AS Test;
SELECT TRY_CONVERT(INT, 'TEST') AS Test;

--Cannot convert INT to DATE SELECT CAST(20150606 AS DATE) AS Test; --Returns error message SELECT TRY_CAST(20150606 AS DATE) AS Test; --Returns error message

SELECT CASE
WHEN TRY_CAST('2016-01-32' AS DATE) IS NULL
THEN 'Cast Failed'
ELSE 'Cast Succeeded'
END AS Result;

ISNULL and COALESCE
Two main functions that deal with NULL values are ISNULL and COALESCE. COALESCE is ANSI standard, meaning the code can be migrated to other SQL platforms such as Oracle PL/SQL. ISNULL is proprietary to SQL Server.
ISNULL is limited to only two parameters. We can work around that by using nesting ISNULL inside another ISNULL function to handle multiple parameters.
The COALESCE function returns the first non-NULL value from a provided list of expressions. For example, suppose we have a list of values that may contain NULLs, and you would like to return the first non-NULL value from your list. We can use the COALESCE function to achieve this, as follows:
SELECT c.CustomerID,
SalesPersonPhone = spp.PhoneNumber,
CustomerPhone = pp.PhoneNumber,
PhoneNumber = COALESCE(pp.PhoneNumber, spp.PhoneNumber, '**NO PHONE**')
FROM Sales.Customer c
LEFT OUTER JOIN Sales.Store s ON c.StoreID = s.BusinessEntityID
LEFT OUTER JOIN Person.PersonPhone spp ON s.SalesPersonID = spp.BusinessEntityID
LEFT OUTER JOIN Person.PersonPhone pp ON c.CustomerID = pp.BusinessEntityID
ORDER BY CustomerID;
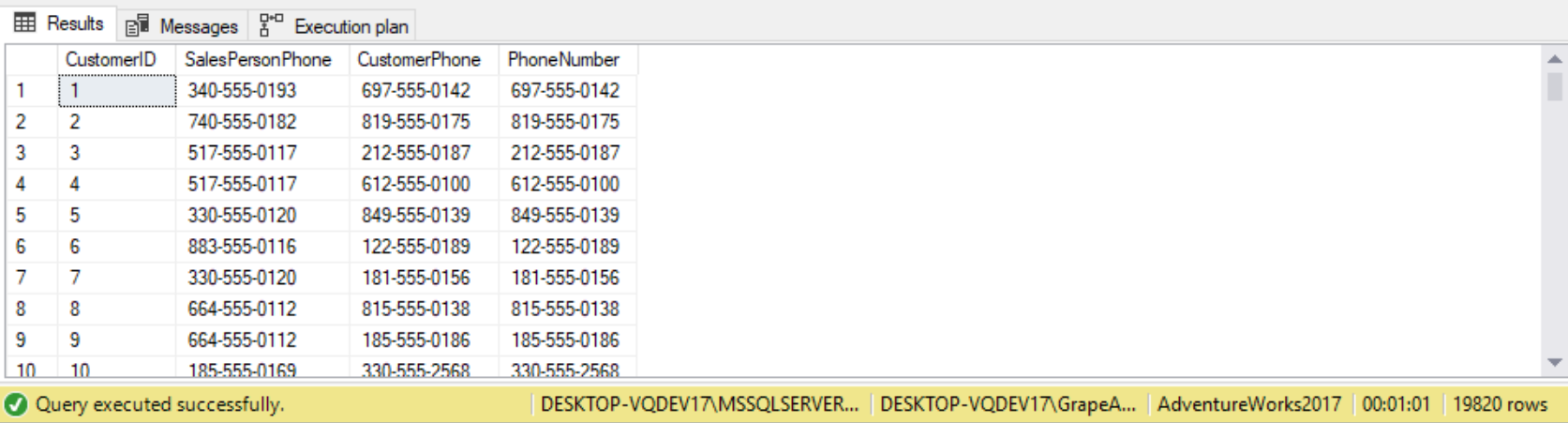
In this recipe, you know that a customer is either a customer in the Person table or the SalesPerson associated with a Store. You would like to return the PhoneNumber associated with all of your customers. You use the COALESCE function to return the customer’s PhoneNumber if it exists; otherwise, you return the SalesPerson’s PhoneNumber. Note that a third value was added to the COALESCE function: ‘** NO PHONE **’. Te COALESCE function will not return a non-NULL value and will raise an error if all choices evaluate to NULL. It is good practice when using COALESCE in conjunction with an OUTER JOIN or NULLABLE columns to add a known non-NULL value to the list of choices for COALESCE to choose from.
