Cursors
Cursors
- Creating a Cursor
- Cursor Sensitivity
- More example uses-cases for Cursors
- Scope of Cursor
- Updating columns using a cursor
- Restricting which columns can be updated using a cursor
- How optimistic locking works
- Scrolling around a cursor
- Why Database Cursors are used
- Performance considerations and best practices
(INCLUDE SYNTAX WITH EVERYTHING)
(INCLUDE NOTES FROM SQL COOKBOOK, Udemy)
Cursors
A query without an ORDERY BY clause returns a set (or multiset), whereas a query with an ORDER BY clause returns a cursor – which is a nonrelational result with a guaranteed among rows.
SQL is a set-based language, meaning operations are completed on all or rows of the result. However, there are times, when we want to do operation on a row by row basis. This is where cursors come in to play.
Cursors in SQL and T-SQL are used to process rows from a result of a query one by one in a requested order. This is different from set-based queries where we manipulate a set or multiset as a whole and does not rely on order.
What a cursor allows us to do create an array list and then iterate over that array list one row at a time. Generally, in T-SQL we want to avoid cursors because there’s generally going to be a better method using set based operations, and SQL Server is geared towards doing those set based operations and it’s also going to perform better. With the introduction of window functions in SQL Server 2012 and their added functionality filled in the void once occupied with cursors before. So, from a performance perspective, there are very few scenarios where cursors may be the ideal option.
When possible we should stick with using set-based queries. Only when we have a compelling reason to do otherwise should be consider using cursors. Use of cursors should be based on several factors, including the following:
- When we use cursors, we’re going against the relational model, which is best on set theory.
- The row-by-row operations of cursors have overhead. There is extra cost associated with each record manipulation by the cursor when compared to set-based manipulation. For similar physical processing behind the scenes, cursor code is usually many times slower than set-based code.
- With cursors, we’re responsible for defining how to process the data (declaring the cursor, opening it, looping through the cursor records, closing the cursor, and deallocating the cursor). With set-based solutions, we write declarative code where we mainly focus on the logical aspects of the solution (ie. what to get instead of how to get it). For this reason, cursors tend to be longer, less readable, and harder to maintain compared to set-based solutions.
In most cases cursors are misused; there are used even when much better set-based solutions exist. An example of an exception is when we need to apply a certain task to each row from a table or view, such as execute some administrative task for each index or table in our database. In such a case, we should use a cursor to iterate through the index or table names one at a time and execute the relevant task for each of those.
Another example where we should use cursors is when our set-based solution performs badly after exhausting our tuning efforts. While set-based solutions generally tend to be much faster, there are some exceptions where a cursor may be a faster solution. An example of this is computing running aggregates in T-SQL on a version of SQL Server that doesn’t support window functions. Set-based solutions to running aggregates using joins or subqueries tend to be extremely slow. For such a case it’s optimal to use an iterative solution such as a cursor.
The type of cursors we can define are broken in two main categories: scrolling capabilities and ability to detect changes made to the database.
There are two main kinds of cursors with scrolling capabilities: FORWARD_ONLY or SCROLL. These two options are mutually exclusive and determine what FETCH commands we can use.
- FORWARD_ONLY – The FORWARD_ONLY cursor starts on the first row and end on the last. The cursor can only move to the next row in the result. In other words, the only FETCH we can use is FETCH NEXT.
- SCROLL – SCROLL allows for backward and forward movement. The cursor can use operations, such as FIRST, LAST, PRIOR, NEXT, RELATIVE, ABSOLUTE to navigate the results.
There are a number of different FETCH operations we can use in cursors (include the list in slide). For the cursor type we can do FORWARD ONLY, FAST FORWARD, STATIC, or SCROLL. When we are writing cursors, we generally use FORWARD ONLY, and so to improve that performance generally we would do FAST FORWARD which means that it’s a read-only operation so we’re improving the speed of that cursor.
Creating a cursor
The general steps when working with a cursor is as follows:
- Declare variables – The T-SQL cursor allows us to store the cursor in a variable through the SET First, we declare the variable as type CURSOR. Next, we use the SET command to assign a cursor to the variable. All of the options are the same as for the DECLARE CURSOR command. We can also use the SET command to set a cursor variable to another cursor variable. Why would we use
this approach? Because we can use a cursor variable as a parameter to a stored procedure. - Declare a cursor based on a query – Cursors can be defined as either read-only or updatable. We use the DECLARE statement to give SQL Server the SELECT statement for which we wish to receive rows.
- Open the cursor – Once we have declared the cursor, we then issue an OPEN command to begin to receive rows. This is the point at which the SELECT defined in the DECLARE statement is executed.
