CTEs, Temp Tables, and Derived Tables
What is a Common Table Expression?
- Writing a CTE
- WITH Syntax
- Optional Columns
- Query Definition
- Calling or running the CTE
- Terminate previous statements
- Scope
- Why use a CTE?
- Simplifying queries with a CTE
- Recursive queries
CTEs instead of Derived Tables
- Overwhelming Derived Tables: Cleanup with a CTE
- Performance considerations
- Reducing mistakes
Recursive CTEs
- Syntax
- Anchor query
- Recursive query
- MAXRECURSION
- Bringing it all together
- Advanced Recursion
- Using multiple anchor queries
- Using multiple recursive queries
Hierarchal CTEs
- Hierarchal Tree Path
- Hierarchal Formatting
- Hierarchy in multiple recursive Queries
Multiple CTEs in a Query
- Adding a second CTE
- Nesting CTEs
- How many levels of nesting?
- Additional breakdown of derived tables
- Theoretical example
Data Paging with CTEs
- Data paging CTE
- OFFSET and FETCH
Manipulating Data with CTEs
- Deleting data
- Deleting with multiple base tables
- Inserting data
- Updating data
- Multiple base tables
- Update with no base tables
CTEs in Functions, Stored Procedures, and Views
- Table Valued Functions
- Scalar Functions
- Stored Procedures
- Views
Common Use Cases for CTEs
- Finding holes in patterns
- CTE as an alternative to the Numbers Table
- Dates of the Year (More holes)
- Finding and removing duplicates
- String parsing with CTEs
- Recursive string parsing
- Parsing a query string into a table
CTE Performance Considerations
- Performance Overview
- Actual Execution Plan
- Statistics IO
- Statistics Time
- Non-recursive Performance
- Multiple references to a single CTE in a query
- CTEs vs. Derived Tables
- CTEs vs. Views
- Multiple CTEs in a query
- Nested CTEs
- Recursive performance
- Deep recursion performance
- CTE Data Paging performance vs OFFSET-FETCH
- Other miscellaneous notes on CTE performance
Classic Recursive Algorithms
- Fibonacci
- The Anchor Query
- Recursion
- Data Type Overflow
- The Output
- Factorial
- The Anchor Query
- Recursion
- Overflow
What is a Common Table Expression?
A Common Temporary Expression (CTE) is a temporary named result set that can be used within a single query. The CTE can group a query into a named expression that can then be queried similarly to how we would query a view or temp table. Unlike a temp table, there is no storage associated with a CTE, other than that what is needed to run the current query. In other words, CTEs are not written to disk and do not need to be de-allocated once executed. Unlike a view, the life time of a CTE is constrained to the run time of a single query.
All versions and variations of SQL Server since 2005 support the use of CTEs, including SQL Azure.
Writing a CTE
WITH syntax
CTEs always start with the WITH keyword. Immediately after the WITH keyword will be the name of the CTE. Often times we use “CTE” as a prefix or suffix when naming a CTE, which is helpful as it avoids conflicts or confusion between a CTE and actual table names or view names.
Optional Columns
After initiating a CTE with the WITH keyword and specifying a name for the CTE, the next step in the CTE syntax is optional column declarations. While this step is optional, it is useful in explicitly showing what the CTE is going to return. If the CTE returns a different number of columns as compared to the column declaration, then an error will be thrown. If three columns are specified in the CTE query, but the three columns are in a different order, there won’t be an error – the resulting data will just end up with the wrong column name.
We don’t need to use different names to have the column list as part of the definition. We could be explicit and still use the original names as seen in the following query:
WITH personCTE(BusinessEntityID,
FirstName,
LastName)
AS (SELECT BusinessEntityID,
FirstName,
LastName
FROM Person.Person)
Query Definition
The next step in the CTE syntax is the query definition of the CTE. The query definition starts with the AS keyword and has a query enclosed in parentheses.
The CTE query definition must be a SELECT statement. We cannot use INSERT, UPDATE, or DELETE statements. CTEs can be used with INSERT, UPDATE, and DELETE, but they cannot be inside the CTE query definition.
Calling or Executing the CTE
A CTE is executed by referencing it in a query. Following the closing parentheses of the CTE query definition, we start another SELECT statement that references the CTE by name:
WITH personCTE(BusinessEntityID,
FirstName,
LastName)
AS (SELECT BusinessEntityID,
FirstName,
LastName
FROM Person.Person)
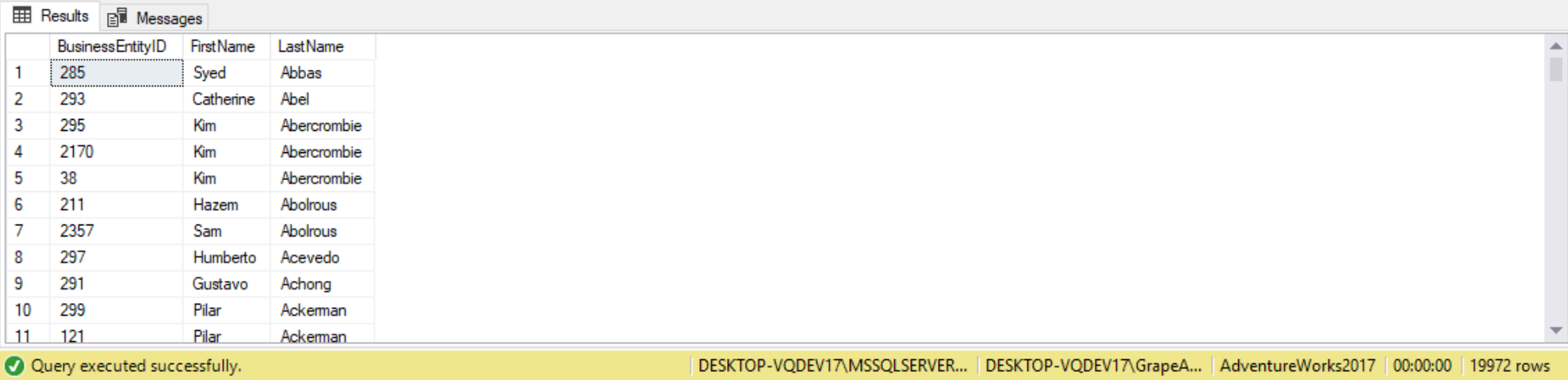
SELECT * FROM personCTE;
Terminate Previous Statements
When using CTEs in T-SQL batches with multiple statements, the preceding batch MUST be terminated with a semi-colon because otherwise we will get an error message.
An alternative to using the semi-colon would be to use the GO statement. SSMS uses the GO statement to break the query into different batches, and is similar to using a semi-colon. Note that the GO statement cannot be inside a stored procedure or function.
In order to avoid syntax error from the query above, it is good practice to start a CTE with a semi-colon as show here:
;WITH personCTE(BusinessEntityID,
FirstName,
LastName)
AS (SELECT BusinessEntityID,
FirstName,
LastName
FROM Person.Person)
SELECT * FROM personCTE;
By simply adding a semi-colon before the WITH keyword to terminate any previous statement, we get two results sets in the Results window as was intended by the original query.
Scope
Once a CTE is defined it can be referenced several times in the same T-SQL statement (for example, in a self-join where the query calls the CTE twice). The scope of the CTE is confined to a single T-SQL statement. In other words, the scope of a CTE is constrained to a single query.
In the following query, the last query in the code block (WHERE id =2) will not run since the CTE scope ended with the first query. The last SELECT statement can’t access the CTE as the earlier SELECT statement did.
WITH personCTE
AS (SELECT BusinessEntityID,
FirstName,
LastName
FROM Person.Person)
SELECT * FROM personCTE Where BusinessEntityID = 101;
SELECT * FROM personCTE Where BusinessEntityID = 285;

One CTE can call another CTE, but even here the scope of the CTE is just a single statement. If the results of the CTE need to be kept around beyond the scope of that single call, we can insert the results into a table, temp table or table variable to be used once the CTE query terminates.
When the previous query is run the results window will show the results of the first SELECT statement, but the message window will show the error message thrown by the second SELECT statement attempting to access a CTE outside of its scope.
Why use a CTE?
The two main reasons to use CTEs are to 1.) simplify complex queries and 2.) be able to create recursive queries.
Simplifying Queries with a CTE:
For readability, having a whole lot of repeating code in a huge query is not as clean as it could be. One way around this is to use a view in place of a derived table reference in big queries. This may not be optimal since we may need additional permissions on the database to create a view. Also, the view ends up hiding the query that we are using and is often overlooked when debugging a problem. CTEs help secure databases by allowing users with read access to create complex queries without the need to higher level of permissions.
While a two table JOIN is a relatively simple query, the following query shows how complicated it looks when one of the tables is a derived table, as compared to using a CTE:
--Query 1: Join with Derived Table
SELECT c.CustomerID,
c.AccountNumber,
soh.OrderDate
FROM
(
SELECT *
FROM Sales.SalesOrderHeader
WHERE OrderDate >= '2013-05-20'
) AS soh
INNER JOIN Sales.Customer AS c ON soh.CustomerID = c.CustomerID;
--Query 2: Join with CTE
WITH soh
AS (SELECT *
FROM Sales.SalesOrderHeader
WHERE OrderDate >= '2013-05-20')
SELECT c.CustomerID,
c.AccountNumber,
soh.OrderDate
FROM Sales.Customer AS c
INNER JOIN soh ON c.CustomerID = soh.CustomerID;
When we simplify our code using a CTE rather than a derived table, both queries will typically perform the same. So while there is no noticeable increase in performance when using a CTE over a derived table, our code is easier to read and maintain.
Recursive Queries
Without CTEs, one of the common ways to build hierarchies is to write a derived table for each level of the hierarchy. We then use a UNION ALL to merge all the queries into one result set. This is a great solution with two or three levels of hierarchies, but this solution falls apart when we need to go to an unknown depth. A CTE allows us to write recursive queries that permit some things that otherwise would be challenging to do in a single query.
CTEs instead of Derived Tables
Without a CTE, we could eventually end up writing a huge query that is a copy and paste of derived tables, and over time that copy and paste may lead to confusion, errors, and problems in the query. A CTE query reduces these issues by consolidating those queries into a Common Table Expression rather than using derived tables that are a copy and paste nightmare.
Typically, when compared to derived tables, CTE solutions reduce the overall size of a query, make the code easier to understand, and eliminate duplicate derived table instances that are prone to errors.
The following is an example of a big query that is converted to a smaller, more understandable query with the use of CTEs. The original query uses derived tables to create 20 lines of T-SQL code and has a typo in the third derived table where “Orlando” is missing the “n”. The two queries are intended to produce the same output, and would if it wasn’t for that typo:
--Employee, their boss, and their boss's boss: non-CTE method
USE Northwind;
SELECT q1.EmployeeID,
q2.EmployeeID AS [My Boss],
q3.EmployeeID AS [Higher Boss]
FROM
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlando'
) AS q1
LEFT JOIN
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlando'
) AS q2 ON q1.EmployeeID = q2.ReportsTo
LEFT JOIN
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlado'
) AS q3 ON q2.EmployeeID = q3.ReportsTo
WHERE q3.ReportsTo IS NOT NULL;
Now if we convert the derived table into a CTE, and fix the typo in “Orlado”, it now takes only 12 lines of T-SQL code to achieve the same result set as the original query that utilized derived tables:
--Employee, their boss, and their boss's boss: CTE method
WITH ManagerCTE(EmployeeID,
City,
ReportsTo)
AS (SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE City != 'Miami'
AND City != 'Orlando')
SELECT q1.EmployeeID,
q2.EmployeeID AS [My Boss],
q3.EmployeeID AS [Boss's Boss]
FROM ManagerCTE AS q1
LEFT JOIN ManagerCTE AS q2 ON q1.EmployeeID = q2.ReportsTo
LEFT JOIN ManagerCTE AS q3 ON q2.EmployeeID = q3.ReportsTo
WHERE q3.ReportsTo IS NOT NULL;
In the CTE version we are quickly able to identify the misspelling in “Orlado” simply by looking at it in one place, instead of reviewing the same code at multiple places where the same derived table is used. There’s only 12 lines of code, and the left joins are cleaner and more obvious in what they’re doing by not being spread over six lines each. The purpose of replacing a derived table with a CTE query is to improve the readability and maintainability of the T-SQL code. Both queries when correct return the following result set:

Overwhelming Derived Tables: Cleanup with a CTE
The steps to convert a derived table into a CTE are as follows:
- Find the first occurrence of the derived table query intended to be broken out. Create a name for it and add “CTE” to the name. Copy the derived table, including the parentheses, and leave the name as the placeholder.
- Paste the query copied earlier into the SELECT statement.
- At the top of the query, add the CTE declaration using the same name from Step 1.
- Find all other occurrences of the same derived table query and replace them with the CTE name.
- (Optional). Clean up the formatting and indenting of the query (if necessary).
Once formatted, we can move on to testing the CTE. It is common to start testing by running the original query and comparing the results to the CTE just created. Depending on the CTE, more extensive testing may be needed, but generally if the steps were followed correctly, we will get the same results as the original query.
When going through the process of converting derived table queries into CTEs, we should keep in mind the CTE is simply not a replacement for every derived table. There are many places where a derived table is still a better option than a CTE. There are even many cases where a CTE query will include derived tables. A good check is to ask the question of which is more complex – the CTE version of the query or the derived table version of the query.
Performance Considerations
One of the common misconceptions around CTEs is that they are a shared result set that gets run only once, even if it is referenced multiple times. For a CTE that is referenced multiple times (like a self-join) the CTE query is not reused, it is executed multiple times.
--Employee, their boss, and their boss's boss: non-CTE method
USE Northwind;
SELECT q1.EmployeeID,
q2.EmployeeID AS [My Boss],
q3.EmployeeID AS [Higher Boss]
FROM
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlando'
) AS q1
LEFT JOIN
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlando'
) AS q2 ON q1.EmployeeID = q2.ReportsTo
LEFT JOIN
(
SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE city != 'Miami'
AND city != 'Orlando'
) AS q3 ON q2.EmployeeID = q3.ReportsTo
WHERE q3.ReportsTo IS NOT NULL;
--Employee, their boss, and their boss's boss: CTE method
WITH ManagerCTE(EmployeeID,
City,
ReportsTo)
AS (SELECT EmployeeID,
City,
ReportsTo
FROM Employees
WHERE City != 'Miami'
AND City != 'Orlando')
SELECT q1.EmployeeID,
q2.EmployeeID AS [My Boss],
q3.EmployeeID AS [Higher Boss]
FROM ManagerCTE AS q1
LEFT JOIN ManagerCTE AS q2 ON q1.EmployeeID = q2.ReportsTo
LEFT JOIN ManagerCTE AS q3 ON q2.EmployeeID = q3.ReportsTo
WHERE q3.ReportsTo IS NOT NULL;
The departmentsCTE CTE is referenced twice. This is considered a self-join because the query is joining the same table twice. Here, the inside CTE query shown will be run twice.
As proof, we can check the actual execution plan when running the query. It produces the following plan that shows the query against the Departments table is being run twice and is causing a table scan to be run twice:
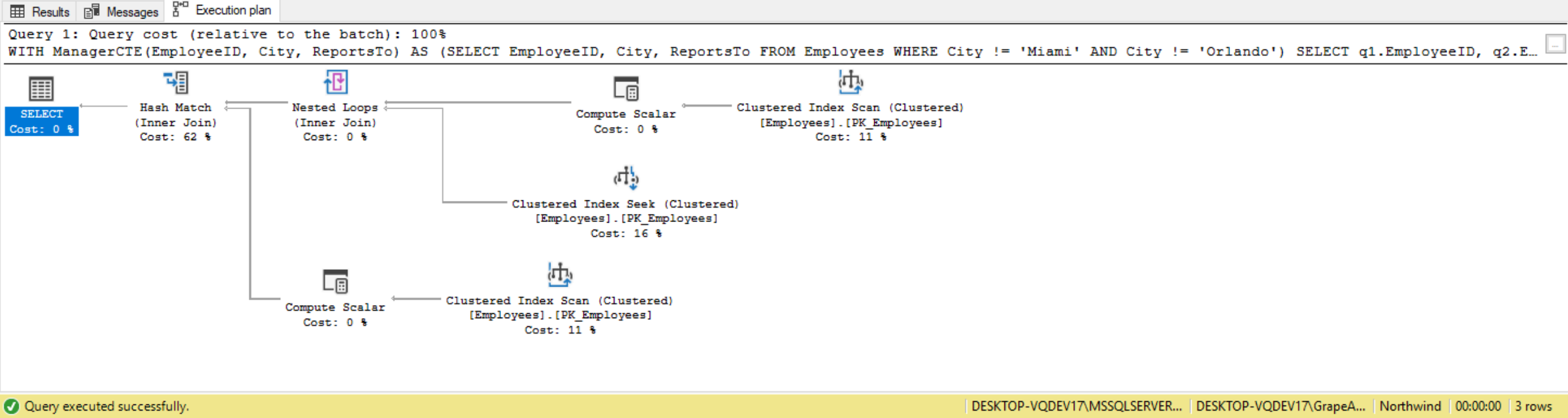
Normally we also want to investigate why it is causing a table scan, instead of an index seek or index scan. In this scenario we are getting the table scan because of the size of the table, the lack of indexes, and the lack of any filtering when selecting from the Departments table.
In this example that uses a small table, it is not much of a performance issue. However, if the CTE query was larger and slower, or more load intensive, then multiple references to the same CTE query could have some very significant performance impacts.
The main thing to consider, relating to performance when converting a derived table over to a CTE, is that the performance shouldn’t change at all. What was slow as a derived table will still be slow as a CTE. Likewise, what was fast will still be fast.
To run the original derived table query (including the actual execution plan) it will be the same as the CTE version we just looked at:
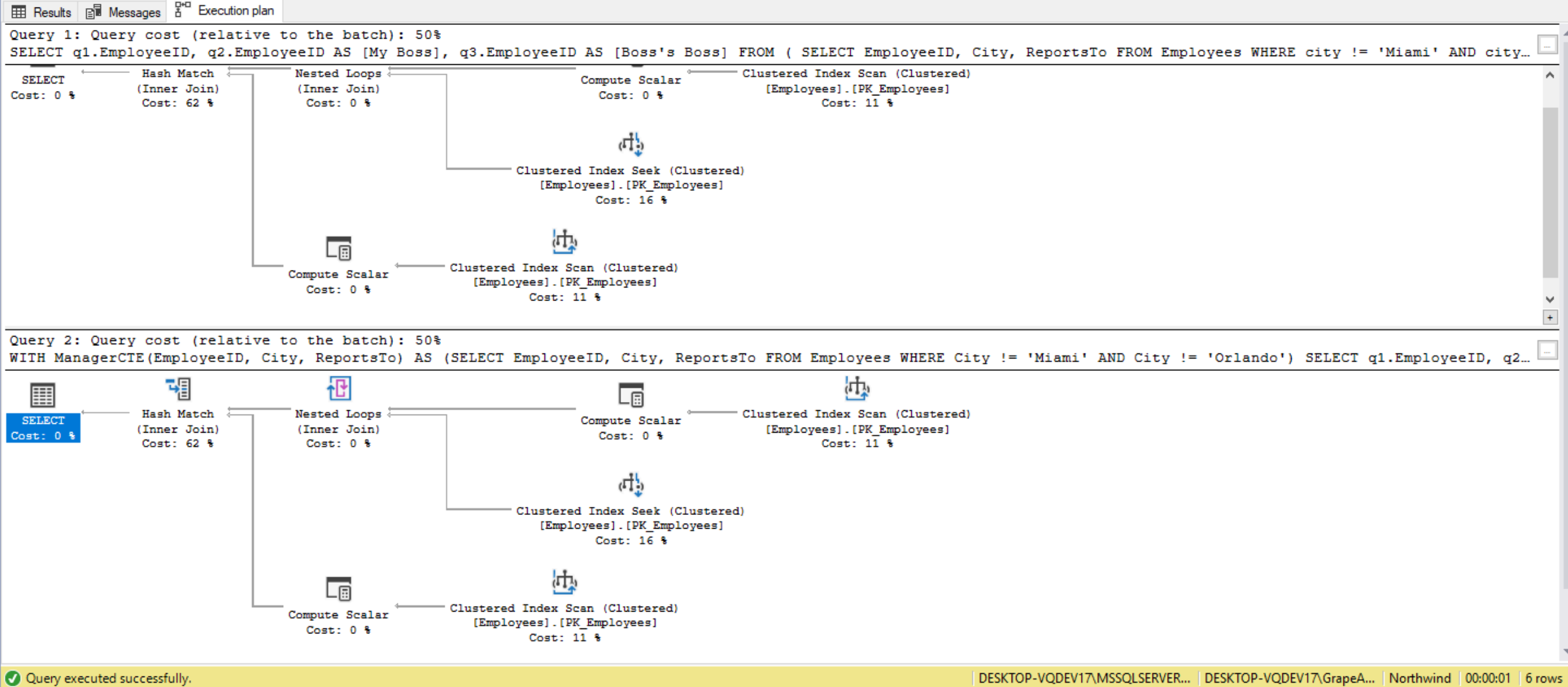
With recursive CTEs there are some major performance increases to be seen. For the conversion of derived tables to CTEs the main purpose is maintainability, readability, and reducing mistakes, not performance change.
Recursive CTEs
Syntax
Recursion is one of the more useful reasons to use CTEs. The recursion is accomplished by specifying an anchor query to start the recursive process, and a recursive query that builds on the data from the anchor. A CTE is considered recursive when the query inside the CTE references the CTE itself.
The main difference from the standard CTE syntax to make the CTE recursive is the use of the UNION ALL set operator to join the starting query (anchor query) with a second query (recursive query) that calls the CTE itself.
Anchor Query
The anchor query is the part of the CTE that starts off the recursive process. This is the set of data that will be passed into the recursive section. The anchor query can be written independent of the CTE, and when completed, added into the CTE.
The recursive query builds on the anchor query, so it’s important to have the anchor query functioning correctly before moving on to the recursive query.
Here, the anchor query has two columns as output. The first column is called CountNumber and is used to keep track of the number of levels through the recursion, and the second column called GrandTotal will be used to build up the total of all the numbers as the query is called recursively.
The anchor query is then placed into a CTE, which when run produces the same result output as the anchor query did alone. This does however need to be in the CTE in order to get to the recursive step. The following is an example of an anchor query that will serve as the starting point for the recursive CTE
WITH cte_BOM (ProductID, Name, Color, Quantity, ProductLevel, ProductAssemblyID, Sort)
AS (SELECT P.ProductID,
CAST (P.Name AS VARCHAR (100)),
P.Color,
CAST (1 AS DECIMAL (8, 2)),
1,
NULL,
CAST (P.Name AS VARCHAR (100))
FROM Production.Product AS P
INNER JOIN
Production.BillOfMaterials AS BOM
ON BOM.ComponentID = P.ProductID
AND BOM.ProductAssemblyID IS NULL
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
Recursive Query
We build the recursive query by adding the anchor query to our CTE. The recursive query allows the CTE to reference itself. Note that the column data types of the recursive query in the CTE must match the data types of the columns in the anchor query. The recursive query will be called for each result the CTE generates. For the first record of the CTE, the anchor query sets the count number to 1 and the grand total to 1. To calculate sum of parts for 2 we need to add 1 to the count number, then add that value to the grand total, which returns 3 as the sum of parts for 2. The query would go as follows:
SELECT P.ProductID,
CAST (REPLICATE('|---', cte_BOM.ProductLevel) + P.Name AS VARCHAR (100)),
P.Color,
BOM.PerAssemblyQty,
cte_BOM.ProductLevel + 1,
cte_BOM.ProductID,
CAST (cte_BOM.Sort + '\' + p.Name AS VARCHAR (100))
FROM cte_BOM
INNER JOIN Production.BillOfMaterials AS BOM
ON BOM.ProductAssemblyID = cte_BOM.ProductID
INNER JOIN Production.Product AS P
ON BOM.ComponentID = P.ProductID
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
)
The existing CountNumber and GrandTotal records come from the existing CTE, if the CTE is referenced recursively in the FROM clause.
We then add a UNION ALL statement into the existing CTE and add the recursive part of the query. We also specify a termination point in the WHERE clause to limit how many times the recursion occurs. In this example, we specify a limit of 10 in order to calculate the sum of parts for 10.
WITH cte_BOM (ProductID, Name, Color, Quantity, ProductLevel, ProductAssemblyID, Sort)
AS (SELECT P.ProductID,
CAST (P.Name AS VARCHAR (100)),
P.Color,
CAST (1 AS DECIMAL (8, 2)),
1,
NULL,
CAST (P.Name AS VARCHAR (100))
FROM Production.Product AS P
INNER JOIN
Production.BillOfMaterials AS BOM
ON BOM.ComponentID = P.ProductID
AND BOM.ProductAssemblyID IS NULL
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
UNION ALL
SELECT P.ProductID,
CAST (REPLICATE('|---', cte_BOM.ProductLevel) + P.Name AS VARCHAR (100)),
P.Color,
BOM.PerAssemblyQty,
cte_BOM.ProductLevel + 1,
cte_BOM.ProductID,
CAST (cte_BOM.Sort + '\' + p.Name AS VARCHAR (100))
FROM cte_BOM
INNER JOIN Production.BillOfMaterials AS BOM
ON BOM.ProductAssemblyID = cte_BOM.ProductID
INNER JOIN Production.Product AS P
ON BOM.ComponentID = P.ProductID
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
)
In the result set, the sum of parts is calculated in the GrandTotal column for all numbers up to an including 10. However, what we’re looking for is the sum of parts for 10. We can get this final result by add a WHERE clause outside the CTE. If we added WHERE CountNumber=10 inside the CTE in place of WHERE CountNumber<10 the CTE would terminate the recursion early.
WITH cte_BOM (ProductID, Name, Color, Quantity, ProductLevel, ProductAssemblyID, Sort)
AS (SELECT P.ProductID,
CAST (P.Name AS VARCHAR (100)),
P.Color,
CAST (1 AS DECIMAL (8, 2)),
1,
NULL,
CAST (P.Name AS VARCHAR (100))
FROM Production.Product AS P
INNER JOIN
Production.BillOfMaterials AS BOM
ON BOM.ComponentID = P.ProductID
AND BOM.ProductAssemblyID IS NULL
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
UNION ALL
SELECT P.ProductID,
CAST (REPLICATE('|---', cte_BOM.ProductLevel) + P.Name AS VARCHAR (100)),
P.Color,
BOM.PerAssemblyQty,
cte_BOM.ProductLevel + 1,
cte_BOM.ProductID,
CAST (cte_BOM.Sort + '\' + p.Name AS VARCHAR (100))
FROM cte_BOM
INNER JOIN Production.BillOfMaterials AS BOM
ON BOM.ProductAssemblyID = cte_BOM.ProductID
INNER JOIN Production.Product AS P
ON BOM.ComponentID = P.ProductID
AND (BOM.EndDate IS NULL
OR BOM.EndDate > GETDATE())
)
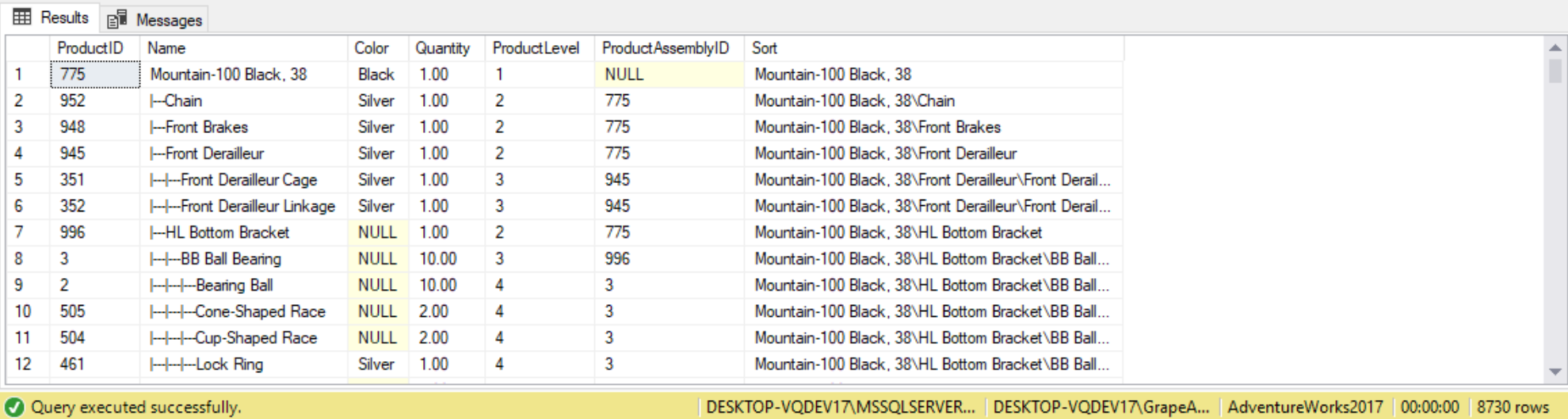
SELECT ProductID,
Name,
Color,
Quantity,
ProductLevel,
ProductAssemblyID,
Sort
FROM cte_BOM
ORDER BY Sort;
Note that the recursive part of the query can only refer to the CTE once. Also, a self-join is not allowed in the recursive query. Recursion stops when the recursive query returns no results.
The advantage that a CTE has over a scalar-valued function is that a CTE can pass entire rows to the recursive part, rather than a fixed number of input parameters like a scalar-valued function.
The logical steps for our next CTE demo are as follows, where we determine the hierarchy of departments from the Departments table:
- Select the top-level departments.
- For departments at the current level, select the sub-departments of that department.
- Repeat step 2 until there are no departments left.
These steps could be implemented without recursion if we knew the number of levels. We write a query to return each level and combine all the results into one list using the UNION ALL set operator. The recursion allows us to implement a generic query that will return the entire hierarchy independent of the number of levels. The anchor query starts the process for the first level and the recursive query repeats the process for each level.
Before we start, let’s create our demo table using the following code:
--Recursive CTE: Navigating Hierarchy
IF OBJECT_ID('TempDB.dbo.#MyEmployees') IS NOT NULL
DROP TABLE #MyEmployees;
CREATE TABLE #MyEmployees
(EmployeeID SMALLINT NOT NULL,
FirstName VARCHAR(30) NOT NULL,
LastName VARCHAR(50) NOT NULL,
Title VARCHAR(50) NOT NULL,
DeptID SMALLINT NOT NULL,
ManagerID INT NULL
CONSTRAINT PK_EmployeeID PRIMARY KEY CLUSTERED (EmployeeID ASC)
);
--Populate the table with values
INSERT INTO #MyEmployees VALUES
(1,N'Ken',N'Sanchez',N'Chief Executive Officer',16,NULL),
(273,N'Brian',N'Welcker',N'Vice President of Sales',3,1),
(274,N'Stephen',N'Jiang',N'North American Sales Manager',3,273),
(275,N'Michael',N'Blythe',N'Sales Representative',2,274),
(276,N'Linda',N'Mitchell',N'Sales Representative',3,274),
(285,N'Syed',N'Abbas',N'Pacific Sales Manager',3,273),
(286, N'Lynn',N'Tsoflias',N'Sales Representative',3,285),
(16,N'David',N'Bradley',N'Marketing Manager',4,273),
(23,N'Mary',N'Gibson',N'Marketing Specialist',4,16)
--Examine the table
SELECT * FROM #MyEmployees
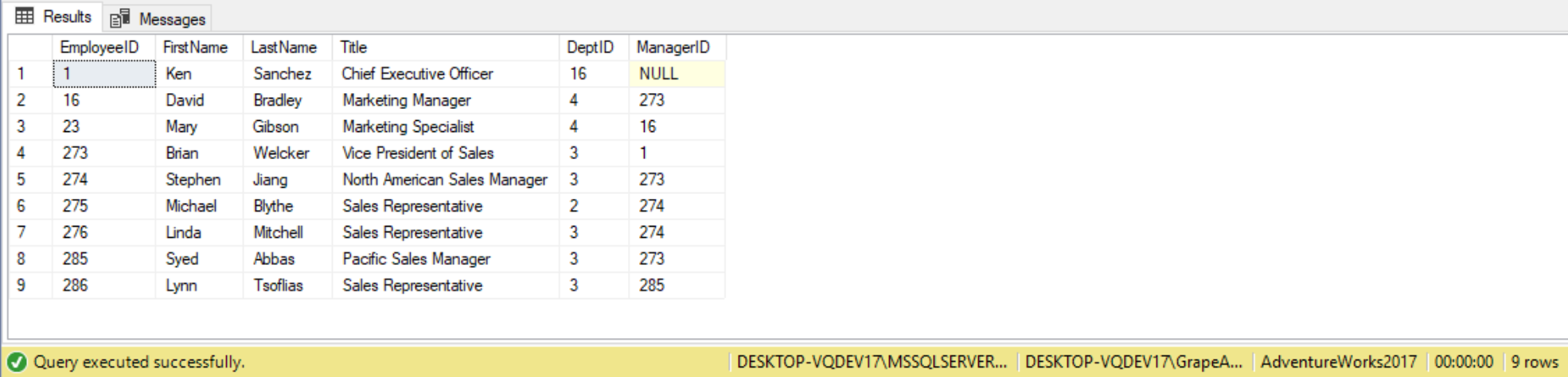
In our example, the anchor query will have a column called Level, which will start from 0 and gets added for each level through the hierarchy. The anchor query starts with asking for the top-level departments, which is level 0. The anchor query is written as follows:
WITH DirectReports
AS (SELECT e.ManagerID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE ManagerID IS NULL) --CEO
SELECT * FROM DirectReports;
The anchor query returns with four top level departments:

The Level field in the CTE is used to determine how deep we are in the hierarchy. For now, the output of the CTE will be the same as the out of the anchor query by itself. This anchor query CTE is the starting point, under which we will grab the child level of each department.
We then use the UNION ALL set operator to add the recursive part of the CTE to our anchor query. The recursive query takes the anchor query CTE output and joins it back to the Departments table to get the next level of the department hierarchy. The recursive part of our CTE is written as follows:
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID
Running the recursive query on its own will not work because it references the departmentsCTE which would be out of scope. To fix this, we use the UNION ALL operator to add the recursive query to the anchor query, like follows:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE ManagerID IS NULL --CEO
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID)
SELECT ManagerID,
EmployeeID,
Title,
DeptID
FROM DirectReports
JOIN HumanResources.Department AS dp ON DirectReports.DeptID = dp.DepartmentID
WHERE dp.GroupName = N'Sales and Marketing'
OR level = 0;
GO
The UNION ALL set operator is used to combine the result of the recursive query with the original results. We use the INNER JOIN statement to join to departmentsCTE, and an ORDER BY clause so that sub-departments end up grouped together.
The query returns just two levels, which could have been accomplished with a non-CTE query. However, the non-CTE query starts to break down if there are more than a couple of levels to the hierarchy.
MAXRECURSION
The maximum number of recursions in SQL is 100 levels by default. Beyond the maximum level SQL Server generates an error. The level is measured as the number of levels through the recursive path. The maximum recursion can be overridden if a recursion deeper than 100 levels is needed. The syntax to set the maximum recursion is to use the OPTION keyword with MAXRECURSION at the end of the query, like follows:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE ManagerID IS NULL --CEO
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID)
SELECT ManagerID,
EmployeeID,
Title,
DeptID
FROM DirectReports
JOIN HumanResources.Department AS dp ON DirectReports.DeptID = dp.DepartmentID
WHERE dp.GroupName = N'Sales and Marketing'
OR level = 0 OPTION(MAXRECURSION 2);
GO
If we adjust the MAXRECURSION to be 2, which is less than the number of levels returned, then we will see an error:

We can think of the error message as an indicator that the query in the CTE hasn’t properly terminated the recursion.
In the departmentsCTE example there were only 4 levels to the hierarchy after the anchor, but some queries could go much deeper. For example, if we only wanted the recursion to go 2 (anchor + 2) levels deep, and we wanted to avoid the maximum recursion error message, then we could terminate it like this:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE ManagerID IS NULL --CEO
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID)
SELECT ManagerID,
EmployeeID,
Title,
DeptID,level
FROM DirectReports
JOIN HumanResources.Department AS dp ON DirectReports.DeptID = dp.DepartmentID
WHERE dp.GroupName = N'Sales and Marketing'
and level<=2;
GO