One difference between the two functions is the data type returned by the function when the parameters are different data types. Take the following example:
DECLARE @sql NVARCHAR(MAX) = '
SELECT ISNULL(''5'', 5),
ISNULL(5, ''5''),
COALESCE(''5'', 5),
COALESCE(5, ''5'') ;
' ;
EXEC sp_executesql @sql ;
SELECT column_ordinal,
is_nullable,
system_type_name
FROM master.sys.dm_exec_describe_first_result_set(@sql, NULL, 0) a ;
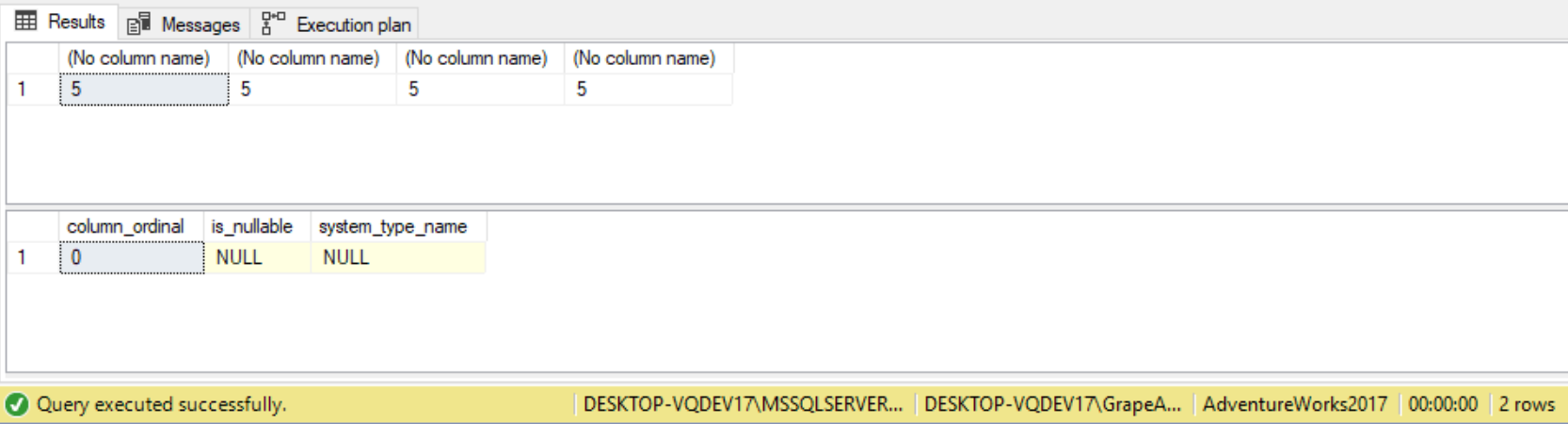
Note that the type returned from ISNULL changes depending on the order of the input parameters, while COALESCE returns the data type of highest precedence regardless of argument order. So long as an implicit
conversion exists between the value selected by the ISNULL or COALESCE function and the return type selected, the function will implicitly cast the return value to the return type. However, be aware that if an implicit conversion does not exist between the return type and value to be returned, SQL Server will raise an error.
If we pass three parameters in a COALESCE function, for example two VARCHAR and one INT, the COALESCE function will return an INT data type for the column because INT has the highest precedence. On the other hand, ISNULL will return the data type of the first parameter, whatever that may be. For example, if VARCHAR is the first datatype passed in, then that will be the data type returned.