- FETCH – We then fetch attribute values from the first cursor record into variables. To retrieve a row, use the FETCH statement. This retrieves only one row there is no way of retrieving blocks
of rows. The FETCH options are controlled by the DECLARE CURSOR options. In T-SQL cursors, both FORWARD_ONLY and FAST_FORWARD allow only NEXT, for obvious reasons. If we do not use DYNAMIC, FORWARD_ONLY, or FAST_FORWARD, and we specify KEYSET, STATIC, or SCROLL, then we may use all options. Finally, if we do use DYNAMIC, we may use all but ABSOLUTE. The reason for this is that we really do not know where the end of the result set is until we run out of rows. Both the ABSOLUTE and RELATIVE options allow we to use variables, as long as they are SMALLINT, TINYINT, or INT. If we do not specify an INTO clause, then the entire row will be output, as if we did a SELECT of one row. If we do specify an INTO clause, then we must specify a variable for each column in the SELECT. This is the most common usage. - As long as we haven’t reached the end of a cursor, we look through the cursor records, and in each iteration of the loop perform the needed processing for the current row, and then fetch the attribute values from the next row into the variables. The function @@FETCH_STATUS determines the success or failure of the most recent FETCH. It canassume three values: 0, 1, and 2. These correspond to Success, Failure, and Missing Row. A row would be missing if it was deleted by the time, we went to fetch it.We have to use the @@FETCH_STATUS function to determine when to exit from our FETCH loop. Becareful @@FETCH_STATUS gives we the status of the last FETCH, regardless of the number of cursors we currently have open.Another function is very useful when we are using cursors @@CURSOR_ROWS. SQL Server has the capability of populating large static and keyset cursors asynchronously. This function can tell we whether allof the qualifying rows have been retrieved and how many rows are currently in the cursor. If the number is positive, then the cursor is fully populated. If it is negative, then the cursor is being asynchronously populated and some, but not all, qualifying rows have been retrieved. If the number is zero, then no rows qualify or therei s no open cursor. Beware! The variable refers to the last opened cursor, so if we have nested cursors,wecan run into trouble.If we use a stored procedure to create a cursor and then pass the cursor (through a variable) back to a calling procedure, we will find the CURSOR_STATUS() function quite useful. UPDATEs and DELETEs are optional, and it obviously depends on whether or not we wish to update or delete from the underlying table. We can use the WHERE CURRENT OF clause to tell SQL Server which particular row we wish to update or delete. The update or delete always occurs on the row we last fetched for that particular cursor.
- Close the cursor – The CLOSE statement frees up some of the cursor’s resources, such as the result set and the lock that it has on the last row we fetched. If we reissue the OPEN statement, we can again have access to the cursor’s The CLOSE statement does not free the cursor itself. This means that we cannot create another cursor with the same name until we use the DEALLOCATE statement.
- Deallocate the cursor – Once we have finished with a cursor, we need to free up its resources. This is done through the DEALLOCATE statement
Set of commands to use when creating a cursor include: DECLARE, OPEN, FETCH, UPDATE/DELETE, CLOSE, AND DEALLOCATE. Out of the five, only UPDATE/DELETE command is optional.
The reason we may need to use a database cursor is that we need to perform actions on individual rows. Consider the following update statement:
UPDATE Sales.SalesPerson SET City = 'Saline' WHERE SalesPersonID < 10031
The code updates every row in the table Sales.SalesPerson where the SalesPersonID is less than 10031. If, during the update operation, there is an error, then no rows are updated. The entire update is treated as a transaction.
Now by using a cursor, we can iterate or move from one row to the next and updating rows as we go. If we encounter an error, try something else, or skip the operation. The difference is, that when we use cursors, we can act on each row. Also, if the cursor is defined as SCROLLABLE, we can even move back to the previous row. The following code serves as an example:
DECLARE @businessEntityID AS INT;
DECLARE @firstName AS NVARCHAR(50), @lastName AS NVARCHAR(50);
DECLARE @personCursor AS CURSOR;
SET @personCursor = CURSOR
FOR SELECT BusinessEntityID,
FirstName,
LastName
FROM Person.Person;
OPEN @personCursor;
FETCH NEXT FROM @personCursor INTO @businessEntityID, @firstName, @lastName;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT CAST(@BusinessEntityID AS VARCHAR(50))+' - '+@firstName+' '+@lastName;
FETCH NEXT FROM @personCursor INTO @businessEntityID, @firstName, @lastName;
END;
CLOSE @personCursor;
DEALLOCATE @personCursor;
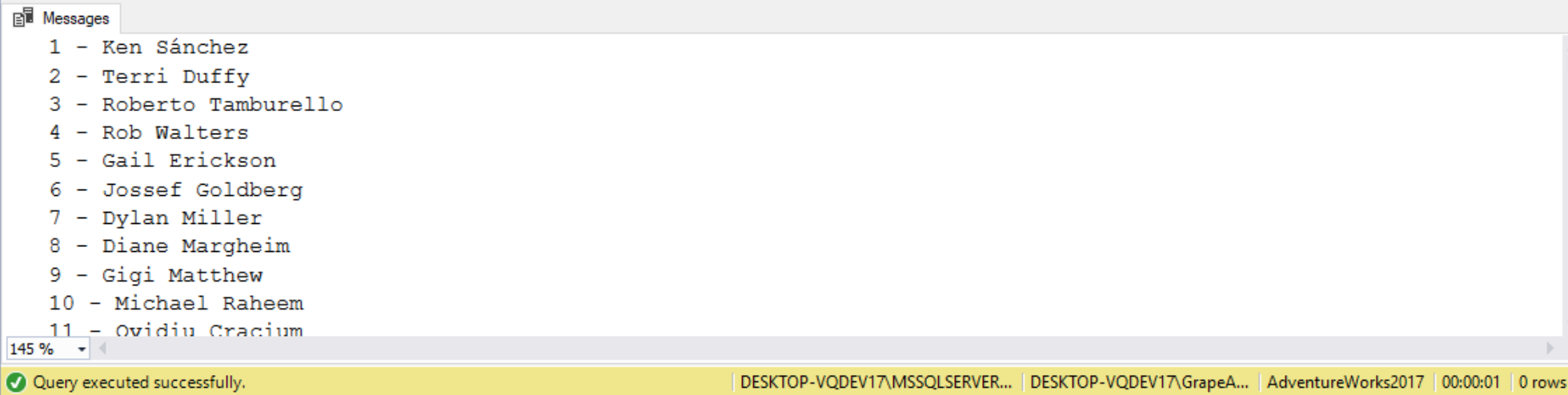
Notice that we used the PRINT statement. This is a handy statement. It will send output to the SQL Server Management Studio Message Window! This make is a good tool for general debugging and playing around with stored procedures.