To specify no maximum on a recursive CTE, we can use the MAXRECURSION 0 option. However, this can be dangerous if a query gets out of control, since a whole lot of memory and processing time can be taken up by a run-away recursive query.
The MAXRECURSION option has a maximum input value of 32,767, but that doesn’t mean the recursion is limited to 32,767 levels. Recursion can be deeper than that by just specifying 0 for MAXRECURSION.
Bringing it All Together
In summary, the following are the steps involved in a recursive CTE:
- Run the anchor query, save the output as R1.
- Pass R1 to the recursive query, save output as R2.
- Pass R2 to the recursive query, save output as R3.
- Pass R3 to the recursive query, save output as R4.
- …
- Pass Rn to the recursive query, save output as Rn+1.
- Continue until Rn returns no output.
Even though the recursive part of the query is only listed once in the CTE, it behaves as though it was duplicated as many times as the depth of the recursion is in the query.
Advanced Recursion
We can also add multiple anchor queries and multiple recursive queries inside a single CTE. The multiple anchor or multiple recursive queries are separated with the UNION ALL keyword.
Using Multiple Anchor Queries
An example of using multiple anchor queries would be if we wanted to look up sub-departments for two or more top level departments, but not for all of them. For example, if we wanted to only display the departments and sub-departments for Fitness and Cycling, this can be accomplished with multiple anchor queries.
We take the departmentsCTE we created but filter just for the Cycle department (which has an id of 2). This displays the Cycle department and all its sub-departments, as follows:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE DeptID = 3
We then take the anchor query and change the WHERE clause to filter on Department 4 (which is fitness), as follows:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE DeptID = 3
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE DeptID = 4
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID)
SELECT ManagerID,
EmployeeID,
Title,
DeptID
FROM DirectReports
JOIN HumanResources.Department AS dp ON DirectReports.DeptID = dp.DepartmentID
WHERE dp.GroupName = N'Sales and Marketing'
OR level = 0;
GO
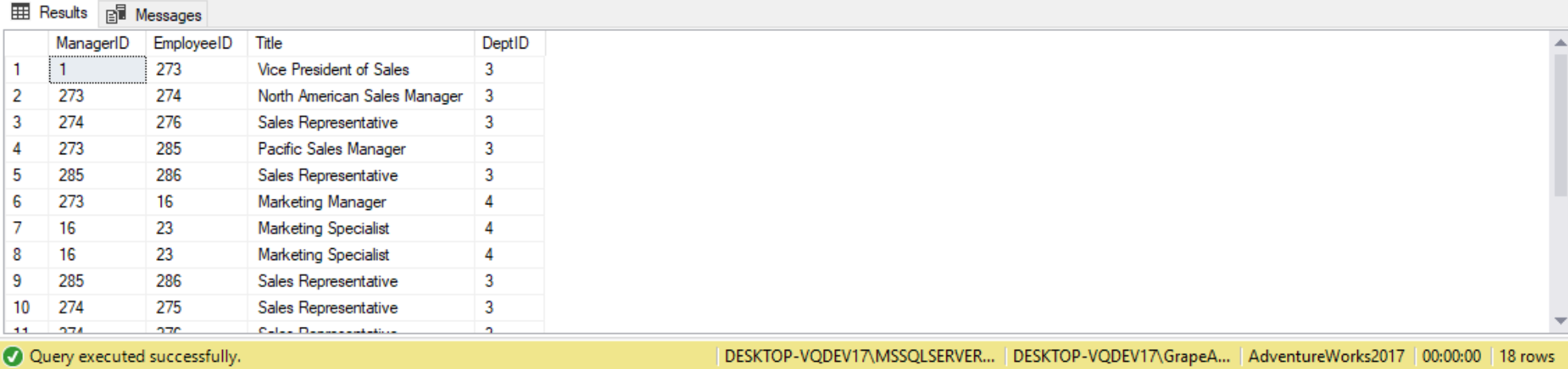
Notice that there are now two UNION ALL statements, one between the two anchors, and another between the anchors and the recursive query. The above multiple anchor CTE could have been created with a single anchor query using the IN keyword in the WHERE clause, like this:
WITH DirectReports
AS (SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID AS DeptID,
0 AS Level
FROM #MyEmployees AS e
INNER JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL --Only active employees returned
WHERE DeptID IN(3, 4)
UNION ALL
SELECT e.ManagerID,
e.EmployeeID,
e.Title,
edh.DepartmentID,
Level + 1
FROM #MyEmployees AS e
JOIN HumanResources.EmployeeDepartmentHistory AS edh ON e.EmployeeID = edh.BusinessEntityID
AND edh.EndDate IS NULL
JOIN DirectReports AS d ON e.ManagerID = d.EmployeeID)
SELECT ManagerID,
EmployeeID,
Title,
DeptID
FROM DirectReports
JOIN HumanResources.Department AS dp ON DirectReports.DeptID = dp.DepartmentID
WHERE dp.GroupName = N'Sales and Marketing'
OR level = 0;
GO
This simpler query produces the exact same results as the multiple anchor CTE. With recursive CTEs it is common to find multiple ways to achieve the same results.
Using Multiple Recursive Queries
To create multiple recursive queries, we simply add additional recursive queries into the CTE separated by UNION ALL.
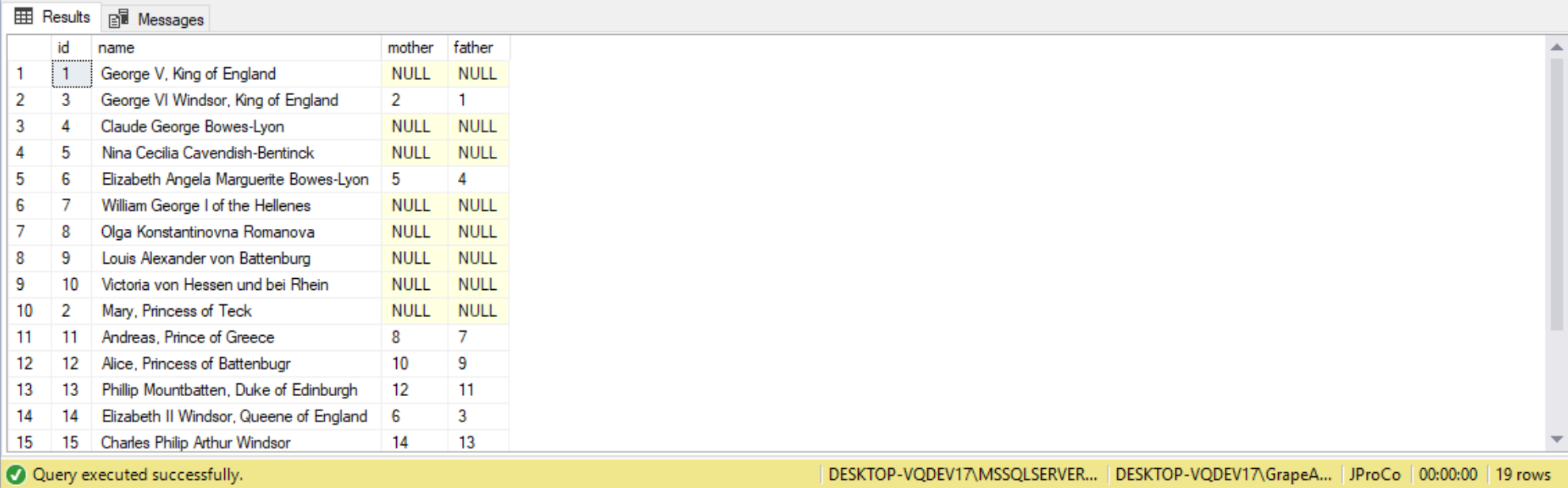
For example, we can use recursive queries to follow the family tree of the British royalty. The code to create this demo table is as follows:
CREATE TABLE #Royalty (
id int, --would normally be an INT IDENTITY
name VARCHAR (200),
mother int,
father int,
);
INSERT INTO #Royalty (id, name, mother, father) VALUES (1, 'George V, King of England', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (3, 'George VI Windsor, King of England', 2, 1);
INSERT INTO #Royalty (id, name, mother, father) VALUES (4, 'Claude George Bowes-Lyon', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (5, 'Nina Cecilia Cavendish-Bentinck', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (6, 'Elizabeth Angela Marguerite Bowes-Lyon', 5, 4);
INSERT INTO #Royalty (id, name, mother, father) VALUES (7, 'William George I of the Hellenes', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (8, 'Olga Konstantinovna Romanova', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (9, 'Louis Alexander von Battenburg', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (10, 'Victoria von Hessen und bei Rhein', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (2, 'Mary, Princess of Teck', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (11, 'Andreas, Prince of Greece', 8, 7);
INSERT INTO #Royalty (id, name, mother, father) VALUES (12, 'Alice, Princess of Battenbugr', 10, 9);
INSERT INTO #Royalty (id, name, mother, father) VALUES (13, 'Phillip Mountbatten, Duke of Edinburgh', 12, 11);
INSERT INTO #Royalty (id, name, mother, father) VALUES (14, 'Elizabeth II Windsor, Queene of England', 6, 3);
INSERT INTO #Royalty (id, name, mother, father) VALUES (15, 'Charles Philip Arthur Windsor', 14, 13);
INSERT INTO #Royalty (id, name, mother, father) VALUES (16, 'Diana Frances (Lady) Spencer', 18, 19);
INSERT INTO #Royalty (id, name, mother, father) VALUES (17, 'William Arthur Phillip Windsor', 16, 15);
INSERT INTO #Royalty (id, name, mother, father) VALUES (18, 'Frances Ruth Burke Roche', null, null);
INSERT INTO #Royalty (id, name, mother, father) VALUES (19, 'Edward John Spencer', null, null);
GO
SELECT * FROM #Royalty
If we wanted to query to trace Prince William’s maternal ancestors, it would be straightforward with a CTE, like follows:
WITH RoyalTreeCTE
AS (SELECT *
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.mother)
SELECT * FROM RoyalTreeCTE;

Finding the paternal ancestors would be similar; instead of using the mother column, we use the father column, as follows:
WITH RoyalTreeCTE
AS (SELECT *
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father)
SELECT * FROM RoyalTreeCTE;