--Return first non-NULL parameter DECLARE @sql1 INT= NULL, @sql2 INT= NULL, @sql3 INT= 3; SELECT COALESCE(@sql1, @sql2, @sql3); --If first parameter is NULL, return second parameter SELECT ISNULL(@sql1, @sql2); --Works the same way as COALESCE with three parameters SELECT ISNULL(ISNULL(@sql1, @sql2), @sql3);
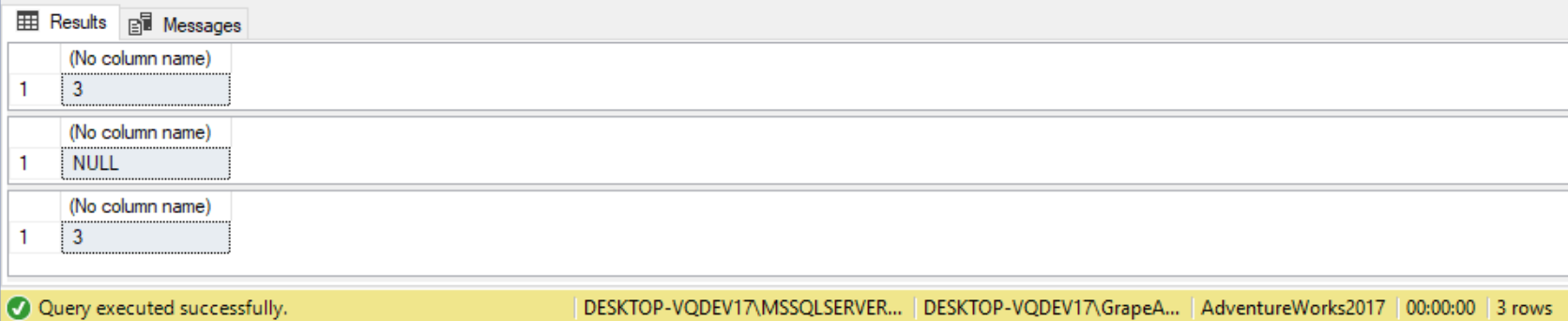
/* Returns highest precedence parameter regardless of position of not NULL */ DECLARE @sql1 VARCHAR(10)= NULL, @sql2 INT= NULL, @sql3 INT= 3; SELECT COALESCE(@sql1, @sql2, @sql3)+'TEST';

/* If first parameter is NUL, return second parameter. Works the same way as COALESCE with three parameters */ DECLARE @sql1 VARCHAR(10)= NULL, @sql2 INT= NULL, @sql3 INT= 3; SELECT ISNULL(ISNULL(@sql1, @sql2), @sql3)+'TEST';

(ISNULL works here because ‘TEST’ is a VARCHAR data type, and the first parameter for the ISNULL query is a VARCHAR. For the COALESCE()query, the highest precedence parameter is an integer, so the query returns an error message because ‘TEST’ is a VARCHAR and not an INT.)
(Note: For a complete list of data types in SQL Server listed in order of precedence, refer to sQL server Books Online at http://msdn.microsoft.com/en-us/library/ms190309(v=sql.110).aspx) )
The nullability of the return value may be different as well. Take the case where an application requests LastName, FirstName, and MiddleName from a table. Te application expects the NULL values in the MiddleName
columns to be replaced with an empty string. Te following SELECT statement uses both ISNULL and COALESCE to convert the values, so the differences can be observed by describing the result set.
DECLARE @sql NVARCHAR(MAX)= '
SELECT TOP 10
FirstName,
LastName,
MiddleName_ISNULL = ISNULL(MiddleName, ''''),
MiddleName_COALESCE = COALESCE(MiddleName, '''')
FROM Person.Person ;
';
EXEC sp_executesql
@sql;
SELECT column_ordinal,
name,
is_nullable
FROM master.sys.dm_exec_describe_first_result_set(@sql, NULL, 0) a;
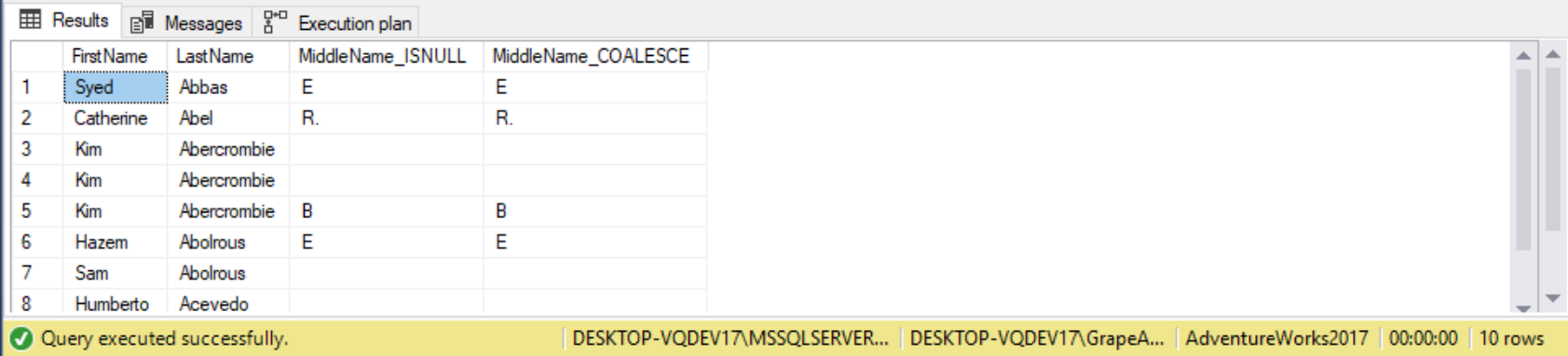
It is important to understand the nuances of the function you are using and how the data returned from ISNULL and COALESCE will be used. To eliminate the confusion that may occur with implicit type conversions, type precedence rules, and nullability rules, it is good practice to explicitly cast all inputs to the same type prior to input to ISNULL or COALESCE.