For example, the following cursor code calculates the running total quantity for each customer and month from the Sales.CustOrders view:
(Include code from page 392)
The code declares a cursor based on a query that returns the rows from the CustOrders view which are ordered by customer ID and order month, and iterates through row-by-row. The current running total is tracked in a variable called @runqty, which is reset every time a new customer is found. The code calculates for each row the current running total by adding the current month’s quantity (@qty) to @runqty, and it inserts a row with customer ID, order month, current month’s quantity, and running quantity into a table called @Result. After all the cursor records are processed, the code queries the table variable to present the running aggregates.
Note that T-SQL supports window functions as an elegant and highly efficient alternative to running aggregate calculations, freeing us from needing to use cursors. The same task done by the above cursor code can be done with a window function, as follows:
(Include code, explanation, and results from page 394)
Cursor Sensitivity
When we talk about data sensitivity we mean what happens when the same row is changed by someone else? Is that change seen in the result of the cursor?
- STATIC – This is the least sensitive cursor. Any changes made aren’t reflected in the cursor’s results. Also, any change made to the cursor’s data, aren’t permanent. They aren’t stored to the underlying database tables. In other words, SQL Server saves the rows in a worktable in tempdb, and the locks are freed from the original tables. Any modifications made to the base tables will not be reflected in any FETCH – it is effectively a snapshot of our SELECT. Needless to say, we cannot update through such a cursor. Since this worktable must be populated before we can use it, there may be a delay before we can retrieve our first row.
- KEYSET – A keyset cursor can see changes made to rows that are originally in to cursor, since these rows unique identifiers (keys) are used to fetch rows during cursor operations. A keyset cursor cannot see rows added to the table. The KEYSET option creates a worktable in tempdb of keys based upon our SELECT. The membership and order of the rows remain fixed. Any changes to non-key attributes, either by the cursor owner or by other connections will be reflected in the cursor. Inserts made by other connections are not reflected in the cursor. Any attempt to fetch a row deleted from outside will result in a @@FETCH_STATUS of-2. The effects of updates of key values from outside are very important but can be difficult to troubleshoot because an UPDATE is treated as a DELETE followed by an INSERT. As mentioned, any deletion from outside (even if caused by an UPDATE) will cause a @@FETCH_STATUS of-2. However, updates done via the WHERE CURRENT OF clause of the cursor are
- DYNAMIC – The DYNAMIC option is more sensitive than the STATIC and KEYSET options. This option will reflect all changes in the underlying tables. The data values, membership, and order of the rows can change on each We cannot use a FETCH ABSOLUTE with this option. Here, changes made are reflected in the cursors. Likewise, changes made within the cursor are made to the underlying database.
- FAST_FORWARD – The FAST_FORWARD option is a combination of the FORWARD_ONLY and READ_ONLY options, but itis optimized for performance. It cannot be used with the FORWARD_ONLY, SCROLL, or FOR UPDATE
- READ_ONLY – A READ_ONLY cursor is a cursor that cannot be used for updates or deletes.
- SCROLL_LOCKS – The SCROLL_LOCKS option places locks on the rows as they are fetched so that an update made to themthrough the cursor will be guaranteed to succeed. This option cannot be used with FAST_FORWARD.
- OPTIMISTIC – The OPTIMISTIC option refers to optimistic locking. If we go to update the table, and the row has changedsince we fetched it, we will get error 16934: “Optimistic concurrency check failed. The row was modifiedoutside of this cursor.” Although SQL Server supports concurrency via both optimistic with row versioningand optimistic with values, the Books Online claim that Transact-SQL cursors support only row versioning,
which would mean that we would need a timestamp column on the underlying table being updated. However, a simple experiment with and without a timestamp showed that both cases worked. This option cannot be used in conjunction with FAST_FORWARD.
For T-SQL cursors, if we do not specify the READ_ONLY, OPTIMISTIC, or SCROLL_LOCKS options, then the default behavior is controlled as follows. If the SELECT does not support updates (for example, if it uses aggregates), it becomes READ_ONLY. Both STATIC and FAST_FORWARD default to READ_ONLY, which makes intuitive sense. Finally, DYNAMIC and KEYSET default to OPTIMISTIC. If we want no surprises, declare all of our options explicitly. During development, it’s a good idea to use sp_describe_cursor in our code to determine whether the cursor is behaving as predicted.
The following code creates the table for our next demo:
USE tempdb;
GO
CREATE TABLE State
(StateName VARCHAR(50),
StateAbbr CHAR(2));
INSERT INTO dbo.State
VALUES
('Washington','WA'),
('Oregon','OR'),
('Idaho','ID'),
('Alaska','AK');
SELECT * FROM dbo.State;

To define and use a read-only cursor we will use the code below:
USE tempdb;
GO
SET NOCOUNT ON;
USE tempdb;
GO
SET NOCOUNT ON;
DECLARE state_cursor CURSOR READ_ONLY
FOR SELECT StateName,
StateAbbr
FROM dbo.State
ORDER BY StateName;
-- Variables to hold results from cursor
DECLARE @StateName VARCHAR(50);
DECLARE @StateAbbr CHAR(2);
OPEN state_cursor;
-- Get the first state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
-- Process while state found
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'The abbreviation for the state of '+@StateName+' is '+@StateAbbr;
-- Get the next state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
END;
-- Clean Up
CLOSE state_cursor;
DEALLOCATE state_cursor;

We first declared a couple of variables to hold data read from the cursor. Then WE declared a cursor named state_cursor. With the DECLARE CURSOR statement WE defined my SELECT statement which identifies the list of columns, and the criteria that will be used to populate the state_cursor. In this example we’re populating my cursor with all the rows in the State table in the order of the StateName. Because WE used the READ_ONLY option on my DECLARE CURSOR statement my cursor will be a read-only cursor. Before WE can use the data in the cursor we defined we must first open it. WE do this with the OPEN statement. To return rows from my cursor WE use the FETCH statement. On the FETCH statement WE specified the NEXT option. The first time WE use the FETCH NEXT statement after declaring a cursor will fetch the first row of my cursor. After WE have fetched the first row all subsequent execution of the FETCH NEXT statement will return the next row in the cursor. On the FETCH statement WE also have identify which local variables will be populated for each column in my cursor. In my example WE populate @StateName, and @StateAbbr.