To find both the maternal and paternal sides of a family tree, we can use multiple recursive queries, as follows:
WITH RoyalTreeCTE
AS (SELECT *
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father
UNION ALL
SELECT r.*
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father)
SELECT *
FROM RoyalTreeCTE;
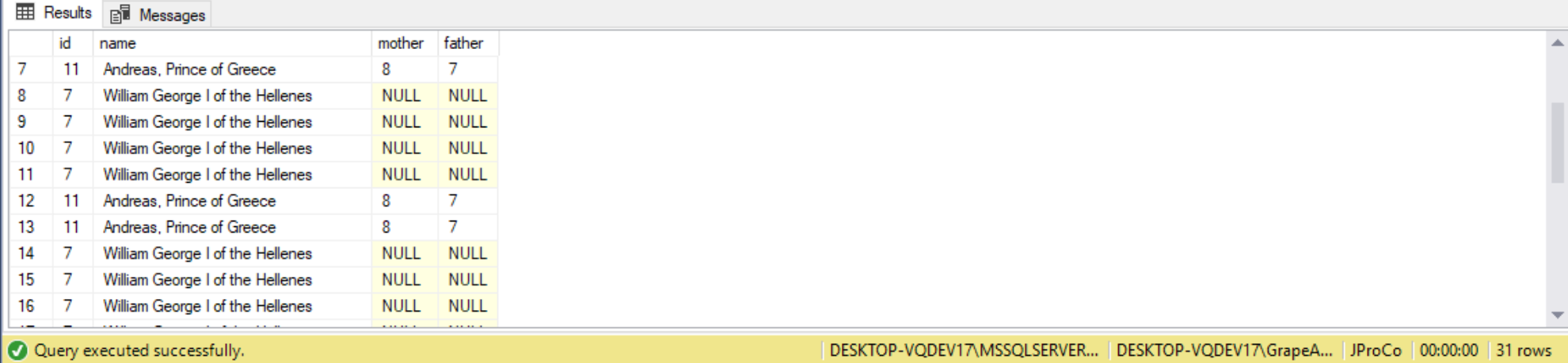
Hierarchal CTEs
While recursive CTEs gives us the ability to access data, hierarchical queries with the right formatting gives us the ability to visually understand the data. In SQL Server the use of tables does not follow a hierarchal structure like what we would see in the Table of Contents section of a book. Instead, we can walk through the hierarchal structure of a table and display those relationship using a column that identifies the parent-child relationship and a well written CTE. Hierarchical queries can be easily built with a recursive CTE.
Hierarchal Tree Path
One way to display hierarchical data is by using a tree path where the current item is shown with a full path of its parents until the root of the tree is reached. A tree path is used to describe the entire hierarchy path through a tree. Examples of where tree paths are used include the Windows file system or the category levels that might be shown in an online store.
We can build the tree path in a CTE by concatenating or adding on each of the tree levels as the query recursively links the data together. To build the tree path from the Departments table, we can apply the following algorithm:
- At the top level, use the current department as the fill tree path.
- For each level of recursion add on to the current department with the separator to the current path.
To demonstrate this, let’s build on the departmentsCTE we created previously:
WITH EmployeeCTE
AS (SELECT EmployeeID,
Title,
ManagerID,
1 AS Level
FROM #MyEmployees
WHERE ManagerID IS NULL
UNION ALL
SELECT e.EmployeeID,
e.Title,
e.ManagerID,
EmployeeCTE.Level + 1 AS Level
FROM #MyEmployees AS e
INNER JOIN EmployeeCTE ON EmployeeCTE.EmployeeID = e.ManagerID)
SELECT *
FROM EmployeeCTE
ORDER BY Level;
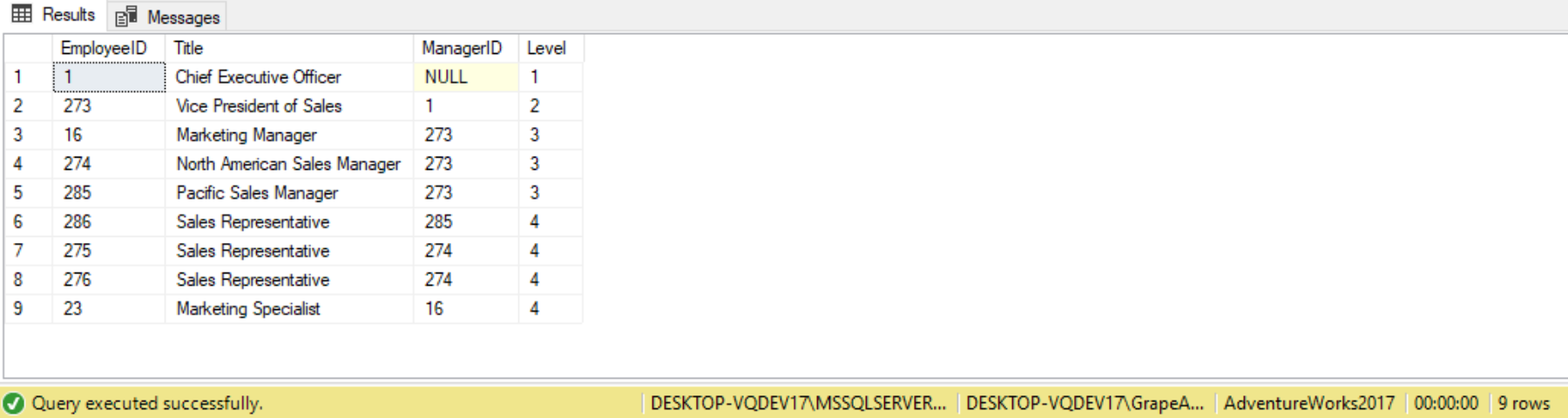
To the departments CTE, we will add in a new result column called TreePath. This new column needs to be added to both the anchor and recursive queries. From the anchor query the full path (TreePath) is just the current department so we add a new column into the anchor query, as follows:
CAST(Title AS VARCHAR(100)) AS TreePath
For the recursive query we add a reference to the existing TreePath, followed by a separator and then the current department, as follows:
CAST(EmployeeCTE.TreePath+'-->'+e.Title AS VARCHAR(100)) AS TreePath
Note that the data type for the new TreePath column must be exactly same on both the anchor and recursive queries (in this case, we set TreePath to VARCHAR(8000)). After adding the TreePath column to the anchor and recursive queries, we end up with the following query:
WITH EmployeeCTE
AS (SELECT EmployeeID,
Title,
ManagerID,
1 AS level,
CAST(Title AS VARCHAR(100)) AS TreePath
FROM #MyEmployees
WHERE ManagerID IS NULL
UNION ALL
SELECT e.EmployeeID,
e.Title,
e.ManagerID,
EmployeeCTE.Level + 1 AS level,
CAST(EmployeeCTE.TreePath+'-->'+e.Title AS VARCHAR(100)) AS TreePath
FROM #MyEmployees AS e
INNER JOIN EmployeeCTE ON EmployeeCTE.EmployeeID = e.ManagerID)
SELECT * FROM EmployeeCTE ORDER BY Level;
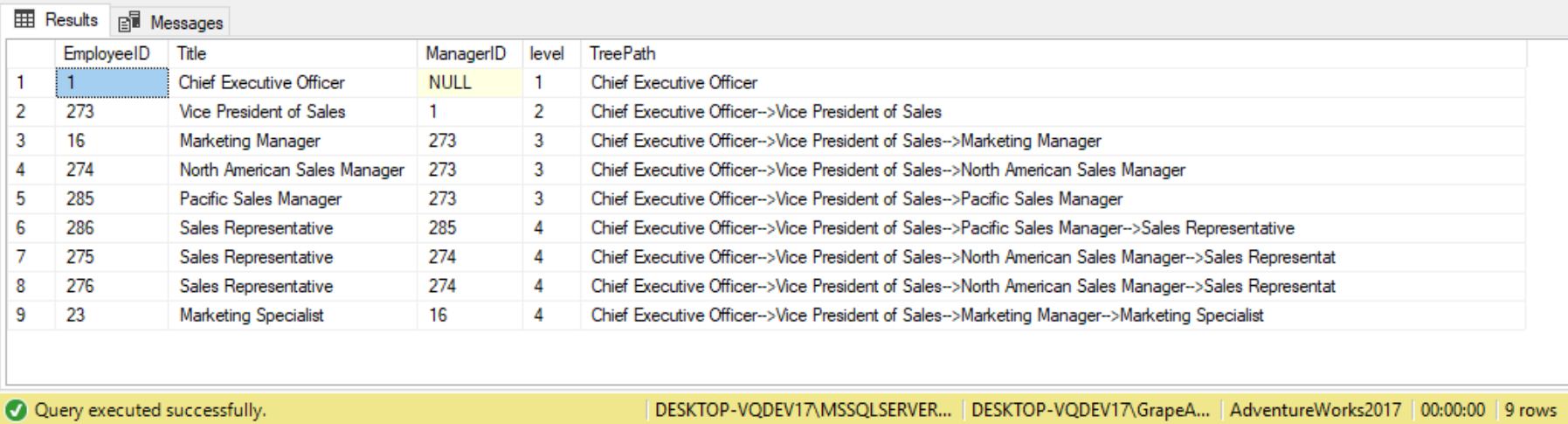
To improve the query further, we can filter out just the TreePath column and order it by TreePath for better visual representation, as follows:
SELECT TreePath FROM EmployeeCTE ORDER BY TreePath;
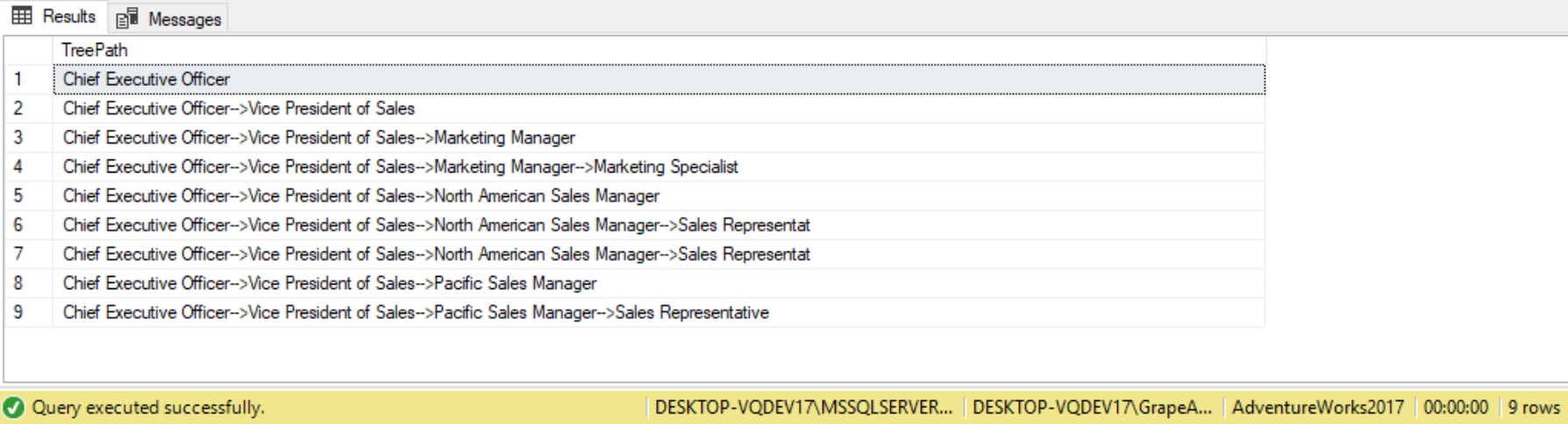
By ordering the TreePath column using the ORDER BY clause, we can format better by grouping departments by their parent department.
To have the Department tree path be represented more like the Windows file system, we can simply change the separator from ‘->’ to ‘\’, returning the following result set:
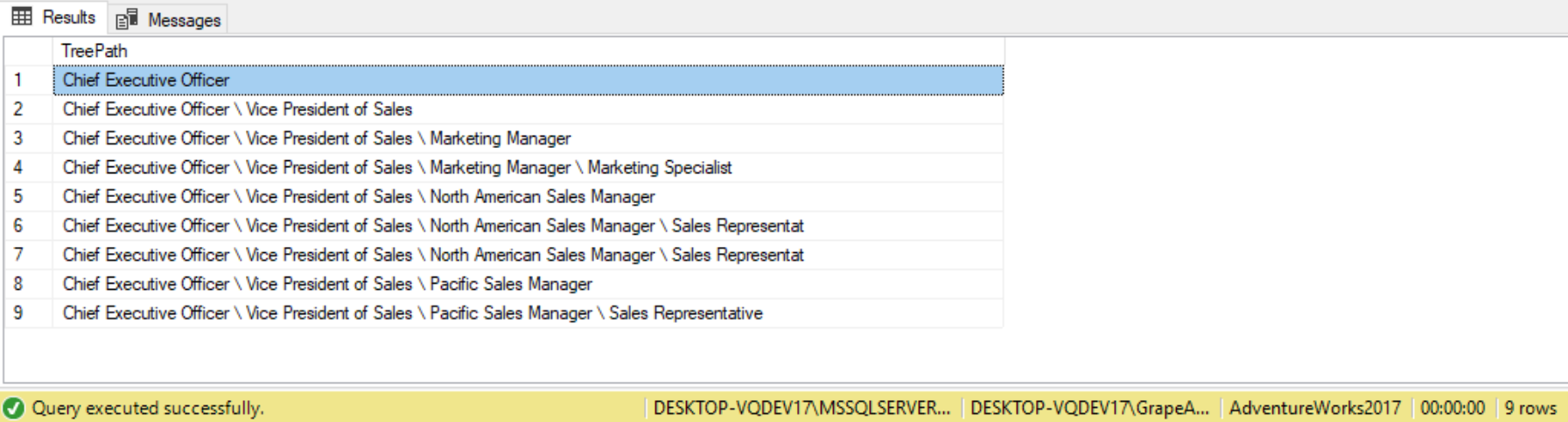
Hierarchal Formatting
Sometimes when using recursive CTEs to display hierarchal data, we may run out of space to display the data on the screen or in the area we are working with. When space is limited, the indentation or outline style of showing hierarchal might be a better option. This can be achieved using the REPLICATE function with various indentation options.
The way the indentation will be built is to take the exact same tree path CTE from the previous section, keeping the TreePath column formatted and sorted exactly as before. We add a new column to the result set of the CTE (called Department), which will replicate the indentation as desired. The following example replicates four spaces for each level of the hierarchy, using the REPLICATE function:
WITH EmployeeCTE
AS (SELECT EmployeeID,
Title,
ManagerID,
1 AS level,
CAST(Title AS VARCHAR(100)) AS TreePath
FROM #MyEmployees
WHERE ManagerID IS NULL
UNION ALL
SELECT e.EmployeeID,
e.Title,
e.ManagerID,
EmployeeCTE.Level + 1 AS level,
CAST(EmployeeCTE.TreePath+' \ '+e.Title AS VARCHAR(100)) AS TreePath
FROM #MyEmployees AS e
INNER JOIN EmployeeCTE ON EmployeeCTE.EmployeeID = e.ManagerID)
SELECT REPLICATE(' ', Level)+Title AS Title
FROM EmployeeCTE ORDER BY Level;
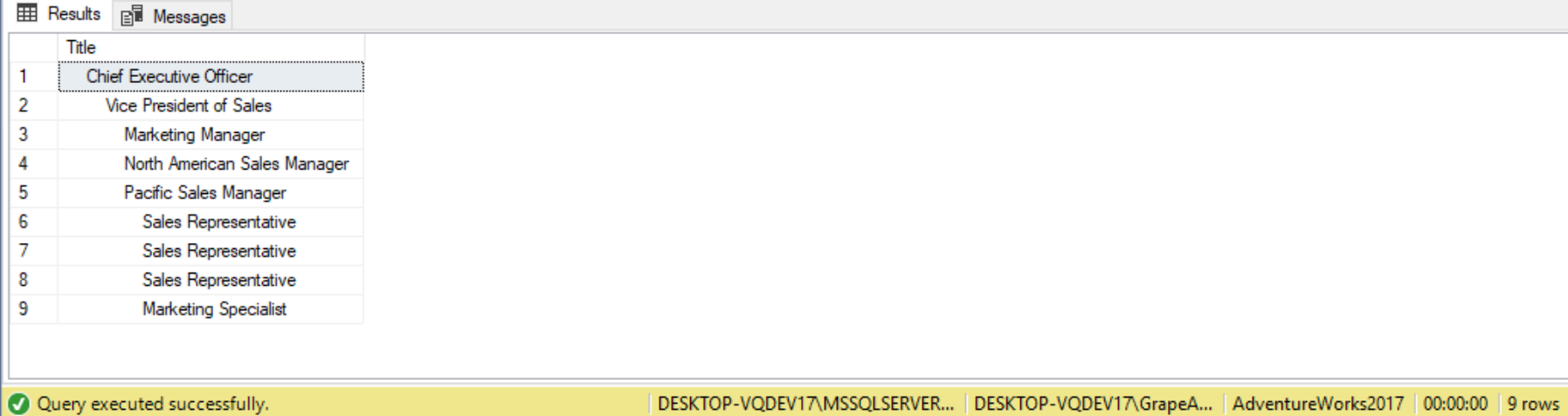
Hierarchy in Multiple Recursive Queries
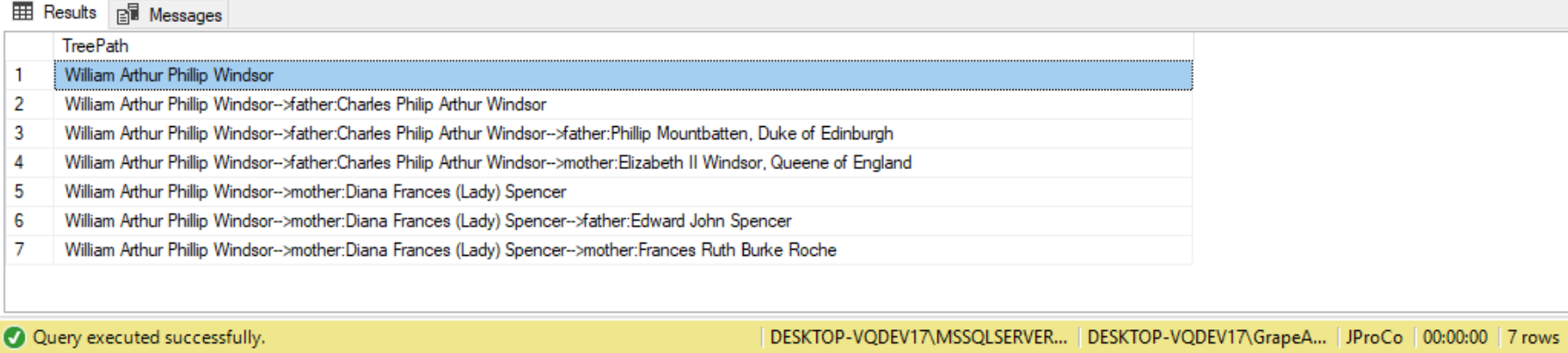
We can take a CTE with multiple recursive queries, such as the RoyalTreeCTE, and apply to that the tree path method of formatting. The following query limits the result to only 4 levels of hierarchy:
WITH RoyalTreeCTE
AS (SELECT *,
1 AS level,
CAST(name AS VARCHAR(4096)) AS TreePath
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(rt.TreePath+'-->father:'+r.name AS VARCHAR(4096)) AS TreePath
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(rt.TreePath+'-->mother:'+r.name AS VARCHAR(4096)) AS TreePath
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.mother)
SELECT TreePath
FROM RoyalTreeCTE WHERE level < 4
ORDER BY TreePath;
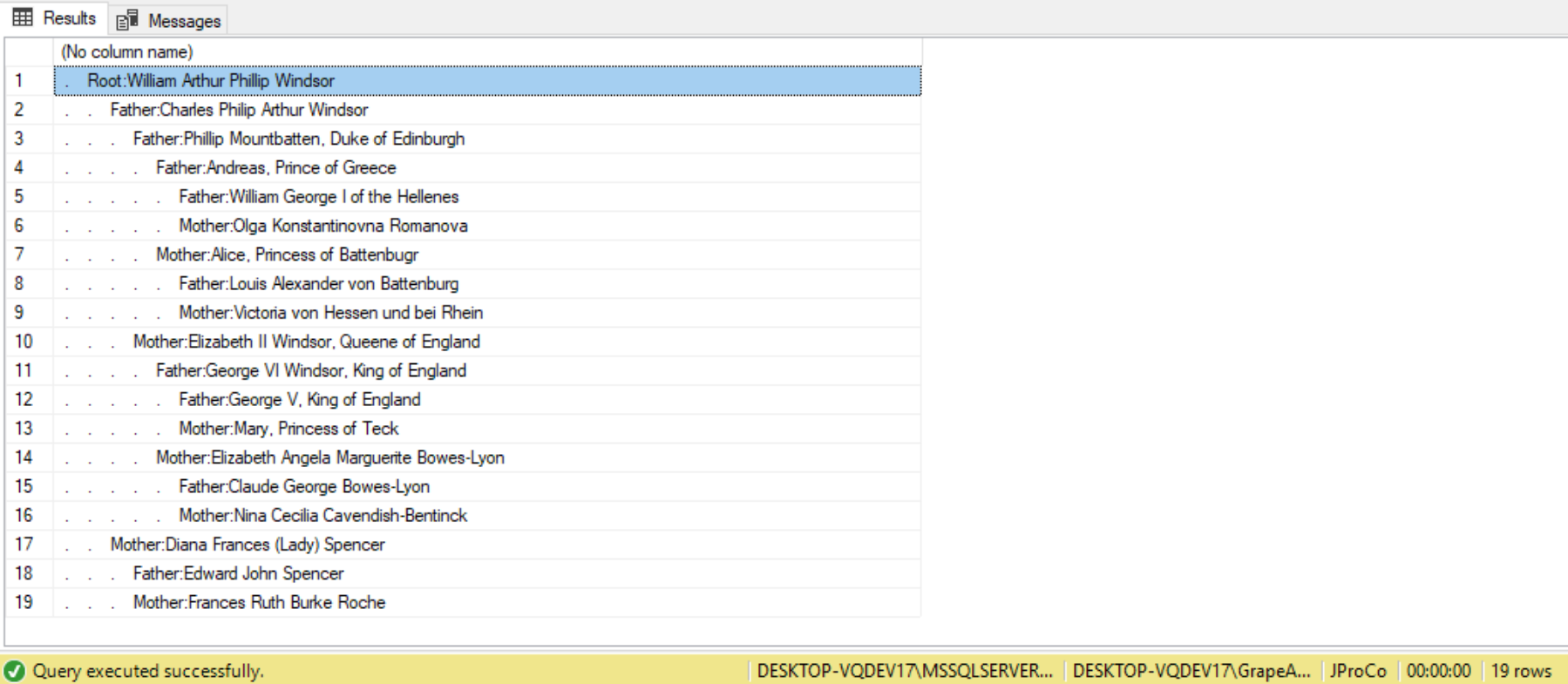
The next option is to switch to the indentation method instead of the tree path method. This can be done by changing the SELECT statement outside the CTE, as follows:
SELECT REPLICATE('. ', Level) + Relationship + ':' + name
In this example we will keep the ORDER BY TreePath to preserve the same order as before. The query and result would look like this:
WITH RoyalTreeCTE
AS (SELECT *,
1 AS level,
CAST(name AS VARCHAR(4096)) AS TreePath,
CAST('Root' AS VARCHAR(10)) AS Relationship
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(rt.TreePath+'-->father:'+r.name AS VARCHAR(4096)) AS TreePath,
CAST('Father' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(rt.TreePath+'-->mother:'+r.name AS VARCHAR(4096)) AS TreePath,
CAST('Mother' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.mother)
SELECT REPLICATE('. ', Level)+Relationship+':'+name
FROM RoyalTreeCTE ORDER BY TreePath;
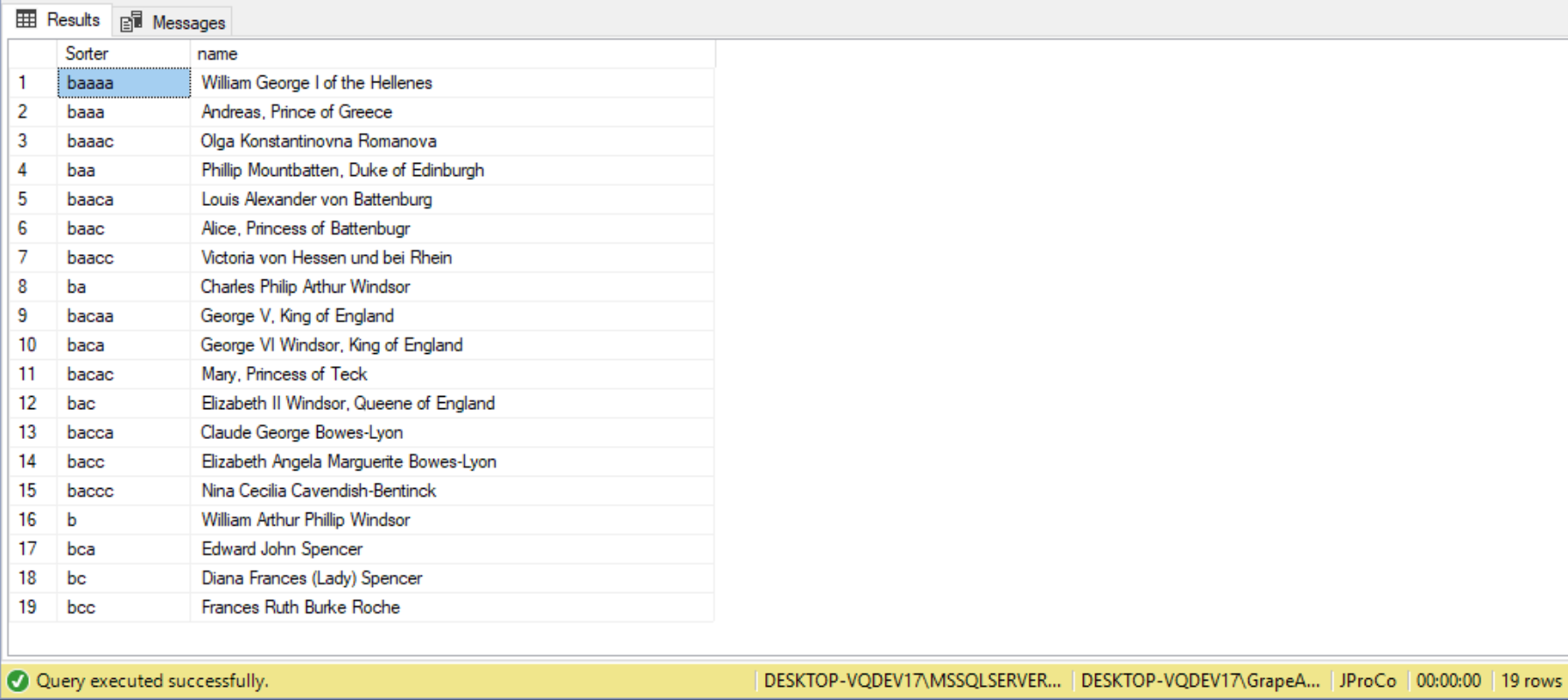
Looking at the overall hierarchy in the result set, it doesn’t look like the common family tree that has the individual in the middle, and the paternal and maternal on one side or the other. In order to improve the formatting, we need to achieve the desired sorting. We change our format by adding another column to the anchor and recursive queries called Sorter, and we drop the tree path since we won’t be using that for sorting any more. The sort algorithm is the following:
- Assign a ‘b’ to the person at the root, Prince William in this case.
- For any individuals’ father, we add ‘a’ to the sorter.
- For any individuals’ mother, we add ‘c’ to the sorter.
- When all sorting is complete, append the series of ‘b’s to the sorter so that shorter sort strings end up in the middle.
With this logic added to the code there are 4 lines changed from the previous CTE examples. The Sorter column was added to the anchor query setting the Sorter value to ‘b’, which covers item #1 in the sort algorithm. Next, a Sorter column is added to the recursive query for the father’s side, and it adds the value of ‘a’ to the Sorter column, meeting item #2 in the algorithm. Then the Sorter column is added to the mother’s recursive query with the value of ‘c’ added to the Sorter column, this meets item #3 in the algorithm. The final change is to add a series of ‘b’s to the Sorter column in the ORDER BY clause, which meets item #4 in the algorithm. If the maternal side was needed to appear above instead of the paternal side, we simply swap the ‘a’ and ‘c’ values for the Sorter in the mother and father recursive queries. Here is how the query would go:
WITH RoyalTreeCTE
AS (SELECT *,
1 AS level,
CAST('b' AS VARCHAR(4096)) AS Sorter,
CAST('Top' AS VARCHAR(10)) AS Relationship
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(Sorter+'a' AS VARCHAR(4096)) AS Sorter,
CAST('Father' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(Sorter+'c' AS VARCHAR(4096)) AS Sorter,
CAST('Mother' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.mother)
SELECT Sorter,
name
FROM RoyalTreeCTE
ORDER BY Sorter+'bbbbbbbbbbbbb';
While we still have the right sort order, the output still doesn’t look like any recognizable family tree layout. The next step is to use the REPLICATE function to do the indentation that we are looking for and to choose the right data. This gives us a dot and eleven spaces of indentation for each level through the family tree. It includes the Relationship column of Top (for Prince William), Father or Mother for the rest, and then the person’s name. Here is the updated code for our query:
WITH RoyalTreeCTE
AS (SELECT *,
1 AS level,
CAST('b' AS VARCHAR(4096)) AS Sorter,
CAST('Top' AS VARCHAR(10)) AS Relationship
FROM #Royalty
WHERE id = 17
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(Sorter+'a' AS VARCHAR(4096)) AS Sorter,
CAST('Father' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.father
UNION ALL
SELECT r.*,
level + 1 AS level,
CAST(Sorter+'c' AS VARCHAR(4096)) AS Sorter,
CAST('Mother' AS VARCHAR(10)) AS Relationship
FROM #Royalty AS r
INNER JOIN RoyalTreeCTE AS rt ON r.id = rt.mother)
SELECT REPLICATE('. ', Level)+Relationship+':'+name
FROM RoyalTreeCTE
ORDER BY Sorter+'bbbbbbbbbbbbb';
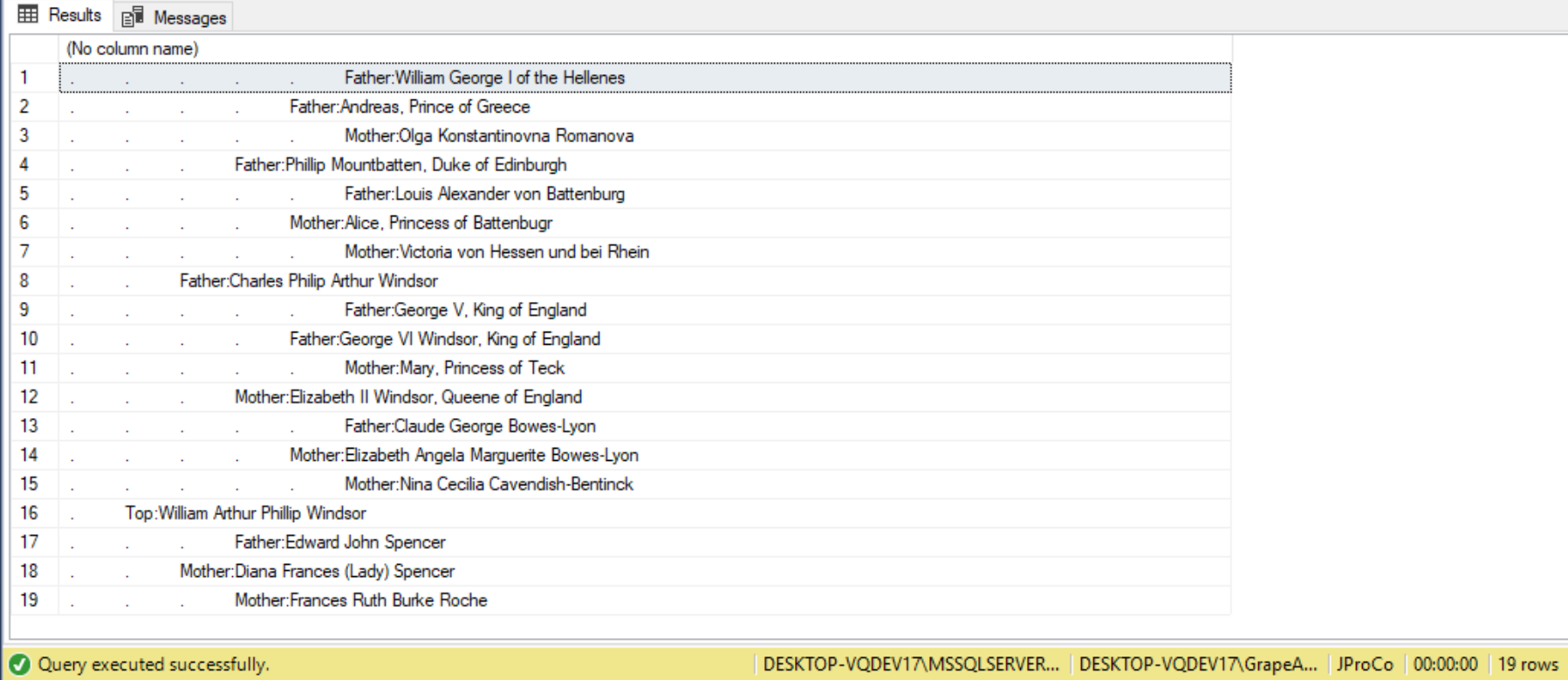
In summary, the following are the steps we took to build the family tree:
- Build the hierarchy with a recursive CTE with multiple recursive members.
- Use indentation to display the depth of recursion.
- Use sorting to get the order that is desired.
The same logic can be applied to any set of hierarchical data to get similar results. Hierarchical recursive CTEs perform better than a UNION ALL type non-CTE query that accomplishes similar results.
Multiple CTEs in a Query
With multiple CTEs in the same query, later CTEs can access the earlier CTEs, this is known as a nested CTE. Multiple CTEs can be used in queries in several ways: independent of each other, building on each other, or a combination. There can be many levels of nesting CTEs if it makes sense for a specific query.
Adding a second CTE
The steps for adding a second CTE can be repeated to add a third, fourth, or more CTE queries. The steps to add a second CTE are as follows:
- Add a comma at the end of the first CTE, after the closing parentheses.
- After the comma, on the next line, specify the name of the new CTE.
- After the name of the new CTE add the optional column specifications.
- Add the AS keyword followed by opening and closing parentheses.
- Inside the parentheses add the new CTE query.
- Call the CTE query from the outer SELECT statement.
Before we can add a second CTE we need a query that uses a single CTE that it can be added to. To start with we will use a single CTE that simply displays three names from the CTE. This is not a recursive query, but it is using the UNION set operator to place the three names into the result set.
WITH fnames(Names)
AS (SELECT 'John'
UNION
SELECT 'Mary'
UNION
SELECT 'Bill')
SELECT Names AS FirstName
FROM fnames;