ISNULL translates a NULL value into a non-NULL value. ISNULL validates whether an expression is NULL and, if so, replaces the NULL value with an alternate value. For example, suppose we are are selecting rows from a table, and our results contain NULL values. You would like to replace the NULL values with an alternate value. Our query would go as follows:
(Include code and result from T-SQL recipes book)
In this example, the column CreditCardApprovalCode contains NULL values for rows where there is no credit approval. Tis query returns the original value of CreditCardApprovalCode in the second column. In the third column, the query uses the ISNULL function to evaluate each CreditCardApprovalCode. If the value is NULL, the value passed to the second parameter of ISNULL—**NO APPROVAL**’—is returned. It is important to note that the return type of ISNULL is the same asthe type of the first parameter. To illustrate this, view the following SELECT statements and their results. The first statement attempts to return a string when the first input to ISNULL is an integer:
(Include code and result from T-SQL recipes book page 42)
Note that the 20-character string is truncated to 10 characters. Tis behavior can be tricky because the type of the second parameter is not checked until it is used. For example, if the first example is modified so that the non-NULL value is supplied in the first parameter, no error is generated.
(Include code and result from T-SQL recipes book page 43)
No error is generated in this query because the second parameter is not used. When testing your use of ISNULL, it is important both to test the conditions where NULL and non-NULL values are supplied to the first parameter and to take note that any string values are not truncated.
Caution should be exercised when using ISNULL, since translating NULLs to other values can have unexpected side effects. For example, the AVG query from the example above can’t ignore translated NULLs:
(Include code and result from Guru’s guide page 76)
The value zero is figured into the average, significantly lowering it. Note that ISNULL’s parameters aren’t limited to constants. Consider this example:
(Include code and result from Guru’s guide page 76)
Here, both arguments consist of expressions, including the one returned by the function. ISNULL() can even handle SELECT statements as parameters, as in this example:
(Include code and result from Guru’s guide page 76)
There are generally two camps when it comes to making one’s mind up between ISNULL and COALESCE:
- ISNULL is easier to spell, and the name makes more sense; use COALESCE only if you have more than two arguments and even then consider chaining your calls to ISNULL to avoid COALESCE, like so: ISNULL(value1, ISNULL(value2, ISNULL(value3, ”))).
- COALESCE is more flexible and is part of the ANSI standard SQL so is a more portable function if a developer is writing SQL on more than one platform.
At their core, both the ISNULL and COALESCE functions essentially accomplish the same task. However, the functions have some subtle differences, and being aware of them may assist in debugging efforts. On the surface, ISNULL is simply a version of COALESCE that is limited to two parameters; however, ISNULL is a function that is built into the SQL Server engine and evaluated at query-processing time, and COALESCE is expanded into a CASE expression during query compilation. There are a number of discussions regarding the performance of ISNULL vs. COALESCE. For most uses of these functions, the performance differences are negligible. There are some cases when using correlated subqueries where ISNULL and COALESCE will cause the query optimizer to generate different query plans with COALESCE generating a suboptimal plan compared to ISNULL.