After the first FETCH statement WE check the status returned by this statement by using the @@FETCH_STATUS function. The @@FETCH_STATUS function returns the status of last cursor FETCH statement. This function may return 0, -1, or -2 values depending on the status of the last FETCH statement. If the return value is 0 this means that the last execution of the cursor FETCH statement successfully returned a row. If the return value is -1 this means the last FETCH statement either failed, or there are no more rows to fetch from the cursor. If the return value is -2 means the row being returned is missing. WE use the value of the @@FETCH_STATUS function for the WHILE loop condition, so WE can loop through the cursor until all rows have been fetched. If my last FETCH statement was successful, then my code enters the WHILE loop. In that loop WE first execute a PRINT statement that displays the @StateName and @StateAbbr column values. The last statement in the WHILE loop reads the next cursor row using the FETCH NEXT statement. The WHILE loop will continue processing rows in the cursor until there are no more rows to fetch. When the FETCH statement in the WHILE loop detects there are no rows left it will set the @@FETCH_STATUS to a -1 value. When this happens the WHILE loop ends.
More example use-cases for Cursors
Cursors can be used to calculate median values. Although SQL can give we such statistical functions as MIN(), MAX(), and AVG(), it does not have a
median function. Calculation of the median is actually straightforward in SQL when we use a scroll cursor. Scroll cursors let we use FETCH FIRST, FETCH LAST, FETCH RELATIVE, FETCH PRIOR, and FETCH ABSOLUTE to locate particular rows. If we fetch the last row, then we know that we have populated the result set. This means that @@CURSOR_ROWS will contain the total number of rows. The halfway point is the median. If @@CURSOR_ROWS is odd, add 1 to @@CURSOR_ROWS and then divide by 2. This ensures that we get the actual value that splits the result set in two. Now, pick up the median value by doing a FETCH ABSOLUTE. If, however, @@CURSOR_ROWS is even, then there is no row corresponding to the median. In this case, we have to calculate the median. This requires two fetches. First, we have to pick up the value corresponding to the row at @@CURSOR_ROWS / 2. Next, we pick up the value for the following row. Average the two and we have the median. Be careful if we are using integers we can lose accuracy unless we convert to float. For example, suppose we want to know the median value of the total quantity of products ordered per order from the Sales.SalesOrderDetail table. We set up a scroll cursor that selects the total quantity for each order, and we sort according to quantity. We then make the appropriate fetches to calculate the median. Don’t forget that the entire SELECT must be carried out, even though we are making at most three fetches. The code for querying the median order quantity is as follows:
DECLARE @Quantity INT, @Quantity2 INT, @Median INT, @Row INT;
DECLARE c SCROLL CURSOR
FOR SELECT SUM(OrderQty)
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
ORDER BY SUM(OrderQty);
OPEN c;
FETCH LAST FROM c INTO @Quantity;
IF @@CURSOR_ROWS % 2 = 1 --odd number of rows
BEGIN
PRINT 'Odd';
SET @Row = CAST(@@Cursor_Rows + 1 AS INT) / 2;
FETCH ABSOLUTE @Row FROM c INTO @Quantity;
SET @Median = CAST(@Quantity AS FLOAT);
END;
ELSE --even number of rows
BEGIN
PRINT 'Even';
SET @Row = @@CURSOR_ROWS / 2;
FETCH ABSOLUTE @Row FROM c INTO @Quantity;
FETCH NEXT FROM c INTO @Quantity2;
SET @Median = (@Quantity + @Quantity2) / 2.0;
END;
CLOSE c;
DEALLOCATE c;
SELECT Median = @Median;

Cursors in T-SQL are typically used for administrative purposes. The reason cursors are good for administration purposes is because we can think of it from the purpose of saying “we have a list of databases that we need to back up, but we don’t want to back up all those databases at the same time, we want to back them up row-by-row.” So we can use a cursor to get a list of databases that we want to back up, and then we back those up one by one. It does have some similarities as far as resembling the for loop, because we are going to be looping over and processing essentially one row at a time. The reason why cursors get a bad rep in SQL Server is because they are a row by row operation. So if we’re using them to insert or update data or do data manipulation type operations, it’s going to be not the best method we can use, so we really want to avoid cursors in those scenarios. Cursors can be used for things other than administrative purposes, but it’s always a situation where we have a list of objects that we need to iterate over, and it’s a small list and we need to operate that list row by row and not all at the same time.