To add the second CTE, we follow the steps listed above. In the following example, we will be adding a series of last names into the first names list from the previous CTE. For the list of last names, the same UNION style query of the three results will be used to build a result of three last names.
SELECT 'Smith' UNION SELECT 'Gibb' UNION SELECT 'Jones';
We now place the Lnames CTE into the existing query, like follows:
WITH fnames(Names)
AS (SELECT 'John'
UNION
SELECT 'Mary'
UNION
SELECT 'Bill'),
lnames(Names)
AS (SELECT 'Smith'
UNION
SELECT 'Gibb'
UNION
SELECT 'Jones')
SELECT f.Names AS FirstName,
l.Names AS LastName
FROM fnames AS f
CROSS JOIN lnames AS l;
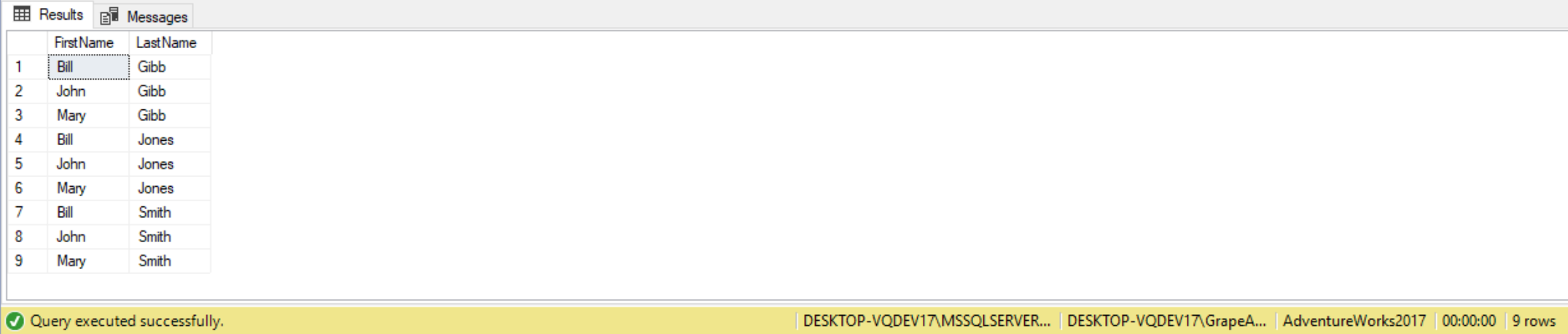
The query above uses a CROSS join, creating a Cartesian product of the two inputs. This matches every element from Fnames with every element from Lnames, producing a total of three times three (or 9) rows in the result set.
When using multiple CTEs in a single query, those CTEs can be comprised of a single anchor query, multiple anchor queries, no recursive query, a single recursive query, or multiple recursive queries. Any of the things that can be done with a single CTE can be done with each of the single CTEs in a multiple CTE query.
Nesting CTEs
A CTE in nested CTE query can only access itself or CTEs declared prior to that one, but not the CTEs declared after. Suppose we’re using the JProCo database to find the top 10 customers with the most orders. For each of the customers, we want returned their name and the number of ordered items. There are many ways to accomplish this, such as using a large query with several derived tables, or it could be done using multiple nested CTEs. We begin by building a CTE to get the top 10 customers by number of orders, like follows:
WITH CustomersWithMostOrdersCTE
AS (SELECT TOP 10 CustomerID,
COUNT(*) AS numOrders
FROM sales.SalesOrderHeader
GROUP BY CustomerID
ORDER BY numOrders DESC) --First CTE
Once we have the customers with the most orders, another CTE can be added to add the customers names into the results. Notice that in the following query the first CTE is referenced by the second CTE, and only inside of the second CTE. The first CTE can be accessed by both the second CTE and the outer query.
(Include code, explanation, and results from page 102)
We now add another CTE to get the total number of items per invoice. This CTE will not be nested and will only be accessed by the outside query, and it does not reference any of the other CTEs.
(Include code, explanation, and results from page 103)
To walk through what’s happening in the example above, we follow these steps:
- The outer SELECT statement is accessing OrderItemsPerCustomerCTE and CustomersOrdersWithNamesCTE.
- CustomersOrdersWithNamesCTE references a table and it also references CustomersWithMostOrdersCTE which is considered nested.
- CustomersWithMostOrdersCTE doesn’t reference any CTEs, it only references tables.
- OrderItemsPerCustomerCTE doesn’t reference any CTEs, it only references tables.
In this result we ended up with 3 CTEs: two nested, and one not nested. If needed, we can have nested CTEs that are many levels deep. If there are several CTEs being used in a single statement, some of them can be nested, and come can be independent and only accessed from the outer SELECT.
How many Levels of Nesting
We should only nest what we need to nest. A few dozens or even up to 100 nested CTEs shouldn’t pose a problem. The number of nested levels we can use depends on the version of SQL Server being used. For SQL Server 2017, the nested CTE limit is limited by the available memory. Generally, SQL Server 2017 or newer will run out of memory before any built-in maximum is hit. So the real answer to how many levels can be nested is “it depends.” It depends really on the amount of memory available: https://docs.microsoft.com/en-us/sql/sql-server/maximum-capacity-specifications-for-sql-server?view=sql-server-2017
The limits on levels of nesting are probably more than should ever be needed. It may be worth reassessing the logic before attempting to create a nested CTE more than a few hundred levels deep.
Additional Breakdown of Derived Tables
If it made sense to use a CTE to replace a single derived table, it may make sense to use multiple CTEs to replace multiple different derived tables.
The following query makes use of two different derived tables:
(Include code, explanation, and results from page 106)
If we follow the steps described earlier to break derived tables into CTES, we can apply that to the above derived tables as follows:
(Include code, explanation, and results from page 108-skip code and results from page 107)
With a small query like this, the value of cleaning up isn’t always apparent. Suppose each of the CTEs in our example were 15 lines of code, and each CTE is referenced three or more times. In this case, the CTE version of the query would be significantly smaller than the derived table version and would less likely to have errors since there wouldn’t be duplicated code.
Note that there is no steadfast rule that says derived tables should always be converted to CTEs, and there probably are many examples where the derived table will actually be cleaner code.
Theoretical Example
It is a good idea to anticipate and plan on flushing out performance problems with growth. When working in a test environment, we should plan for growth and add 10 times the expected growth into the test tables. For instance, if we’re planning for a million records, we add 10 million rows into the test table.
One way to do this is to create one INSERT statement and run it 10,000,000 times. While this will fill up the table, it won’t be very realistic data since every row will be exactly the same. To start, we take a table a table call Users that contains a few columns and a couple of indexes, one clustered and one not. We fill this table with the following code:
(Include code to create the table)
(Include code, explanation, and results from page 111)
Using the GO statement followed by the number tells SSMS to run the script that specified number of times. So, GO 10000000 means to run the script 10,000,000 times, which will put 10 million rows into the Users table. The problem with this method is that every row in the Users table will be exactly the same and indexing on the LoginName where all the rows are identical won’t give realistic indexing performance.
An alternative method is to use a CTE. First, we create the CTE to generate the data, and then use it with an INSERT statement. In the following example, we will use a CTE we worked with earlier, and we will add in another CTE for middle names. The CTE code is updated to include the Mnames CTE, as follows:
(Include code, explanation, and results from page 111)
With three tables cross joined and three rows in each table, the code generates 3 x 3 x 3, or 27 rows. While it’s nowhere near the 10 million rows we’re looking for, it is a start.
The next step is to add a UserName field to the result set, so we add a fourth CTE as the base value for the user name. When that fourth CTE is accessed we concatenate it with L.Name.
(Include code, explanation, and results from page 112)
Now the total rows generated is, 3 x 3 x 3 x 3, or 81 rows. Next, we add another CTE called Uniqueifier, which is intended to make the username more unique. The outer query references the Uniqeifier CTE twice in the CROSS JOIN and adds it to the front and back of the value of the UserName field.
(Include code, explanation, and results from page 113)
Now we have 3 x 3 x 3 x 3 x 3 x 3, or 729 results. Still not the 10 million rows we want. Next, we add the INSERT INTO statement into the outer query so the output from the CTEs goes into the Users table.
(Include code, explanation, and results from page 114)
729 rows inserted into the Users table, still not the 10 million we want. We can get there easily. We add the CTEs until we have 15 first names, 15 middle names, 15 user name bases, and 15 Uniqueifier rows. This gives us 15 x 15 x 15 x 15 x 15 x 15, or 11,390,625 rows, just over the 10 million that we were looking for. This will be plenty of user data to simulate a big table.
At this point, with a single INSERT INTO statement combined with a SELECT statement it took just a couple of minutes to run, we can quickly and easily add millions of rows into a table for testing purposes.
In conclusion, a common use case for multiple CTEs in a single statement is to quickly populate tables with large amounts of test data. Performance issues can be addressed by testing with large amounts of data in new tables before deploying them into a production system. This type of testing (based on loading up a table with millions of rows from a CTE) could make the difference between success and failure of a database application.
Data paging
Data paging is used when working with a result set that is too large to display in the space available or in the time available. CTEs gives us a way to do data paging on queries with large result sets that would otherwise not be usually feasible in T-SQL. Data paging is analogous to an internet search engine, where generally the first 20 results out of many are displayed on the first page. Imagine if a search engine tried to display 2.7 billion results; it would take a while for the page to load. If the result we want is not on the first page, we can click through the second, third or beyond pages. This concept is known as data paging.
Data Paging CTE
The steps to quickly and easily create a data paging CTE are as follows:
- Create the original query that needs paging.
- Use the ROW_NUMBER function with the OVER clause to add a new column into the original query to display a row number. If the original query had an ORDEY BY clause specified, we move the ORDER BY into the OVER clause.
- Wrap the query from step 2 with a CTE and select everything from that CTE.
- Add a WHERE clause to the outer query to filter the rows for the first page.
- Remove the fixed values and replace them with variables to hold the page number and page size.
The use of the ROW_NUMBER window function with the OVER clause allow the assignment of a row identifier that can be used to filter out only the rows for a given page. The reason that a CTE is needed to accomplish this is that the ROW_NUMBER function and OVER clause (window functions) can’t be used in a WHERE clause, but when they are returned from a CTE they can be used in the outer WHERE clause.
The query for Step 1 is as follows:
(Include code, explanation, and results from page 123)
The query for Step 2 where we add the window function is as follows:
(Include code, explanation, and results from page 123)
A common mistake is to try and out the ROW_NUMBER with the windowing function into the WHERE clause, which isn’t allowed as show below:
(Include code, explanation, and results from page 124)
The query for Step 3 where we wrap the query from Step 2 with a CTE and select everything from the CTE, is as follows:
(Include code, explanation, and results from page 125)
The query for Step 4 where we add “WHERE RowNum BETWEEN 0 AND 10;” to filter the first page with a page size of 10, is as follows:
(Include code, explanation, and results from page 125)
At this point, we can test the data paging by adjusting the numbers in the WHERE clause and confirming that we get the correct results.
For Step 5, we declare 2 variables, @pageNum and @pageSize which will be used in the WHERE clause to calculate the row number that are to be shown on the current page. BETWEEN is used in the WHERE clause to calculate the row number of the first row on this page and to calculate the row number of the last row on this page. The query for Step 5 where we remove the fixed values and replace them with the variables to hold the page number and page size, is as follows:
(Include code, explanation, and results from page 126)
At this point all we need to do to get to page 3 is change the @pageNum variable from the previous code example.
(Include code, explanation, and results from page 127)
With these five easy steps a query which produces a large result set can be quickly converted into a data paging query. A data paging CTE can easily be placed into a table valued function or a stored procedure. Multiple calls to a data paging CTE will reflect the data at the point in time that it is called. There is no persistent state between calls.
OFFSET and FETCH
SQL Server 2012 introduced the OFFSET and FETCH keywords to replace the need to use CTEs for data paging, as that is a cleaner and easier method in T-SQL.
A query using OFFSET and FETCH must also have an ORDER BY clause. Hard coded or dynamic values can be used to specify rows to be returned. The keywords ROWS and ROW are interchangeable.
For this example, we will take our query used in Step 1 in the data paging section and add a line at the end of the query that specifies the OFSSET and the number of rows to FETCH. The following example will return page 1 with a page size of 10:
(Include code, explanation, and results from page 128)
Now we take the OFFSET and FETCH version of our query and modify it to work similarly to the CTE version which allowed us to specify a page number and a page size:
(Include code, explanation, and results from page 129)
As we can see, the OFFSET and FETCH method of doing data paging may be easier than the CTE method.
(Maybe include execution plan to compare performance?)
Manipulating Data
CTEs can be used to insert data into tables, to update
data, or to delete data. While only SELECT
statements can be used inside of the CTE, but the outer query can be used to do INSERT, UPDATE, and DELETE actions.
Deleting Data
The CTE syntax does not allow for a DELETE statement to be used in any of the queries inside of a CTE, but a DELETE statement can run in an outer query to delete rows from the tables on the inside of the CTE. The DELETE statement would run on the records that were produced by the CTE.
Deleting from a CTE is interesting, in that a DELETE from the outside query of a CTE will delete from the table inside of the CTE. Instead of using a SELECT statement in the outer query, the DELETE statement can be used to delete from the table referenced inside of the CTE.
WITH CustomerCTE
AS (SELECT *
FROM Person.Person
WHERE LastName LIKE 'Williams')
DELETE FROM CustomerCTE;
DELETE with Multiple Base Tables
Deleting with an INNER JOIN inside of a CTE is not allowed and SQL Server displays an error message about not being able to delete from multiple base tables:
WITH CustomerCTE
AS (SELECT p.*
FROM Person.Person AS p
JOIN Person.EmailAddress AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE p.LastName LIKE 'Williams')
DELETE FROM CustomerCTE;