NULLIF Function
NULLIF functions are great for dealing with “divide by zero” errors. NULLIF compares for two expressions. NULLIF compares the first expression, and if it is equal to the second expression then NULL is returned; otherwise, the first expression is returned.
(Include code and result from PW)
The NULLIF() function is a rough inverse of ISNULL(). Though it doesn’t handle NULL values being passed
into it any better than any other function, it was designed to return a NULL value in the right circumstances. It takes two parameters and returns NULL if they’re equal; otherwise it returns the first parameter. For example,
(Include code and result from Guru’s guide page 76)
returns NULL, while
(Include code and result from Guru’s guide page 76)
returns 5.
Suppose we are attempting to understand production delays and have decided to report on the average variance between ActualStartDate and ScheduledStartDate of operations in your production sequence. You would like to understand the following:
- What is the variance for all operations?
- What is the variance for all operations where the variance is not 0?
Our query would go as follows:
(Include code and result from T-SQL recipes book page 50)
Te query includes two columns that use the aggregate function AVG to return the average difference in days between the scheduled and actual start dates of a production sequence for a given product. The column StateDateVariance includes all of the rows in the aggregate. Te column StartDateVariance_Adjusted eliminates rows where the variance is 0 by using the NULLIF function. The NULLIF function accepts the result of DATEDIFF as the first parameter and compares this result to the value 0 that we passed to the second parameter. If DATEDIFF returns 0, NULLIF returns NULL, and theNULL value is eliminated from the AVG aggregate.
Joining tables on Nullable columns
Suppose we need to join two tables but have NULL values in one or both sides of the join. When joining on a nullable column, remember that the equality operator returns false for NULL = NULL. Let’s see what happens when you have NULL values on both sides of a join. Create two tables with sample data.
(Include code and result from T-SQL recipes book page 55)
Predicates in the join condition evaluate NULLs the same way as predicates in the WHERE clause. When SQL Server evaluates the condition t1.TestValue = t2.TestValue, the equals operator returns false if one or both of the operands is NULL; therefore, the only rows that will be returned from an INNER JOIN are rows where neither side of the join is NULL and those non-NULL values are equal.
The LEFT JOIN will return all records from the first table (the table on the left side of the JOIN keyword), and also matching records from the second table (the table on the right side of the JOIN keyword). NULL is returned for any records from the first table having no matches from the second table. For example:
(Include code from JOINs section of portfolio website)
Suppose we wish to return only outer rows, rows with no matches on the other table. We can update our previous query by adding a WHERE filter to return only those outer rows. Since the outer rows returns NULL on attributes from the nonpreserved table, we can simply filter for only rows that return NULL from the nonpreserved table, like the following query:
(Include code, explanation, and results from page 139).
Remember to always use IS NULL and not =NULL. This is because if we use the equality operator to compare values to a NULL, it always evaluates to UNKNOWN, even if we’re comparing two NULLs. There are three cases for selecting the ideal preserved attribute that can produce outer rows: a primary key column, a join column, and a column defined as NOT NULL. A primary key column and a column defined as NOT NULL cannot have NULL records, so a NULL returned from a nonpreserved table can only mean the row is an outer row. If a row has a NULL in the join column, that row is filtered out by the second phase of the join, so a NULL in such a column can only means that it’s an outer row.
The RIGHT JOIN is similar to the LEFT JOIN, the only difference being that the tables are switched around. In other words, with a right join, all records from the second table (the table on the right side of the JOIN keyword) is returned, and also matching records from the first table (the table on the right side of the JOIN keyword). NULL is returned for any records from the second table having no matches from the first table. For example, the following query joins the Customers and Orders tables to return customers and their orders. In this case, all rows from the customers table are preserved. For customers with no orders, the query returns NULL for ordered:
(Include code from JOINs section of portfolio website)
As we can see customer ID 27 and 57 from the Customers table placed no orders, so the query returns NULL for orderid from the Orders table. The records for those two customer IDs were discarded by the second logical querying phase since there were no matching records on the Orders table, but the third logical querying phase added those two records back to the result set as outer rows. Those two rows were added back to preserve all rows of the left (Customers) table.