The following is an example of a cursor being used for administrative purposes:
--Get the database names
USE master;
GO
SELECT Name AS DatabaseName
FROM sysdatabases;
--Filter out system databases and other databases that we won't be backing up
SELECT Name AS DatabaseName
FROM sysdatabases
WHERE Name NOT IN('Master', 'TempDB', 'Model', 'MSDB', 'PWInsurance',);
/* Datebase backup script. Generate backup script from GUI removing excess parameters
Right click AdventureWorks2017-->Task-->Backup. Under Script, select New Window */
BACKUP DATABASE [AdventureWorks2017]
TO DISK = N'H:MoeAhad\TSQL\Databases\AdventureWorks2017.bak';
--Create the variables
--Directory location of backups
DECLARE @path VARCHAR(256)= N'H:MoeAhad\TSQL\Databases';
DECLARE @DatabaseName VARCHAR(50);
DECLARE @QualifiedFileName VARCHAR(256);
--Create a list of databases using a Cursor
--Print database name and file name
DECLARE DatabaseList CURSOR --Cursor data type
--Direction of cursor starting with first row of first database in list
FORWARD_ONLY
FOR SELECT Name AS DatabaseName
FROM sysdatabases
WHERE Name NOT IN('Master', 'TempDB', 'Model', 'MSDB', 'PWInsurance');
OPEN DatabaseList;
FETCH NEXT FROM DatabaseList INTO @DatabaseName;
--Means there's still more data available
WHILE @@FETCH_STATUS = 0
BEGIN
--Location where we save backups
SET @QualifiedFileName = @path+@DatabaseName+'.BAK';
--Print to test the script
PRINT @QualifiedFileName;
--Run Backup Scripts
BACKUP DATABASE @DatabaseName TO DISK = @QualifiedFileName;
PRINT @DatabaseName+' Backed up successfully at '+CONVERT(VARCHAR, GETDATE());
FETCH NEXT FROM DatabaseList INTO @DatabaseName;
END;
CLOSE DatabaseList;
DEALLOCATE DatabaseList;
Here, we’re going to go through a basic example of working with a cursor and using it to essentially set up a backup operation that will iterate over all of our databases and then back them up one by one.
Scope of a Cursor
A cursor can be defined to have one of two different scopes: LOCAL or GLOBAL. The LOCAL and GLOBAL options are mutually exclusive. GLOBAL cursors are available in different batches created using the same connection. The GLOBAL option means that all nest levels of stored procedures can access it. To prevent a real mess, it is suggested to avoid GLOBAL wherever possible. LOCAL cursors are only available in the scope of the batch that defines the cursor. In other words, only the stored procedure that declared the cursor has access to it. If neither the GLOCAL nor LOCAL scope is provided then the default setting for a cursor is based off database “default cursor” setting. To demonstrate using a LOCAL or GLOBAL scope of a cursor let’s look at the code below:
USE tempdb;
GO
SET NOCOUNT ON;
DECLARE state_cursor CURSOR LOCAL READ_ONLY
FOR SELECT StateName,
StateAbbr
FROM dbo.State
ORDER BY StateName;
GO
-- Variables to hold results from cursor
DECLARE @StateName VARCHAR(50);
DECLARE @StateAbbr CHAR(2);
OPEN state_cursor;
-- Get the first state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
-- Process while state found
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'The abbreviation for the state of '+@StateName+' is '+@StateAbbr;
-- Get the next state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
END;
-- Clean Up
CLOSE state_cursor;
DEALLOCATE state_cursor;
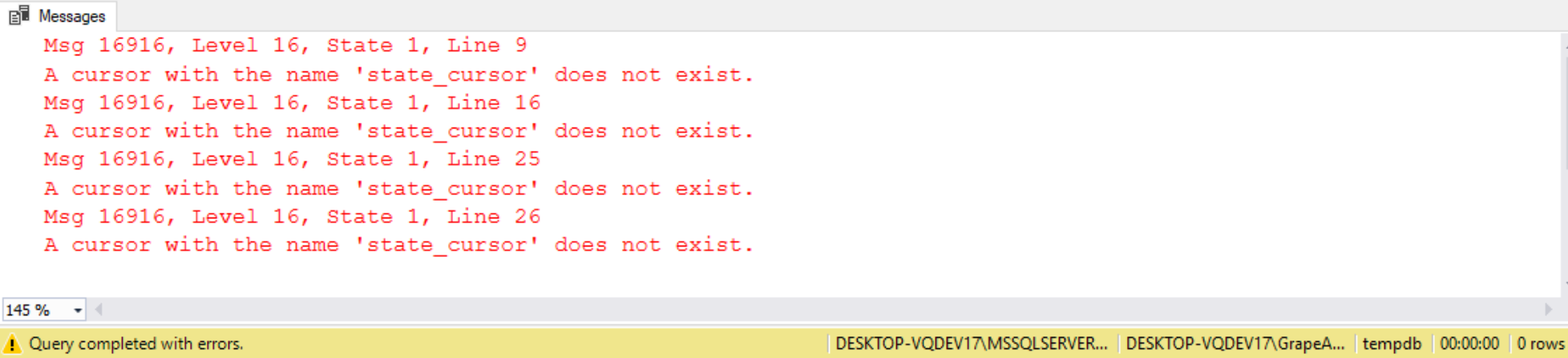
When WE run the code in Listing above it returns multiple errors in the message tab. The code is the same as the previous code, except WE placed the keyword “LOCAL” on the DECLARE CURSOR statement. By doing this WE defined my StateCursor as a local cursor. Additionally, WE broke the code up into two batches by placing a GO separator right after the local cursor is declared. The GO terminates the batch, so the remaining statements in a different batch then the batch that defined the cursor. By doing this the code in Listing 2 returns 4 different ‘cursor does not exist’ messages as shown in Report 2. These messages are produced because the DEFINE CURSOR statement is in a different batch then the other cursor related statements.