While deleting data is not allowed inside the CTE, a DELETE statement can be joined to a CTE as the deletion criteria.
Inserting Data
Just like with the DELETE statement, INSERT is not allowed to be used inside of a CTE. However, the INSERT statement can be used outside of the CTE to insert the results of the CTE into a table, temp table, or table variable.
Inserting data this way is used to quickly populate tables with test data in order to simulate a larger database size.
WITH NumbersCTE(N)
AS (SELECT 1
UNION ALL
SELECT 1 + N
FROM NumbersCTE
WHERE N < 1000)
SELECT N
FROM NumbersCTE OPTION(MAXRECURSION 1001);

If we needed to fill up a table variable with numbers for some testing purposes, the CTE could be built and then an INSERT statement could be used in the outer query to insert the results of the CTE into a table, table variable, or temp table. In the following example we have a table variable called @NumTabVar with a single column to hold numbers:
DECLARE @NumTableVar TABLE(n INT);
WITH NumbersCTE(N)
AS (SELECT 1
UNION ALL
SELECT 1 + N
FROM NumbersCTE
WHERE N < 1000)
INSERT INTO @NumTableVar(n)
SELECT n
FROM NumbersCTE OPTION(MAXRECURSION 1001);
SELECT *
FROM @NumTableVar;

This can be used to fill up a table rather than a table variable with ease. To do this, we just build a CTE and use the INSERT statement to insert the results into an existing table. While the INSERT statement is not allowed inside of the CTE, the results of the CTE can be inserted into a table, table variable, or temp table.
Updating Data
The UPDATE statement is not allowed inside the CTE but updating the CTE from the outside query updates the base table referenced inside of the CTE. In other words, while the UPDATE statement is not allowed inside the CTE, the results of the CTE can be used in an UPDATE statement. When the UPDATE statement is run against the CTE it changes the base tables inside of the CTE. The way this is used is to write a CTE then run the UPDATE statement against the CTE.
In the following example we update the Customer table in the JProCo database with a CTE. This could technically be done as a single statement without the CTE, but we are using a CTE here for the purpose of demonstration.
WITH CustomerCTE
AS (SELECT *
FROM Person.Person
WHERE LastName LIKE 'Williams')
UPDATE CustomerCTE
SET
LastName = 'Willie';

UPDATE with Multiple Base Tables
While deleting data from CTEs didn’t work with multiple base tables involved, updating data does work with multiple base tables as long as only one base table is being changed. The following code provides an example of this:
WITH CustomerCTE
AS (SELECT p.*,
e.EmailAddress
FROM Person.Person AS p
JOIN Person.EmailAddress AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE p.LastName LIKE 'Willie')
UPDATE CustomerCTE
SET
EmailAddress = 'Willie';
When the query is run, the UPDATE is applied to the SalesInvoice table. We can check this by looking at the Comment column by grabbing the original CTE and just selecting from it rather than doing an update:
WITH CustomerCTE
AS (SELECT p.LastName,
e.EmailAddress
FROM Person.Person AS p
JOIN Person.EmailAddress AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE e.EmailAddress LIKE 'Willie')
SELECT *
FROM CustomerCTE;
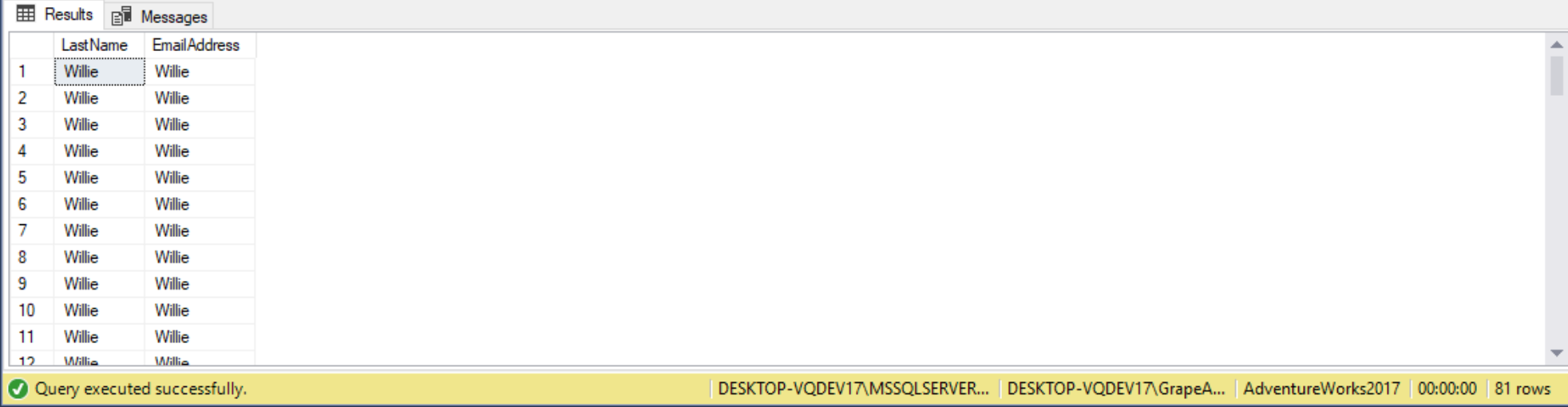
If we modify the UPDATE statement to attempt to update columns in two base tables the UPDATE will fail and an error message is shown, as in the following example:
WITH CustomerCTE
AS (SELECT p.LastName,
p.Title,
e.EmailAddress
FROM Person.Person AS p
JOIN Person.EmailAddress AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE e.EmailAddress LIKE 'Williams')
UPDATE CustomerCTE
SET
EmailAddress = 'Willie',
Title = 'Willies Toys';

As previously mentioned, it’s possible to UPDATE a base table in a CTE as long as only one is being updated.
UPDATE with No Base Tables
If we run an UPDATE statement against a CTE with no base tables, the query will produce an error, like in the following example:
WITH NumbersCTE(N)
AS (SELECT 1
UNION ALL
SELECT 1 + N
FROM NumbersCTE
WHERE N < 1000)
UPDATE NumbersCTE
SET
N = N + 1;

We are using a recursive CTE, but SQL Server throws the error message about a derived table not being updatable. A CTE that doesn’t reference any base tables can’t be updated, since there are no underlying tables to update. A CTE with one or more base tables can be updated.
CTEs in Functions, Stored Procedures, and Views
Here we will explore how CTEs will be used on functions, stored procedures, and views.
Table Valued Functions
A table valued function takes a set of input parameters and returns a table as the results of the function, and this table can be used anywhere that a normal table could be used.
The following query is an example of a basic table valued function:
(Include code, explanation, and example from page 147)
After the function is created, it can be executed by being referenced in a SELECT statement, like follows:
(Include code, explanation, and example from page 147)
We then add a CTE to the table valued function. The results of the CTE must be inserted into the return table variable so that the results can be used. In order to create the table valued function containing a CTE, we will reuse a CTE we used earlier:
(Include code, explanation, and example from page 148)
We start by building a simple framework for the table valued function that takes the @DepartmentID as the parent element for the function. This differs from the CTE above in that we will be looking for the hierarchy below a specific node, rather than the entire tree hierarchy.
(Include code, explanation, and example from page 148)
We then copy and paste the CTE into the function, inserting the results into the @OutputTable variable, and modifying the CTE to start at a specific node than at the root of the hierarchy.
(Include code, explanation, and example from page 149)
To execute the function, we include it in a SELECT statement, keeping in mind the ORDER BY inside the function doesn’t necessarily impact the output from the function, so we include an ORDER BY in the query that calls the function, like follows:
(Include code, explanation, and example from page 149)
The output looks similar to the original CTE results, except in this case the function gives us the ability to show part of the hierarchy if needed, rather than the full tree. For instance, if we want to show the sub-categories of the Tents category, we pass 5 into the function (since 5 is the id for the Tents department):
(Include code, explanation, and example from page 150)
The CTE is recursive, and there is a need to modify the default MAXRECURSION which is done in the SELECT statement calling the function, not in the CTE inside of the function. A code example of this is as follows:
(Include code, explanation, and example from page 151)
We can run the ShowHierarchy table valued function for any department we want by passing in another parameter.
If there is a CTE that is commonly going to be used and needs to take different parameters, it may make more sense to create it as a table valued function. Having a CTE in a table valued function gives us the ability to reuse the CTE without having to copy and paste that CTE from one place to another.
Scalar Functions
A scalar function is a type of function that only returns a single value. For example, the following scalar function takes two numbers as input and adds them together, returning the result of the addition:
(Include code, explanation, and example from page 152)
We use a SELECT statement to call the function, as follows:
(Include code, explanation, and example from page 152)
To see how to use a CTE in a scalar function, we will use the same departmentsCTE used in the table valued function demo, with the goal of returning the tree path for any single department given the department id is passed in. To do this, we will calculate the tree path for all the departments and then filter the results down to a single department.
The outline for our scalar function is as follows:
(Include code, explanation, and example from page 152)
At this point all the function will do is return an empty string. We add in the CTE to get the tree path for the department that we are looking for. We use the same CTE as we did for the table valued function demo, but first we set the result into a variable that is later returned, and we also filter the result path to a single id and use the TOP 1 expression to avoid getting more than one result. The updated code for the scalar function is as follows:
(Include code, explanation, and example from page 153)
Now we can execute the functions with a variety of parameters, like follows:
(Include code, explanation, and example from page 153)
As we see, there are four results, one for each time GetTreePath was called.
Similar to table valued functions, if a CTE is recursive and requires more than 100 levels of recursion the MAXRECURSION needs to be set. MAXRECURSION should be modified in the SELECT statement calling the function, not the CTE inside of the function, like follows:
(Include code, explanation, and example from page 154)
CTEs can be used in scalar functions as long as the CTE is modified to return only a single value that can be used as the result of the function.
Stored Procedures
Similar to CTEs in functions, CTEs can also be used in stored procedures. Stored procedures have more capabilities than functions. For example, INSERTs and DELETEs can be done in a stored procedure, but not inside of a function. A stored procedure can modify data and return zero, one or multiple result sets. Transactions can also be used in stored procedures, but not in functions.
For the stored procedure example, we will be using the same departmentsCTE used in the two previous examples. The basic outline for our stored procedure is as follows:
(Include code, explanation, and example from page 155)
Now we add the departmentsCTE CTE into the stored procedure:
(Include code, explanation, and example from page 155)
We use the EXEC command to execute the stored procedure, as follows:
(Include code, explanation, and example from page 155)
Here all the stored procedure is doing is displaying the same thing as the original CTE. Note that a stored procedure can return more than one result set. The follow example shows how this might work with multiple CTEs in a stored procedure:
(Include code, explanation, and example from page 156)
We use the EXEC command to execute the stored procedure, as follows:
(Include code, explanation, and example from page 156)
There are two result sets returned from the stored procedure in the SSMS window.
As we have seen, it can be easy to add a CTE to a function or stored procedure. If it makes sense to write a query as a CTE, and it also makes sense to write the query in a stored procedure, then it makes sense to write that query as a CTE to be added to the stored procedure.
Views
A view is a way to save a query to use at a later time, and if it makes sense to put a specific query into a view, it makes just as much sense if that query uses a CTE.
Using a CTE in a view is the exception to the rule that the line before the WITH clause requires a semicolon. The following is an example of a CTE saved as a view:
(Include code, explanation, and example from page 159)
When using the same CTE over and over again, it may be worth saving it as a view.
Common Use Cases
There are many things we can do because of a CTE, such as: finding holes in patterns, finding duplicates, and string parsing just to name a few.
Finding Holes in Patterns
Finding holes in patters can be done in a single query with a CTE. This gives us the ability to have a list of possible numbers to use in a LEFT OUTER JOIN with exclusion to track down what is missing from a list of numbers. Suppose our database team wants to schedule database maintenance, but the management team doesn’t want to lose out on any of the revenue from the online store. We’re tasked to find the hours of the day when the least amount of orders is placed with the intention of scheduling a regular maintenance window.
We begin our query by seeing what data is available in the SalesInvoice table which holds all the orders:
(Include code, explanation, and results from page 165.)
We then simplify the results by selecting just the OrderDate column with the order date and time:
(Include code, explanation, and results from page 165.)
We then extract the hour of the day to use and group by the hour with a count of how many orders occurred during that hour. This should give us the best time to schedule the maintenance:
(Include code, explanation, and results from page 166.)
As we can see, 11:00AM, 3:00AM, or 21:00 (9:00PM) are the hours with the fewest orders.
In this case we didn’t need CTEs because there weren’t any holes in the pattern. All hours of the day had at least one order. What if there was a time of the day when no orders occurred, what would be see in the results? Would we be looking at a good time for our maintenance window? To test this, we look at a smaller set of data, for example for orders before February 1, 2006. When we run the query, we are looking at about 1 month of data:
(Include code, explanation, and results from page 166.)
Here, it may appear that 6:00AM, 7:00AM, 9:00AM, and a few other hours of the day had the fewest orders. In fact, this is incorrect because those hours are the hours with the fewest orders when only considering the hours that had orders. There are indeed some hours with zero orders. So how do write a query that also shows the hours with zero orders? One option is using a CTE.
CTE as an alternative to the Numbers Table
A “Numbers Table” is essentially a table with two columns: one column is an integer and the other was a unique-identifier type, similar to the previous example. A CTE is a much more elegant solution than a numbers table, and it should overall perform better while not adding any storage overhead. A CTE is a great alternative to a Numbers Table for small sets of numbers but doesn’t work well for larger sets.
To replace a numbers table, we start with a CTE declaration and the anchor query, which in this case we want to start with 0:
(Include code, explanation, and results from page 168.)
We then add the recursive part which will generate the numbers 1 to 23, and when combined with the 0 from the outer query we get the numbers 0 to 23:
(Include code, explanation, and results from page 168.)
Now we select the numbers from the CTE:
(Include code, explanation, and results from page 168.)
We add a second CTE called OrderHours with the earlier query that find the hours of the day without any orders:
(Include code, explanation, and results from page 169.)
We use a RIGHT JOIN to get the results that we are looking for. In this example, the RIGHT JOIN takes all the rows from the Numbers CTE and matches them up with the rows from the OrderHours CTE if they exist which produces the results that we are looking for.
(Include code, explanation, and results from page 169.)
Based on this query, we can now get a realistic view of when the fewest orders are being placed using a CTE and a RIGHT JOIN.
The same Numbers CTE can be used in many generic cases, for instance if we wanted to generate the numbers 1 to 1000, we can do that as follows:
(Include code, explanation, and results from page 170.)
Notice that we specify OPTION (MAXRECURSION 1000) in order to avoid an error when the recursion went deeper than the default of 100 levels.
Dates of the Year (More Holes)
Holes in patterns in date ranges can be found by first creating a list of all dates in a range with a recursive CTE, then using that to find the dates that are not in another list of dates with exclusion to show only the dates not in the original query. In this example we build a calendar and need details of all the dates in a year. This would be useful if there was a need to find dates of the year that are not in the database.
We build a CTE that starts with January 1st, and then recursively fine all of the days of the year until December 31st. We first declare the Dates CTE and build the anchor query starting at January 1st,2013:
(Include code, explanation, and results from page 171.)
We then add in the recursive part which continues while the data is less than January 1st,2014. We combine this with a query to select from the CTE to get the following code:
(Include code, explanation, and results from page 172.)
In order to fix the error from the above code, we just need to add the MAXRECURSION option into the query as follows:
(Include code, explanation, and results from page 172.)
This query can be used for many possible needs from finding holes, to building a calendar. This could be done with T-SQL script instead of a CTE, but the CTE solution may be easier to work with an maintain over time.
Finding and Removing Duplicates
Finding duplicates in SQL Server is relatively straight forward, using a SELECT statement and GROUP BY clause. For example, we can use the Customer table to check for duplicate customer accounts that were accidentally entered over time. One way to do this would be to look at our customer list and find all the duplicate names, as with the following query:
(Include code, explanation, and results from page 173.)
A typical philosophy on deleting duplicates is to keep the record with the lowest id. Since this example doesn’t give an id number we will super impose our own numbering system by using the ROW_NUMBER() function. For example, in the case of Linda Adams there will be four numbers with the numbers 1 through 4. If we want to keep record 1 but get rid of the rest, we will delete all Linda Adam rows above 1, as follows:
(Include code, explanation, and results from page 174.)
To delete the duplicates, we add in a DELETE statement and the entire query starts to get larger:
(Include code, explanation, and results from page 175.)
This code deletes duplicates, but it also leaves the lowest duplicate number as the remaining record.
Another way that might be cleaner to follow would be to do the DELETE using a CTE. The DELETE with the CTE has fewer derived tables, and fewer levels of indentation, and would be considered cleaner code to follow and understand:
(Include code, explanation, and results from page 175.)
The CTE can be used to find the right duplicates to remove. This becomes even more valuable when the CTE can clean up complex derived tables or in a case where there were many more filters to be included in the WHERE clause.
As we can see, with a CTE using the ROW_NUMBER() function and the OVER clause it is possible to find duplicates, and to find just the later occurrences of those duplicates so they can be deleted.
String Parsing with CTEs
Splitting of strings in T-SQL is what a majority of the string parsing work is used for. There are several functions created using CTEs that keep turning up as a need.
Recursive String Parsing
The concept behind string parsing CTEs is that they are recursive, and through each level of recursion they break up part of the string into a row in the result set. The recursive split function would break off one word at a time and return a result set containing rows based on a delimiter.
The first step in building this split CTE would be to declare two variables: one to hold the string to be split and the other to hold the delimiter character.
We then add the recursive query, which in this case is intended to find the next instance of the delimiter character after the last occurrence. The recursive part of the query continues to be called recursively until the separator character is not found.
Finally, we can test the CTE by selecting everything from it. The complete code is as follows:
(Include code, explanation, and results from page 178.)
What the CTE result is showing is the position of each space (delimiter) in the string. On each row, we are extracting the substring starting at the lastPol plus 1 since the substring is at index 1 to the pos. The very last row is the one special case we need to account for, which has a 0 for pos, indicating that there are no more spaces and therefore no more words. The 8000 is used as a theoretical maximum length that could fit into a VARCHAR(8000) variable. This could be modified to work with a VARCHAR(MAX), which would require the 8000 in the code to be modified to be larger than the string being parsed. That end situation is accounted for with the T-SQL code that follows:
(Include code, explanation, and results from page 179.)
The final step is to wrap the CTE into a table valued function so that it can be reused daily and won’t have to be rewritten each time.
(Include code, explanation, and results from page 180.)
In summary, the steps we have taken are:
- Declare some variables to work with.
- Declare the CTE and give it a name.
- Create the anchor query to find the first separator character.
- Create a recursive query to find the rest of the separator characters.
- Build the outer query using substring to rip the parts out of the input string.
- Wrap it all in a function.
Once the function has been created, it can be called as follows:
(Include code, explanation, and results from page 180.)
Since in this example there were only nine words, the default MAXRECURSION wasn’t reached and wasn’t needed.
There are many ways a query like this can be used. One example where we can apply this is when we’re trying to figure out which words were used the most. Imagine the following being used with a larger string:
(Include code, explanation, and results from page 181.)
As we can see, this is another handy way to add new functionality to a database with a CTE.
Parsing a Query String into a Table
There may be a business case for the parsing of a query string in the database. For example, a query string can be part of a URL in a web browser. Web pages use the query string as one option to pass data from one page to another, and to keep track of things. The query string is made up of a key and value pair separated with an equal sign. Multiple pairs are separated with the ampersand (&) character. For example: https://www.amazon.com/Python-Data-Science-Handbook-Essential-ebook/dp/B01N2JT3ST/ref=sr_1_3?keywords=Data+Science&qid=1555783645&s=gateway&sr=8-3
(Go to webpage and highlight the key-value pairs and &)
Suppose we need to parse the query string and return each key-value pair as a row. We also need a column for the key and a column for the value.
We use a table valued function (named SpitQueryString) to build a function to parse the query string and return the results. It will take one parameter called @s which will hold the input query string. The first step is to declare the function and start the CTE with an anchor query. The anchor query will find the first occurrence of the “&” character, to be used to break out the first key-value pair. We then add the recursive query to find all of the other “&” characters and to continue recursively until the end of the string. Next, we split the key-value pairs based on the position of the equal sign (delimiter). To so this, we add a second CTE into the function, named pair_CTE. This CTE is not recursive because it is only breaking out a single equal sign from each query. The final step in building the function is to break out each chunk of the input string into the key and value columns. The complete code is as follows:
(Include code, explanation, and results from page 185.)
After building the function, we can call it by first declaring the query string variable. We leave off the MAXRECURSION option because it is unlikely that there will be more than 100 key-value pairs in our example.
(Include code, explanation, and results from page 185.)
As we can see, we can use T-SQL to parse a browser query string with a CTE if the string gets broken down part by part.
CTE Performance Considerations
Table size, depth of recursion, the number of CTEs, nesting and other factors can have a small or very large impact on overall database performance. The following three areas are what should be used together when analyzing CTE performance: Actual Execution Plan, Statistics IO, and Statistics Time.
Performance Overview
Actual Execution Plan
The actual execution plan in SQL Server is a way of turning on a type of monitoring that keeps a detailed explanation of what SQL Server actually done when executing any given query. For any query in SSMS the actual execution plan can be turned on or off from the Query menu, or alternatively by the CTRL + M keyboard shortcut.
Turning on the actual execution plan only applies to the current query window that is open. Once turned on, it stays on until closing that query window, or turning off the Actual Execution Plan.
In the execution plan each of the steps that are needed to run the query are shown with a percentage of the overall cost. We can use the percentages to learn what the big cost items are. The term “cost” is an overall value that generally indicates the amount of work required to do that step and is usually correlated to the amount of time needed to run the query.
If there are two queries in a batch, the results from both will be shown in the Execution Plan tab after we run the code. Comparing them shows where the performance problems are and which costs more. Let’s examine the differences between the following two queries:
--Query 1 SELECT TOP (10) * FROM Sales.Customer; --Query 2 SELECT * FROM Sales.Customer;
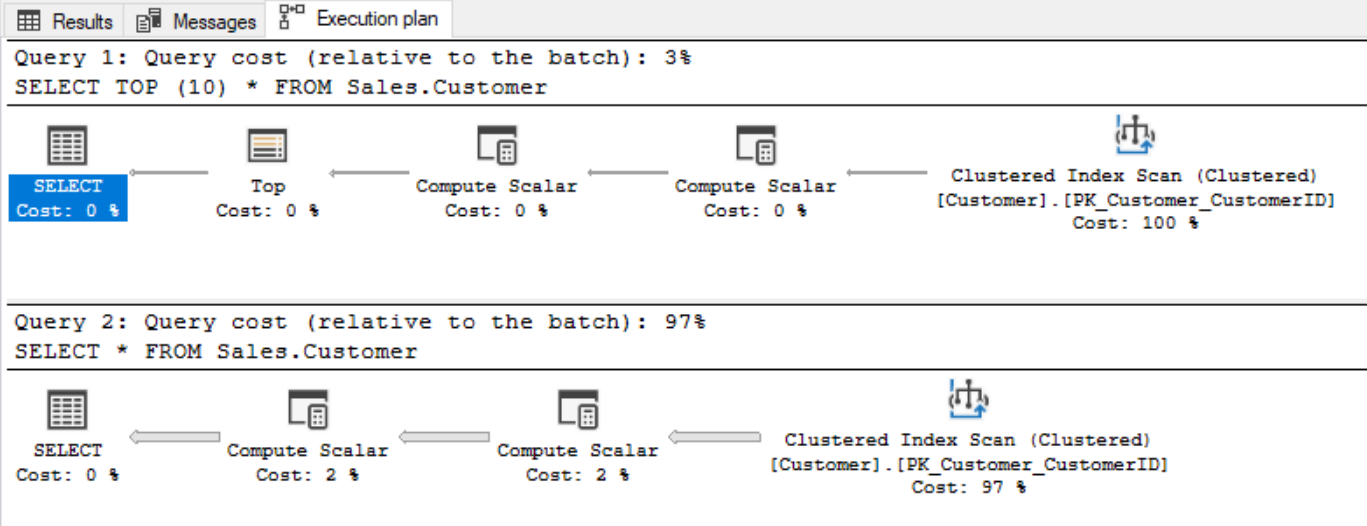
When we compare the two queries we see that the second query accounts for 97% of the cost, whereas the first one accounts for 3% of the cost.
Statistics IO
Statistics IO is an option that can be turned on when a query is run in SSMS that displays the number of reads and writes that occur as the result of a query running. The results are displayed in the Messages window. To turn statistics IO on, we type the SET STATISTICS IO command, like follows:
SET STATISTICS IO ON; --Query 1 SELECT TOP (10) * FROM Sales.Customer; --Query 2 SELECT * FROM Sales.Customer;