The FULL OUTER join will return all records from both tables. It’s essentially a combination of a LEFT JOIN and a RIGHT JOIN. If a match is found, then the matching records are returned, otherwise NULL is returned. It’s similar to a LEFT JOIN or RIGHT JOIN, but differs in that it looks for matches both ways and displays NULL in either set of data. For example, the following query uses a full outer join to return all the currencies we can place orders in and which orders were placed in those currencies.
(Include code from JOINs section of portfolio website)
(Include code, explanation, and results from page 17 of ADVANCED BOOK).
The above full outer query consists of 1.) All matching rows from both tables. 2.) All rows from the Employees tables with no matching department, with NULLs replacing the values that were supposed to come from the Departments table. 3.) All rows from the Departments table with no matching employee, with NULLS replacing the values that were supposed to come from the Employees table. With left and right outer joins, the order in which the tables appear in the query determines the order of their processing. This, of course, makes sense because their order affects the output. In the case of full outer joins however, their order doesn’t affect the output; hence, it doesn’t determine their processing order.
Outer joins enable us to define either one or both tables participating in the join as preserved tables. The third logical querying processing phase of the outer join identifies rows from the preserved table that have no matches in the other table on the ON predicate. This means that besides returning matching rows from both tables, the rows from the preserved table that have no match in the other table are also returned, padded with NULLs instead of the values that were supposed to come from the other table.
Because outer joins not only return matching rows but also those that don’t, can be used to identify and include missing values when querying data. For example, suppose we’re concerned that we may have some ProductSubcategory entries that don’t match to Categories. We can test this by running the following query:
(Include code from JOINs section of portfolio website)
The outer join returns the unmatched rows as NULLs. The WHERE clause filters on the non-NULL records, leaving only nonmatching Subcategory names for us to review.
If a predicate in the WHERE clause involves an attribute from the nonpreserved table using an expression in the form of <attribute><operator><value>, it’s usually an indication of a bug. This is because attributes from the nonpreserved table are NULLs in outer rows, and an expression in the form of NULL<operator><value> yields UNKNOWN unless we’re using the IS NULL operator. Remember the WHERE clause filters out records that evaluate to UNKNOWN. Such a predicate in the WHERE clause will filter out all outer rows, effectively turning the outer join into an inner join. So there’s a mistake in either the join type or the predicate. For example, let’s examine the following query:
(Include code, explanation, and results from page 143)
The above query applies a left outer join between the Customer and Order tables. The predicate o.orderdate>=’20160101’ in the WHERE clause evaluates for UNKNOWN for all the outer rows, because those records are NULL in the o.orderdate column. All other rows are discarded by the WHERE filter, as we see in the results.
As we can see, the outer join here was futile. There was either a mistake in using an outer join or specifying a predicate in the WHERE clause.
Subqueries and NULLs
If a scalar subquery returns no value, the empty result is converted to a NULL. Comparison with a NULL evaluates to UNKNOWN, and the query filter does not return a row. For example, the Employees table has no last name starting with the letter A, so we get returned an empty set in the following query:
(Include code, explanation, and result from page 160)
If our subquery returns a NULL value, the EXISTS statement resolves to TRUE. This behavior is unique to the EXISTS clause. In the following example all the SalesOrderHeader rows are returned as the WHERE clause essentially resolved to TRUE:
(Include code from Subqueries section of portfolio)
The IN operator allows us to conduct multiple match tests compactly in one statement.
When the comparison list contains NULL, any value compared to that list returns false. For instance, the following query returns zero rows. This is because the IN clause always returns false. This is in contrast to EXIST, which returns TRUE even when the subquery returns NULL.
(Include code from the Ben Gan book- missing on portfolio site)
It is good practice to qualify subqueries to exclude NULLs. The ANY predicate can be substituted for the equivalent IN predicate. The same rules regarding the handling of NULLs apply.