In order to make a cursor available in all batches created by a given connection WE could use the GLOBAL , like follows:
USE tempdb;
GO
SET NOCOUNT ON;
DECLARE state_cursor CURSOR GLOBAL READ_ONLY
FOR SELECT StateName,
StateAbbr
FROM dbo.State
ORDER BY StateName;
GO
-- Variables to hold results from cursor
DECLARE @StateName VARCHAR(50);
DECLARE @StateAbbr CHAR(2);
OPEN state_cursor;
-- Get the first state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
-- Process while state found
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT 'The abbreviation for the state of '+@StateName+' is '+@StateAbbr;
-- Get the next state
FETCH NEXT FROM state_cursor INTO @StateName, @StateAbbr;
END;
-- Clean Up
CLOSE state_cursor;
DEALLOCATE state_cursor;

By define our state_cursor as GLOBAL, WE now can run this code without errors. WE’ll leave it up to we to confirm the code in listing 4 runs without errors using a GLOBAL cursor.
Updating columns using a cursor
There might be a time when we want to process through a set of records and based on the valus in record determine whether or not to update or to delete the cursor row. This is where an updateable cursor comes in handy. Suppose WE want to process through my StateTable table and update the StateName and StateCodewhen the StateCode is either a WA, or OR. WE could meet this requirement with my updateable cursor below:
USE tempdb; GO SET NOCOUNT ON; DECLARE state_cursor CURSOR FOR SELECT StateName ,StateAbbr FROM dbo.STATE FOR UPDATE; -- Variables to hold results from cursor DECLARE @StateName VARCHAR(50); DECLARE @StateAbbr CHAR(2); OPEN state_cursor; -- Get the first state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; -- Process while state found WHILE @@FETCH_STATUS = 0 BEGIN -- StateAbbr one that needs updating IF (@StateAbbr = 'WA') UPDATE dbo.STATE SET StateName = 'California' ,StateAbbr = 'CA' WHERE CURRENT OF state_cursor; IF (@StateAbbr = 'OR') UPDATE dbo.STATE SET StateName = 'Arizona' ,StateAbbr = 'AZ' WHERE CURRENT OF state_cursor; -- Get the next state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; END -- Clean Up CLOSE state_cursor; DEALLOCATE state_cursor; -- Display Updated State table SELECT StateName ,StateAbbr FROM dbo.STATE;

The code in Listing 5 creates an updatable cursor. WE defined this cursor to be updateable by adding the FOR UPDATE clause at the end of the DECLARE CURSOR statement. Since the FOR UPDATE clause didn’t identify any column names WE can update any column in the cursor. To update rows, there are two UPDATE statements within the body of the WHILE loop. The first update statement is used to update the StateName to ‘California’ and the StateAbbr to ‘CA’ when the current cursor row being processed has a @StateAbbr value of ‘WA’. The second update statement is to update the StateName to ‘Arizona’ and the StateAbbr to ‘AZ’ when the current cursor row being processed has a @StateAbbr value of ‘OR’. By looking at the output in Report 3 we can see that records for the state of Washington and Oregon have now been replaced with California and Arizona. In order for SQL Server to update a record it needs to be locked first. The code in listing 5 uses optimistic locking. When optimistic locking is used SQL Server needed to validate that the record has not been updated outside the cursor. It does this by comparing the cursor row to the actual table row. If SQL Server finds out that a record has been updated after the record has been read into the cursor it will return the error as shown above.
If we want to guarantee that all updates in a cursor are successful we need to make sure the records are locked when they are read into the cursor. We can accomplish this by using the SCROLL_LOCKS option when defining the cursor, as follows:
USE tempdb; GO SET NOCOUNT ON; DECLARE state_cursor CURSOR SCROLL_LOCKS FOR SELECT StateName ,StateAbbr FROM dbo.STATE FOR UPDATE; -- Variables to hold results from cursor DECLARE @StateName VARCHAR(50); DECLARE @StateAbbr CHAR(2); OPEN state_cursor; -- Get the first state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; -- Process while state found WHILE @@FETCH_STATUS = 0 BEGIN -- StateAbbr one that needs updating IF (@StateAbbr = 'CA') UPDATE dbo.STATE SET StateName = 'Washington' ,StateAbbr = 'WA' WHERE CURRENT OF state_cursor; IF (@StateAbbr = 'AZ') UPDATE dbo.STATE SET StateName = 'Oregon' ,StateAbbr = 'OR' WHERE CURRENT OF state_cursor; -- Get the next state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; END -- Clean Up CLOSE state_cursor; DEALLOCATE state_cursor; -- Display Updated State table SELECT StateName ,StateAbbr FROM dbo.STATE;

The only difference between the two previous queries is that WE added the SCROLL_LOCKS option to the DECLARE CURSOR statement and changed my UPDATE statements to change StateName and StateAbbrback to their original Washington and Oregon values. With the SCROLL_LOCKS option WE can guarantee that all my UPDATE statements in my state_cursor get work without getting the optimistic concurrency check failure, because the rows where locked for update as they were read into the cursor. One thing to consider is the performance impact of using the SCROLL_LOCKS option. This option will lock all the rows in the cursor. Keep in mind that doing this might cause a serious blocking issues, with other connections that might be trying to update the same rows that where loaded into the cursor.