The statistics IO gives details about the number of scans and several different types of reads. From here we can learn more about what the query might be doing. Reads refer to the number of 8K data pages read.
The three types of reads are:
- Logical Reads: Data pages that are already in memory are being read. Logical reads are generally the fastest read type of the three.
- Physical Reads: Requires a data page to be loaded from disk into memory. These are the slowest of the read types.
- Read-Ahead Reads: The number of pages placed into the cache. An optimized version of the physical read.
From this output we can assess how much data is being accessed or moved from disk for a query.
Statistics Time
Statistics Time is similar to Statistics IO in that it measures what the query is doing, but in this case it is measuring the amount of time spent on different tasks. For example, the following ugly query is designed to be slow, so let’s look at the times for this:
SET STATISTICS TIME ON;
SELECT *
FROM person.person AS p
JOIN Sales.SalesOrderHeader AS soh ON p.BusinessEntityID = soh.SalesPersonID
WHERE SUBSTRING(p.FirstName, 1, 1) = 'J'
ORDER BY CAST(soh.CreditCardID AS VARCHAR(MAX));
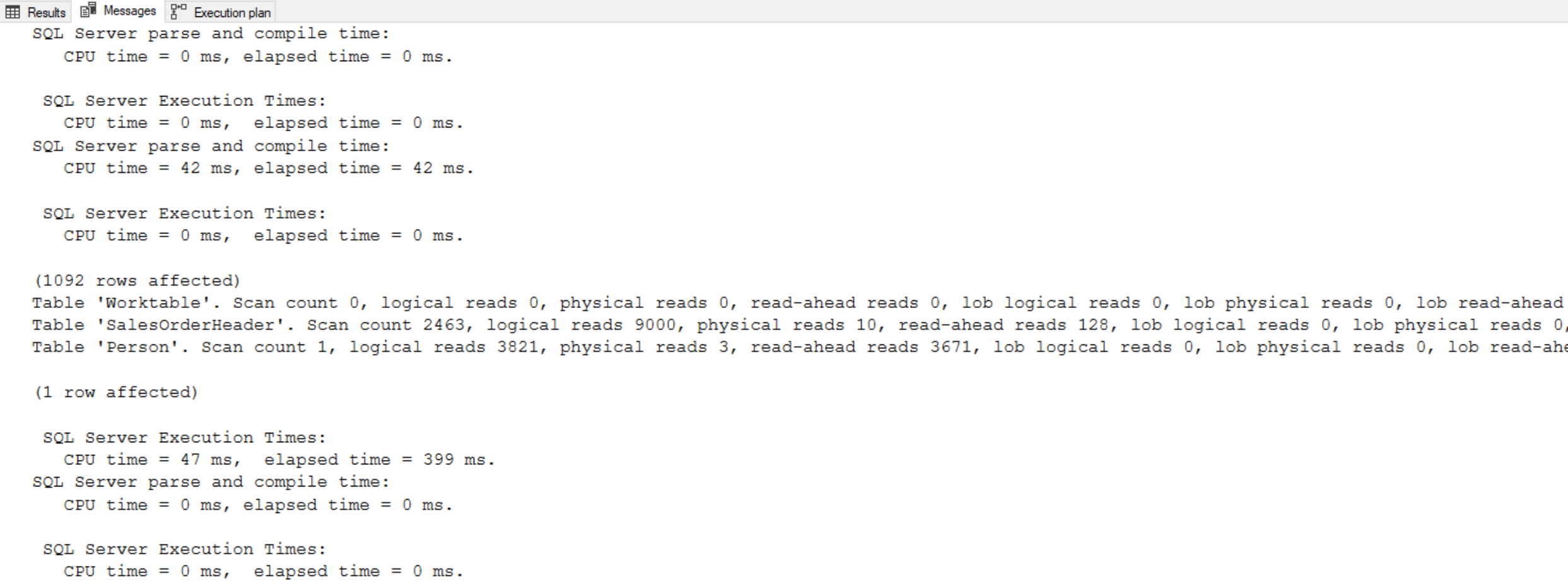
The output shows the CPU time used and the elapsed time used. The difference between CPU time and elapsed time usually indicates waiting on something such as IO. It is suggested to use both Statistics Time and Statistics IO on the same query, like follows:
SET STATISTICS IO, TIME ON;
SELECT *
FROM person.person AS p
JOIN Sales.SalesOrderHeader AS soh ON p.BusinessEntityID = soh.SalesPersonID
WHERE SUBSTRING(p.FirstName, 1, 1) = 'J'
ORDER BY CAST(soh.CreditCardID AS VARCHAR(MAX));
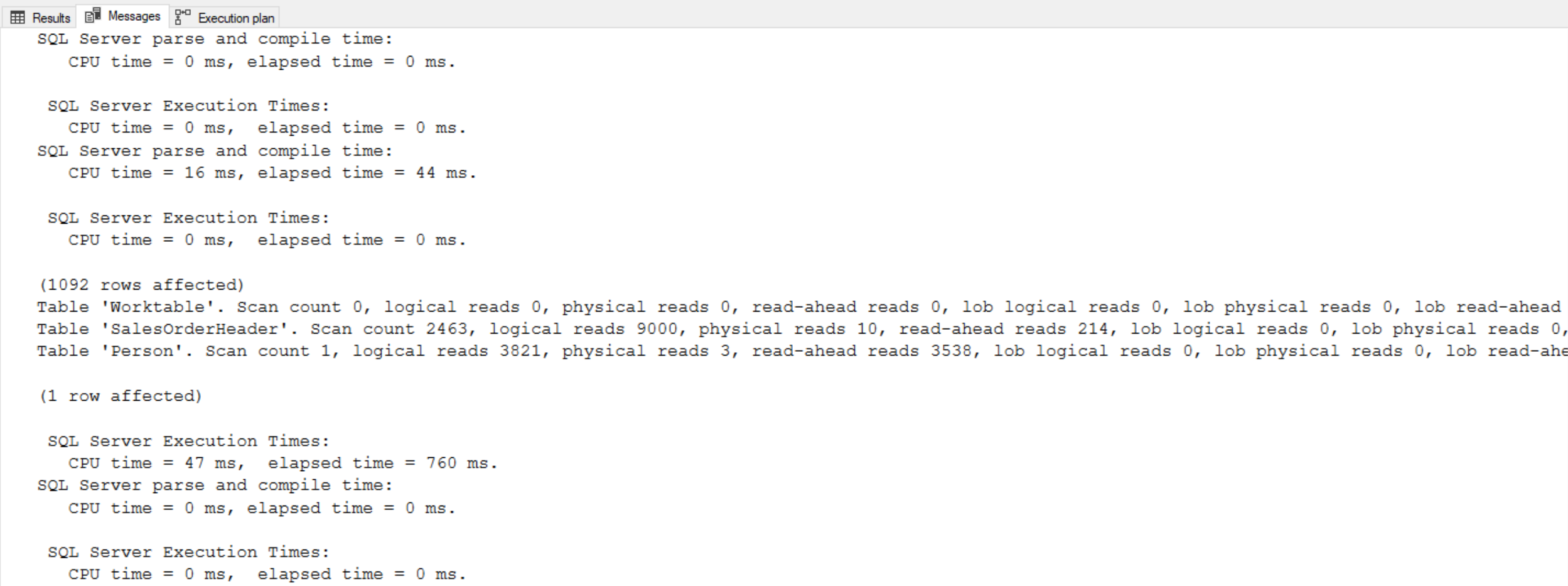
Non-Recursive Performance
Some non-recursive CTEs perform exactly the same as the non-CTE version of the implementation, and some have performance implications as the queries get big.
Multiple References to a Single CTE in a Query
Here we will analyze an earlier query to determine whether multiple references to a single CTE are run once or multiple times. The question here is how often will the SELECT statement inside the departmentsCTE be run.
To find out, we turn on the Actual Execution Plan and Statistics IO. We create a query that references a CTE once, and another query that references the CTE twice:
USE Northwind;
SET STATISTICS IO, TIME ON;
--Single CTE reference
WITH ManagerCTE(EmployeeID,
City,
ReportsTo)
AS (SELECT EmployeeID,
City,
ReportsTo
FROM Employees)
SELECT q1.EmployeeID
FROM ManagerCTE AS q1
WHERE q1.ReportsTo IS NULL;
--Two CTE references
WITH ManagerCTE(EmployeeID,
City,
ReportsTo)
AS (SELECT EmployeeID,
City,
ReportsTo
FROM Employees)
SELECT q1.EmployeeID,
q2.EmployeeID AS Boss
FROM ManagerCTE AS q1
JOIN ManagerCTE AS q2 ON q1.EmployeeID = q2.ReportsTo
WHERE q1.ReportsTo IS NOT NULL;
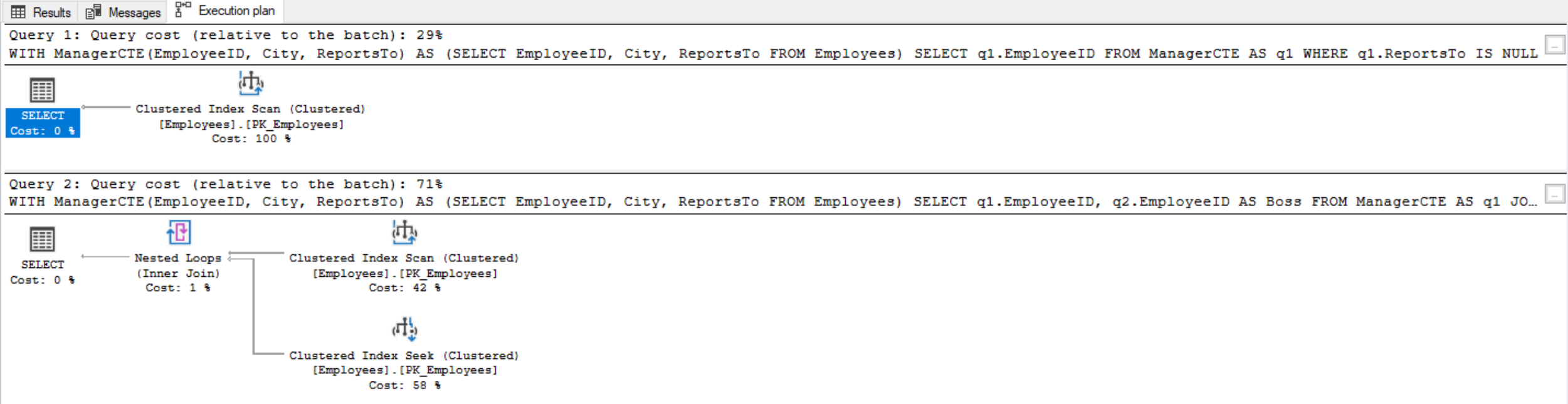
In the first execution plan there is a single table scan on Departments which indicates that the departmentsCTE CTE is only run once. In the second execution plan it shows two table scans on Departments showing that departmentsCTE is being run twice. Statistics IO shows a single scan on the Departments table in the first query, and two scans on the Departments table in the second query. Based on the evidence shown here between the execution plan and the statistics IO, we can see with certainty that the CTE query is being run multiple times, once for each time it is called. The same example can be expanded to include a third and a fourth reference to the same CTE and the evidence will show that the Departments table query is run three or four times (respectively) in those cases.
The analysis of multiple references of a CTE proves that the query inside the CTE is run once for every time that it is referenced, and there is no stored result set that can get reused to improve performance.
CTEs vs Derived Tables
Earlier we mentioned that the performance would be the same between a derived table query with multiple references and a CTE query with the same multiple references. For example, the following examines the execution plans and statistics IO of a derived table query and a CTE version of the query:
SET STATISTICS IO,TIME ON;
--Derived Tables Query
SELECT q1.EmployeeID,
q1.Title,
q2.EmployeeID,
q2.Title AS Boss
FROM
(
SELECT EmployeeID,
Title,
ReportsTo
FROM Employees
) AS q1
JOIN
(
SELECT EmployeeID,
Title,
ReportsTo
FROM Employees
) AS q2 ON q1.ReportsTo = q2.EmployeeID;
--CTE Query
WITH ManagerCTE(EmployeeID,
Title,
ReportsTo)
AS (SELECT EmployeeID,
Title,
ReportsTo
FROM Employees)
SELECT q1.EmployeeID,
q1.Title,
q2.EmployeeID,
q2.Title AS Boss
FROM ManagerCTE AS q1
JOIN ManagerCTE AS q2 ON q1.ReportsTo = q2.EmployeeID;
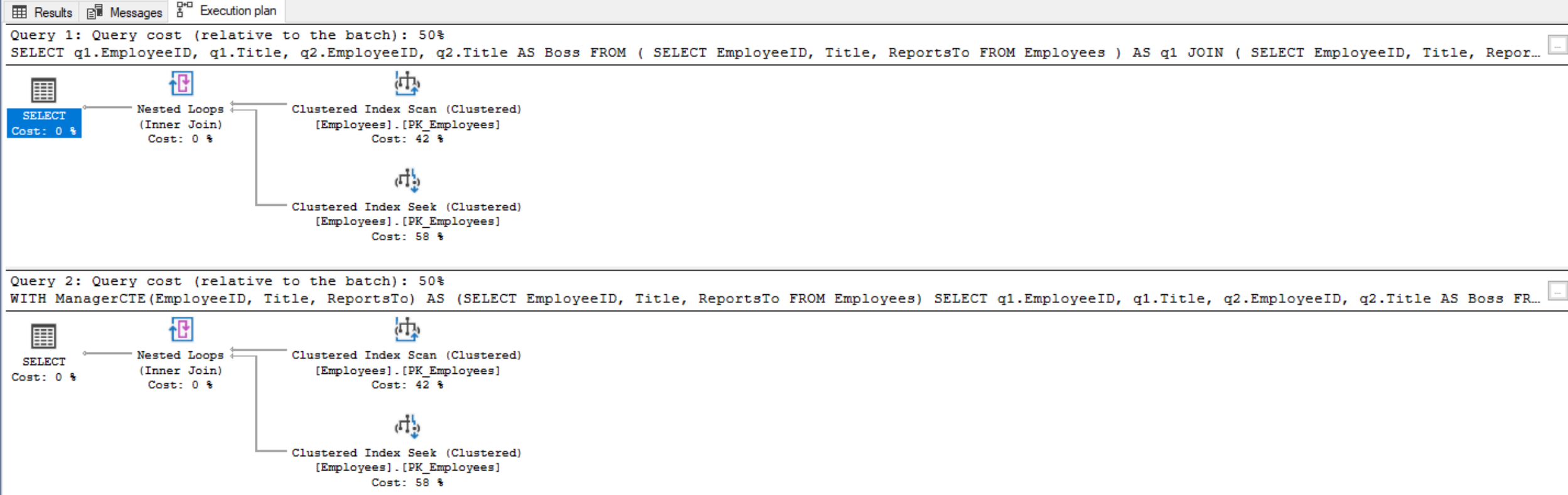