There may be some problems that arise when we forget about NULLs and the three-valued predicate logic when working with subqueries. For example, the following query is supposed to return customers who did not place orders:
(Include code, explanation, and result from page 170)
Currently, the query does seem to work as expected. Let’s run a query that inserts a new order into the Orders table with a NULL customer id:
(Include code, explanation, and result from page 171)
We now run the query again:
(Include code, explanation, and result from page 171 – second one)
This time the query returns an empty return set. The culprit here is the NULL customer id record that we added to the Orders table. The IN predicates returns TRUE for customers who placed orders in the subquery. The NOT operator negates the IN predicate, so those customer records get discarded since they not evaluate to FALSE by the NOT operator. What we expected is that any customer id appearing in the Orders table will not get returned. However if the IN predicate evaluates to UNKNOWN for customer ids in the Customers table (outer table) that do not appear in the customer IDs attributes of the Orders table (subquery table). This is because the IN predicate evaluates to FALSE when comparing customer ids in the Customers table to non-NULL customer ids in the Orders table, and evaluates to UNKNOWN when comparing customer ids in the Customers table to NULL customer ids in the Orders table. Records evaluating to FALSE or UNKNOWN yield UNKNOWN. Negating the UNKNOWN with the NOT operator will still evaluate to UNKNOWN. In other words, in a case where it’s unknown whether a customer ID appears in a set, it’s also unknown whether it doesn’t appear in the set. Remember, the query filter discards rows in the result set for which the predicate evaluates to FALSE.
So in summary, when we use the NOT IN predicate against a subquery that returns at least one NULL, the query always returns an empty set.
(^^ Maybe test and re-write the paragraph in red – page 171)
One way around this is to define columns that are not supposed to contain NULLs as NOT NULL. Also, for all queries we write, we should consider the possibility of NULLs and three-valued predicate logic. For example, previous query returns an empty result set because of the comparison with the NULL. To check whether a customer ID appears only in a set of non-NULL values, we need to exclude NULLs either explicitly or implicitly. To exclude NULLs explicitly, we add the predicate o.custid IS NOT NULL to the subquery, like this:
(Include code, explanation, and result from page 172)
We can also exclude NULLs implicitly by using the NOT EXISTS predicate instead of NOT IN, like follows:
(Include code, explanation, and result from page 172)
We finally run the following query for cleanup:
(Include code, explanation, and result from page 172)
The ALL modifier works in similar fashion to ANY except it returns the outer row if its comparison value is greater than every value returned by the inner query. In other words, ALL is more restrictive in that all of the values in the subquery must satisfy the comparison condition.
(Include code from Subqueries section of portfolio)
The MAX aggregate function is used when we wish to find the highest value of something. The ALL predicate can accomplish the same thing. The MAX function discards NULLs and returns the first non-NULL record. With the ALL predicate, ALL literally means all. So if there is at least one NULL record, then the ALL predicate is FALSE because any comparison with FALSE is FALSE. The fix to this is to filter out any NULLs inside the inner query.
(Include code, explanation, similar to the ADVANCED BOOK)
Just like we can find use the ALL predicate to find the maximum value of something, we can also use it to find the minimum. Both the MAX and MIN functions discard NULL records, whereas ALL does not. Again, the fix to the issue would be filter out NULL records.
Set Operators and NULLs
Set operators are used to combine rows returned from two query result sets (or multisets) into a single result. T-SQL supports the following set operators: UNION, UNION ALL, INTERSECT, and EXCEPT (MINUS in the case of Oracle PL/SQL). An interesting feature of set operators is that instead of an equality operator, set operators compares rows between two inputs using a distinct predicate. This predicate evaluates to TRUE when comparing two NULLs. In other words, set operators treat all NULLs as equal. So, set operators will treat NULLs as the same record.
The INTERSECT operator evaluates to TRUE when comparing two NULLs. If instead of INTERSECT we used an INNER JOIN or correlated subquery, we need to add a special treatment for NULLs. For example, assuming e is an alias for the Employees table and cis an alias for the Customers table, we can use the predicate e.region=c.region OR (e.region IS NULL AND c.region IS NULL). With the INTERSECT operator, we don’t explicitly compare corresponding attributes and there is no special treatment for NULLs.
Alternatives to the EXCEPT operator include using outer joins that filter for outer rows, as well as using the NOT EXISTS predicate with a subquery. However, with EXCEPT and other set operators, the comparison is implied, and comparing two NULLs evaluates to TRUE. NULLs aren’t values, therefore NULL = NULL will always evaluate to false. Given this, the INNER/OUTER JOIN will fail to match on joins; however, the EXCEPT operator does match NULLS. Therefore, when using joins and subqueries we need to be explicit with the comparisons, as we also need to explicitly add special treatment for NULLs.