Restricting Which Columns can be Updated Using a Cursor
In the prior section WE showed we examples of cursor definitions that allowed me to update all columns in my State table. If we want to create a cursor that restricts updates to a subset of columns then we can identify the set of columns that are updatable on the DECLARE CURSOR statement, as follows:
USE tempdb; GO SET NOCOUNT ON; DECLARE state_cursor CURSOR FOR SELECT StateName ,StateAbbr FROM dbo.STATE FOR UPDATE OF StateName; -- Variables to hold results from cursor DECLARE @StateName VARCHAR(50); DECLARE @StateAbbr CHAR(2); OPEN state_cursor; -- Get the first state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; -- Process while state found WHILE @@FETCH_STATUS = 0 BEGIN -- StateAbbr one that needs updating IF (@StateAbbr = 'WA') UPDATE dbo.STATE SET StateName = 'California' ,StateAbbr = 'CA' WHERE CURRENT OF state_cursor; IF (@StateAbbr = 'OR') UPDATE dbo.STATE SET StateName = 'Arizona' ,StateAbbr = 'AZ' WHERE CURRENT OF state_cursor; -- Get the next state FETCH NEXT FROM state_cursor INTO @StateName ,@StateAbbr; END -- Clean Up CLOSE state_cursor; DEALLOCATE state_cursor; -- Display Updated State table SELECT StateName ,StateAbbr FROM dbo.STATE;

WE got this error because WE tried to update column StateAbbr when the column was not identified in the FOR UPDATE clause when WE declared my cursor. To resolve this error, WE need to remove the StateAbbr column from the SET clause on my two UPDATE statements in the code above.
How optimistic locking works
Optimistic locking of cursor rows occurs by default when we define an updatable cursor without the SCROLL_LOCKS option. It also occurs when we use the OPTIMISTIC option on an updatable cursor.
Having a cursor with optimistic locking allows others to update rows in the database that are in the cursor while the optimistic cursor is open. But there is a cost associated with optimistic locking. With optimistic locking SQL Server needs to make sure updates made through a cursor do not replace updates that were made by other sessions after a row was loaded into the cursor. To do this SQL Server needs to compare the row being update via the cursor with the row in the database to see if they are different. If they are different then we will get the “Optimistic concurrency failure check” error messages as show in report 4 if our cursor uses optimistic locking.
To compare the rows SQL Server uses one of two methods depending on whether or not the table contains a timestamp column. If the table contains a timestamp column SQL Server is able to compare the timestamp value on the row in the cursor with the timestamp value on the row in the database to determine if the row has been updated since the row was loaded into the cursor. If the table doesn’t have a timestamp column SQL Server has to compare the column values in the cursor with the column values in the database to determine if the underlying table row has been updated since it was loaded into the cursor.
Scrolling Around a Cursor
In my cursor examples so far WE have just shown how to use a cursor to sequentially scroll through a cursor using the FETCH NEXT option. There are other FETCH options that allow we to scroll through a cursor without necessarily going from the beginning to the end. But in order to use the different scroll options WE need to define my cursor so it allows me to use these other FETCH options. The code in Listing 8 shows how to create a cursor that allows me to scroll around and retrieve different cursor rows using different FETCH options.
USE tempdb;
GO
SET NOCOUNT ON;
DECLARE state_cursor CURSOR SCROLL
FOR SELECT StateName,
StateAbbr
FROM dbo.State
ORDER BY StateName;
-- Display list of rows in table
SELECT StateName,
StateAbbr
FROM dbo.State
ORDER BY StateName;
-- Variables to hold results from cursor
DECLARE @StateName VARCHAR(50);
DECLARE @StateAbbr CHAR(2);
OPEN state_cursor;
-- Fetch the last row in the cursor
FETCH LAST FROM state_cursor INTO @StateName, @StateAbbr;
SELECT @StateName,
@StateAbbr;
-- Fetch the row prior to the current row
FETCH PRIOR FROM state_cursor INTO @StateName, @StateAbbr;
SELECT @StateName,
@StateAbbr;
-- Fetch the second row in the cursor
FETCH ABSOLUTE 2 FROM state_cursor INTO @StateName, @StateAbbr;
SELECT @StateName,
@StateAbbr;
-- Fetch the row that is 2 rows after the current row
FETCH RELATIVE 2 FROM state_cursor INTO @StateName, @StateAbbr;
SELECT @StateName,
@StateAbbr;
-- Fetch the row that is 3 rows prior to the current row
FETCH RELATIVE-3 FROM state_cursor INTO @StateName, @StateAbbr;
SELECT @StateName,
@StateAbbr;
-- Clean Up
CLOSE state_cursor;
DEALLOCATE state_cursor;
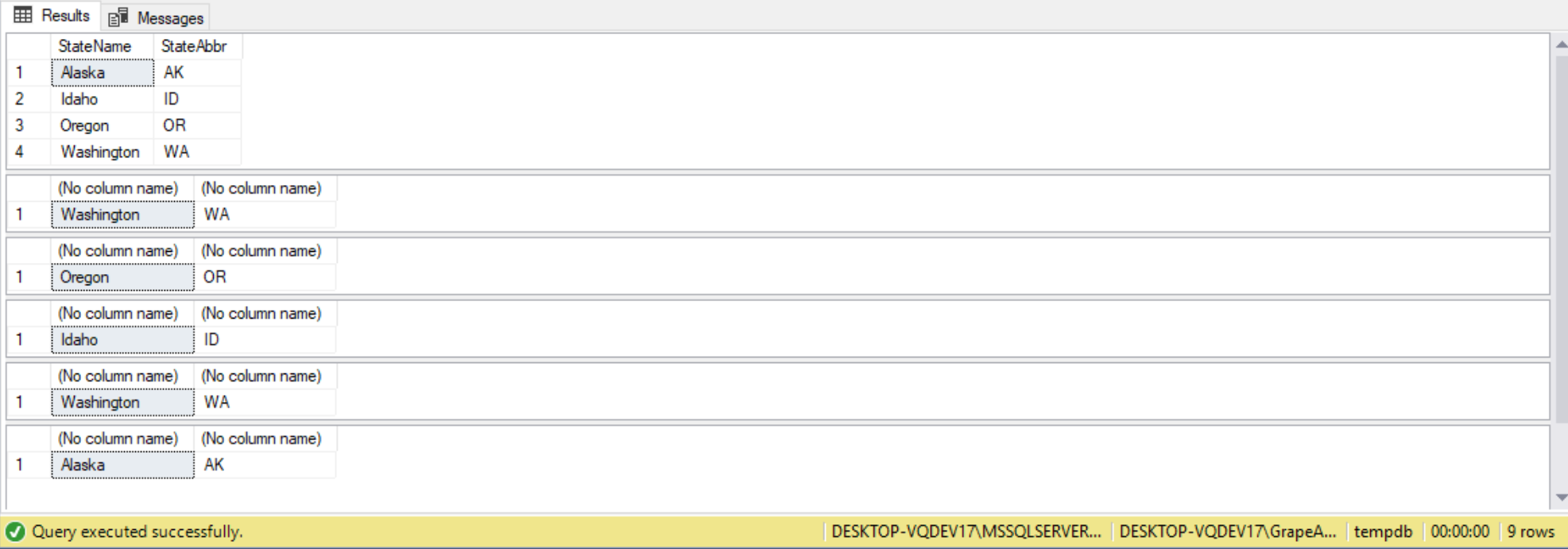