Enforcing Uniqueness with NULLs
Suppose we have a table that contains a column that allows NULLs. There may be many rows with NULL values, but any non-NULL value must be unique. Here is how our query would go:
(Include code and result from T-SQL recipes book page 51)
A unique index may be built on a nullable column; however, the unique index can contain only one NULL.
SQL Server allows filtered indexes where the index is created only for a subset of the data in the table. Drop the unique index created earlier and create a new unique, nonclustered, filtered index on CodeName to index (and enforce uniqueness) only on rows that have a defined CodeName.
(Include code and result from T-SQL recipes book page 52)
If a row is added that violates the unique constraint on the CodeName, a constraint violation will be raised:
(Include code and result from T-SQL recipes book page 52)
A select from the table will show that multiple nulls have been added to the CodeName table; however,
uniqueness has been maintained on defined CodeName values.
Unique constraints and unique indexes will, by default, enforce uniqueness the same way with respect to NULL
values. Indexes allow for the use of index filtering, and the filter will be created only on the rows that meet the filter criteria.
Enforcing Referential Integrity on Nullable columns
Suppose we have a table with a foreign key defined to enforce referential integrity. You want to enforce the foreign key where values are defined but allow NULL values into the foreign key column. Te default behavior of a foreign key constraint is to enforce referential integrity on non-NULL values but allow NULL values even though there may not be a corresponding NULL value in the primary key table. This example uses a Category table and an Item table. Te Item table includes a nullable CategoryId column that references the CategoryId of the Category table. First, we create the Category table and add some values.
(Include code and result from T-SQL recipes book page 53)
Next, we create the Item table and add the foreign key to the Category table.
(Include code and result from T-SQL recipes book page 54)
If a table contains a foreign key reference on a nullable column, NULL values are allowed in the foreign key table. To enforce the referential integrity on all rows, the foreign key column must be declared as non-nullable.
Handling NULLs when creating tables and constraints
The CREATE TABLE statement is used to specify the name of the table we are creating, and within the parentheses we define the columns with their names, data type, and nullability. If we don’t explicitly specify an attribute’s nullability, SQL Server by default will assume the attribute accepts NULLs, but there are settings we can modify to change this behavior. It is good practice to not rely on defaults, and define an attribute as NOT NULL unless there’s a compelling reason otherwise.
Primary-key constraints enforce the uniqueness of rows, and prevent the occurrence of duplicate rows in a table. Primary keys also disallow NULLs in the constraint attributes. Each unique set of values can only appear in one row per table. Only one primary key is allowed per table.
Uniqueness of rows are also enforced through the use of alternate key constraints via unique constraints. Unlike primary keys, we can define multiple unique key constraints for the same table. Also unlike primary keys, unique key constraints allow NULLs. Standard SQL allow multiple NULLs (as if two NULLs are different from each other) for columns with unique keys. SQL Server assume all NULLs are equal, and duplicate NULLs are rejected. To emulate the standard SQL unique constraint behavior, we use a unique filtered index on SQL Server that filters only non-NULL values. For example, suppose we have a column containing SSN information and allowed NULLs, and we create such an index instead of a unique constraint, here’s how the query would go:
(Include code from Fundamentals section of visualizeright website)
We define the unique index, and filter out all SSN that are NULLs from the index so duplicate NULLs will be allowed whereas duplicate non-NULLs are not.
A foreign key enforces referential integrity. The foreign key is defined on one or more attributes in the referencing table, and it references a primary-key or unique constraint attributes in the referenced table (which can a different or possibly same table). We can define the option SET NULL as part of foreign-key definition. With the SET NULL option, the compensating action will set the foreign-key attributes of the related rows NULL. Regardless of what action is chosen, the referencing table will only have orphan rows in the case of the exception with NULLs. Parents with no children rows are always allowed.
Using a check constraint, we can define a predicate a row must meet in order to be entered into a table or be modified.
(Include code from Fundamentals section of visualizeright website)
Any attempt to insert or update a row when the predicate evaluates to FALSE will be rejected by the check constraint. Modifications are only accepted when the predicate evaluates to either TRUE or UNKNOWN (if the column is nullable). SQL is based on the three-valued logic, resulting in two actual actions. A row is either accepted or rejected with a check constraint.