If we review the code in Listing 8 we can see WE used the SCROLL option when defining my cursor. This allows me to use additional FETCH options for scrolling around my cursor. In the code in Listing 8 WE used the following different FETCH options: LAST, PRIOR, ABSOLUTE, and RELATIVE. By looking at the output in Report 6 we can see how WE jumped around in my cursor using these different FETCH options to display different StateName and StateAbbr values.
Performance Considerations and Best Practices
A cursor article wouldn’t be complete unless it talked about performance and best practices around cursors. If our processing requirements can be accomplished with a set based query, then we should not be using a cursor. Cursors use additional CPU, memory and temporary space and are almost always slower than set based solutions. The actual number of times we have to use a cursor should be very small. If we think we need to use a cursor we might consider asking a more seasoned TSQL coder to review our requirements to see if there is a set based solution for our situation. But if we find we do need to process data using a row by row operation provided by a cursor to satisfy our requirements, we should make sure we consider the following:
- Use READ_ONLY cursors when possible. READ_ONLY cursors only apply shared locks on the underlying SQL Server tables thus causing less lock contention.
- When using a cursor to to update a few rows within a large record set considering using the OPTIMISTIC option. Doing this option will cause less blocking contention because rows will not be locked for update when they are read into the cursor. Instead they will be locked when they are updated. One drawback to the optimistic locking is we might get an error if another process changes the underlying row before the cursor process performs an update.
- Make sure the record set declared by the cursor is as small as possible by using an appropriate WHERE clause. The smaller the cursor record set, the less resources used.
- When finished with our cursor remember to CLOSE and DEALLOCATE the cursor. By doing this we release the resources held by the cursor, and give them back to the system.
Because cursors are much slower than set-level SQL, locking becomes an important issue. The SELECT that we specify in our cursor declaration can use locking hints just as it can when a cursor is not involved. Avoid the use of TABLOCKX, REPEATABLEREAD, and HOLDLOCK, particularly inside a transaction. Beyond the regular locking issues just mentioned, there are also those related specifically to cursors. The timing of when locks are actually acquired must be considered. Static cursors will retrieve all of their rows when the cursor is opened. Each row of the result set is then locked at that time. A keyset cursor is similar, but just the keys are retrieved from the result set; the rows are locked in the same manner as for static cursors. DYNAMIC cursors do not retrieve or lock their rows until fetched. The locking behavior of the FORWARD_ONLY cursor varies according to the whims of the optimizer. If it uses a worktable, then the locks will be acquired when we open the cursor; otherwise, they will be acquired when the rows are fetched. Scroll locks are kept until the next row is fetched. Use this with caution.
System-wide options are set by the system stored procedure sp_configure. One of these cursors threshold relates to cursors. Asynchronous population of cursors can be tuned at the server level by setting the cursor threshold value. When we use keyset or static cursors, worktables are created in tempdb, and these can be populated asynchronously. SQL Server looks at the estimated number of rows, and if the number exceeds the cursor threshold, it will start a separate thread to populate the worktable. Control is returned to the calling application, which can start fetching rows before all are available. We will have to monitor @@CURSOR_ROWS to ensure that rows are available and that all rows have been populated. This ruse is efficient only for large numbers of rows, so be careful if we make this number small. Keep in mind, too, that this threshold applies to the entire system. We do not have to stop and restart SQL Server for the new setting to take effect.
There are some cursor-specific, database options of which we should be aware. These settings are set by the ALTER DATABASE command in SQL Server. The Cursor Close on Commit setting, when ON, will close the cursor when a transaction is committed. Otherwise, the cursor is left open. By default, the setting is OFF. We can override the setting for the session by using SET CURSOR_CLOSE_ON_COMMIT ON. The Default to Local Cursor setting, when TRUE, will make all cursors local to the stored procedure, trigger, or batch unless explicitly declared GLOBAL. By default, this setting is FALSE, making all cursors global.