The output of the execution plan shows the CTE version of the query accounted for 50% of the cost, and the derived table version of the query producing the same results accounted for 50% of the cost. The execution plan also shows the exact same plan between the two queries, and it shows that the table scan on the Departments table is also being run twice. Overall the execution plan is showing that these queries perform identically. The statistics IO comparison between the two queries show they have the exact same number of reads and scans. If the same comparison is done with larger queries, or with more references to a CTE and a derived table, the results continue to show that the behavior is exactly the same between the two. So, it is safe to conclude that non-recursive CTEs and derived tables perform identically, and there is no performance gain with one over the other. The performance of a recursive CTE compared to the same query written with derived tables will be similar. The decision to use a CTE versus a derived table should be made based on code reuse and readability, not on performance.
CTEs vs. Views
When choosing between a CTE and a view the analysis shows that they perform exactly the same, as long as the query inside of the CTE is the same as the query inside of a view. One of the hazards to watch out for with a view is that the view may be doing extra work that is not needed or joining to tables that aren’t needed. If the view is identical to the CTE, they perform exactly the same. The following code builds the view to be used in our comparison demo:
CREATE VIEW ManagerView
AS
SELECT EmployeeID,
Title,
ReportsTo
FROM Employees;
GO
SET STATISTICS IO ON;
--CTE version of the query
WITH ManagerCTE
AS (SELECT EmployeeID,
Title,
ReportsTo
FROM Employees)
SELECT q1.EmployeeID,
q2.EmployeeID AS Boss
FROM ManagerCTE AS q1
JOIN ManagerView AS q2 ON q2.EmployeeID = q1.ReportsTo
WHERE q1.ReportsTo IS NOT NULL;
--View version of the query
SELECT q1.EmployeeID,
q2.EmployeeID AS Boss
FROM ManagerView AS q1
JOIN ManagerView AS q2 ON q2.EmployeeID = q1.ReportsTo
WHERE q1.ReportsTo IS NOT NULL;
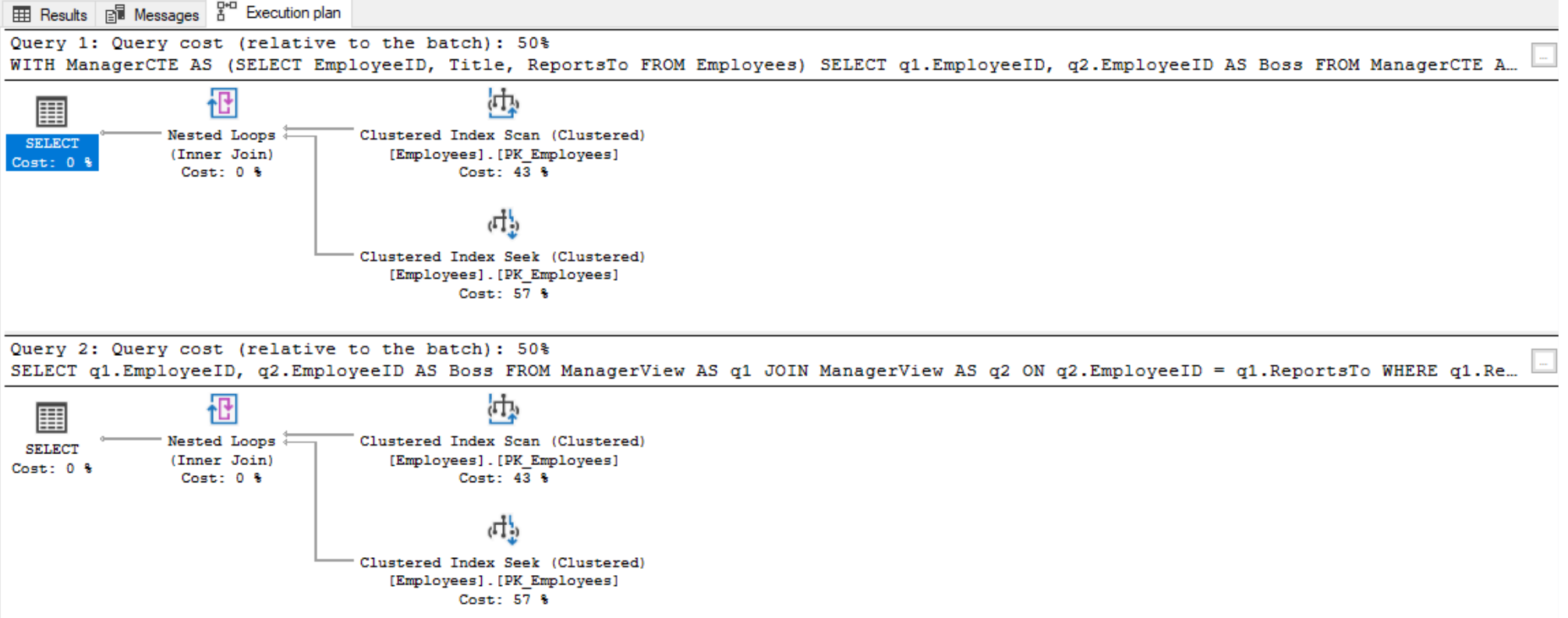

When comparing a CTE to the view there is no difference in the cost between the two as shown by the actual execution plan. When running the same comparison for larger tables similar results will be shown. The scans counts, logical reads, and all other reads are exactly the same between the two queries. When running the same tests for small tables, large tables, and joins, we find that a view compared to a CTE performs the same (as long as they are asking for the same data).
Multiple CTEs in a Query
How many CTEs in a query are too many? There are two ways to know:
- The query gets too big to comprehend. Probably after a few dozen CTEs maximum.
- The query produces an error from SQL Server stating that the server is out of memory, or out of stack space.
The following error message will be shown if there are too many CTEs in a query. This error was produced when a query with 32,000 CTEs was attempted to be run:
(Include results from page 204)
The error below was produced from a query with 4000 CTEs:
(Include results from page 204)
For SQL Server 2017, the maximum number of CTEs in a single query appears to be only related to the amount of memory available.
The answer to how many CTEs can be in a query should be answered as far more than would anyone ever really need to.
With multiple CTEs in a query, the overall performance is determined by what the CTE queries are doing. There is not much performance overhead associated with having many CTEs in a query, as long as the CTE queries are efficient.
Nested CTEs
While there is no performance overhead in having multiple CTEs in a query, this is only true unless those CTEs are nested.
Nested CTEs with just a couple of levels of nesting are typically not a problem. The following is a demo of what happens as we nest CTEs deeper and deeper:
(Include code, explanation, and results from page 205)
For SQL Server 2017, the maximum level of nested CTEs appears to be only related to the amount of memory available. The amount of memory being used by nested CTEs is non-linear. As the level of nesting gets deeper, the amount of memory per level goes up, and it goes up fast.
Nested CTEs are very efficient in terms of time and memory usage when they are not using extreme levels of nesting. For instance, up to 5000 levels of nesting doesn’t use much memory. However, even if we have significantly more memory, a CTE with deep enough level of nesting will eventually use all of the memory available. It is very easy to use up all the available memory in SQL Server with a single nested CTE with a few thousand levels of nesting. It is very unlikely that anyone would need to write a query that uses hundreds of levels of nested CTEs.
Recursive Performance
For this recursive CTE demo, we will be using the following tree path CTE used earlier:
(Include code, explanation, and results from page 209)
This tree path CTE will be compared to a non-CTE query that produces similar results by building each level of the hierarchy in a different query and joining them together with a UNION ALL. This is certainly a more complex and harder to maintain query than the CTE version, but how does it really compare based on performance?
(Include code, explanation, and results from page 209)
The first thing to note on the Actual Execution Plan is the difference in the query cost. The query cost of the recursive CTE is 7% of the entire batch, and the cost of the non-CTE query is 93% of the batch. The non-CTE version has 13 times the cost of the recursive CTE. While the cost is not always directly proportional to the overall performance, it is generally a good indicator of how things compare.
Next, we do a comparison between statistics time and the IO.
(Include execution plan from page 212)
In the screenshot the top red block is the recursive CTE, and the bottom red block is the non-CTE query. The recursive CTE took 10ms, and the non-CTE query took 27ms. The scan count between the two is 4 and 15, or almost 4 times as many table scans in the non-CTE query. The logical reads is higher in the CTE version.
After comparing the two options, here are the benefits of using the CTE version of the query:
- The CTE version has a cost 1/13th that of the non-CTE version.
- The CTE version uses less table scans than the non-CTE version.
- The CTE version runs in 10ms rather than the 27ms it takes the non-CTE version to run.
Even though the CTE version of the query has more logical reads, overall it performs much faster than the non-CTE version. The benefit with a recursive CTE is that the query doesn’t need to account for specific depths of hierarchy. With non-recursive solutions the number of levels in the hierarchy needs to be handled in the query.
Deep Recursion Performance
The following CTE will be used as a demo to analyze deep recursion:
(Include code, explanation, and results from page 213)
Statistics IO and statistics time show that to generate 100 numbers it takes 61ms, two table scans and 607 logical reads. Checking the overall memory shows there is no noticeable increase in memory used by SQL Server. We change two lines of the previous code to see how the query performs if the numbers being generated is bumped from 100 to 1000:
(Include code, explanation, and results from page 214)
For 1000 numbers, it takes 43ms, but the query used 6007 logical reads. Checking the overall memory shows there is still no noticeable increase in the memory used by SQL Server.
To generate 10,000 numbers, the elapsed time is 124ms, and still no noticeable increase in the memory used, but the logical reads jumped to 60,007. Overall, recursive CTE queries in T-SQL perform well, and scale well with deep recursion. The same tests were applied to 1,000,000 rows which still performed fairly well with 8 seconds of run time for 1 million rows. The performance of recursive CTEs appears to be linear allowing for some very massive scaling of recursive functionality.
CTE Data Paging Performance vs. OFFSET-FETCH
As with any performance related topic the overall performance of these two methods may vary depending on the specific SQL Server configuration, or the size and design of specific tables involved in the query. If using a version of SQL Server older than 2012, CTE for data paging is the only option as OFFSET-FETH were not available.
The following two queries are used to compare the performance between CTE data paging and the newer OFFSET-FETCH clauses. In all of the tests there was generally the same amount of IO, and the costs for both were somewhere between 48% and 52% when comparing. The difference that was shown between the two was on the run time:
(Include code, explanation, and results from page 216)
The CTE query had the same number of scans and reads as the OFFSET-FETCH implementation. When similar queries are run against tables with millions of rows the statistics IO comes out the same. The following execution plan shows that the cost of the CTE version (bottom) is 51% of the entire batch whereas the cost of the OFFSET-FETCH implementation (top) is 49% of the entire batch.
The next comparison between the CTE and OFFSET-FETCH implementations is the statistics time comparison.
(Include results from page 218)
The elapsed time is 39ms for OFFSET-FETCH and 86ms for the CTE implementation. The CTE version takes over twice as long to run as OFFSET-FETCH. If we run the same queries again and again, the numbers bounce around and sometimes the CTE is faster. This indicates that the data set being used is not statistically significant enough. So next, we take a look at it again with more rows, using the following script that will double the number of rows in the Customer table each time it is run:
(Include code, explanation, and results from page 218)
When we run the script five times, we end up with 24,800 rows in the table rather than the original 755. When the original queries are run again, they are closer to the same results, usually showing up between 40 to 50ms.
When we run the script five more times to end up with 793,600 rows, there is still no real difference. The first time it is run it takes about 125ms plus or minus 10 for each, then the second run takes about 50ms plus or minus 5 for each. No significant difference. Checking the statistics IO still shows no difference. When we run the doubling script five more times to get 25,395,200 rows the numbers still come back almost the same. We adjust the page we are looking for to see how that changes things, as follows:
(Include code, explanation, and results from page 219)
At this point on repetitive runs of the two queries, the OFFSET-FETCH implementation generally runs under 50% of the time as the CTE version, even though the actual execution plan cost percentages didn’t change any, and the statistics IO numbers show up exactly the same between the two. To push this even further, we take a look at a page near the end of the data set when sorted by CustomerID:
While the statistics IO and actual execution plan remain the same, what really changes is the run time between the two queries. The CTE version took almost 12 seconds to run, whereas the OFFSET-FETCH implementation took just over 4 seconds.
To summarize the performance of a CTE compared to OFFSET-FETCH data paging, it appears that they have almost identical performance when getting results from the top of the sort order, or when grabbing the first few hundred data pages. This performance appears to be about the same, independent of hardware or size of the table. However, where the performance difference starts to show is when the query is looking for data pages deep into the result set. The OFFSET-FETCH implementation is two to three times as fast as the CTE when going millions of rows into the results to get the page that is needed.
Overall, as long as queries are reasonably sized and don’t contain thousands of CTEs, the CTE queries will perform equal to or better than the alternatives. They are usually equal to the non-recursive alternatives, and better than the recursive options.
Other miscellaneous notes on CTE performance
- Unlike temp tables and table variables, a CTE does not use TempDB.
- Indexes cannot be added to a CTE because the CTE only exists for the scope of a single query.
- When using multiple CTEs in a single statement, there is a limit based on memory. Based on performance it may be wise to never have more than 100 CTEs in a single statement.
- A recursive CTE generally performs better than a recursive stored procedure.
Classic Recursive Algorithms
For mathematical algorithms such as Fibonacci or factorial, once the definition of the sequence is understood it is fairly straightforward to establish an anchor query. Once the anchor query has been built, we can thing about in generic terms to build the recursive part.
Fibonacci
The Fibonacci sequence is a mathematical sequence defined as starting with two numbers, 0 and 1, followed by the next number being the sum of the two previous numbers.
For instance: 0,1,1,2,3,5,8,13,21,34,55,89,144,233, and so on.
The Anchor Query
To build the Fibonacci sequence, as with any recursive CTE, we start with the declaration of the CTE and the anchor query. We build the anchor query to simply return two columns, a 0 and a 1.
WITH Fibonacci(PrevN,
N)
AS (SELECT 0,
1)
SELECT PrevN AS Fibo,
N
FROM Fibonacci
Recursion
All we need to do to build the recursive query will be to take the two previous numbers and add them together. We also need to terminate the recursion at some point. To terminate the recursion, we will terminate when N is no longer less than 1000:
WITH Fibonacci(PrevN,
N)
AS (SELECT 0,
1
UNION ALL
SELECT N,
PrevN + N
FROM Fibonacci
WHERE N < 1000)
SELECT PrevN AS Fibo,
N
FROM Fibonacci;
We have calculated the Fibonacci sequence, but we will not clean it and make it more robust.
Data Type Overflow
We will modify the query to calculate more Fibonacci numbers by increasing the limit of recursion to N being less than 10,000,000. When we attempt to run the query we run into an overflow problem.
WITH Fibonacci(PrevN,
N)
AS (SELECT 0,
1
UNION ALL
SELECT N,
PrevN + N
FROM Fibonacci
WHERE N < 10000000000)
SELECT PrevN AS Fibo,
N
FROM Fibonacci;

The reason the overflow error is displayed is the recursive part of the CTE query causes the numbers to grow so fast that it soon goes beyond the size of an integer. The way to fix the overflow error is to cast the numbers into a larger data type, for instance BIGINT, to override the default size of an INT.
WITH Fibonacci(PrevN,
N)
AS (SELECT CAST(0 AS BIGINT),
CAST(1 AS BIGINT)
UNION ALL
SELECT N,
PrevN + N
FROM Fibonacci
WHERE N < 10000000000)
SELECT PrevN AS Fibo,
N
FROM Fibonacci;
Casting the anchor query to a type of BIGINT carries through to the recursive query, and thus allows for Fibonacci sequence numbers to be generated out to the size of BIGINT.
The Output
The next step is to improve the output so that we are not looking at two numbers, and we only see the Fibonacci number at each level. Here we modify the previous query to grab one column instead of two, and to use ROW_NUMBER OVER(ORDER BY) to calculate the row number and subtract 1 so that we start counting at 0.
WITH Fibonacci(PrevN,
N)
AS (SELECT CAST(0 AS BIGINT),
CAST(1 AS BIGINT)
UNION ALL
SELECT N,
PrevN + N
FROM Fibonacci
WHERE N < 10000000000)
SELECT ROW_NUMBER() OVER(ORDER BY PrevN) - 1 AS num,
N
FROM Fibonacci;
Building the Fibonacci sequence covered a number of important topics to be remembered when building recursive CTE queries:
- Start with the anchor query, and get it right first.
- Build the recursive query, and start small.
- Extend the recursion and deal with overflow.
- Clean up the output as desired.
Factorial
The factorial of a positive integer n, written n!, is the product of all the positive integers from 1 up to and including n.
To calculate the factorial for any number, we can use the same four steps used to create the Fibonacci sequence.
The Anchor Query
To build the anchor query we can simply start with calculating 1!, which is equal to 1:
WITH Factorial(N,
Factorial)
AS (SELECT 1,
1)
SELECT N,
Factorial
FROM Factorial
Recursion
Building the recursive part of the query requires us to think in generic terms for n, rather than a specific number. Here we keep in mind that the factorial for any number n with n>1 is that number n multiplied by (n-1) factorial. For the recursive part, we will add 1 to n and then multiply n+1 times the previous factorial. We will terminate the recursion when n gets to be 5.
WITH Factorial(N,
Factorial)
AS (SELECT 1,
1
UNION ALL
SELECT N + 1,
(N + 1) * Factorial
FROM Factorial
WHERE n < 5)
SELECT N,
Factorial
FROM Factorial;

Overflow
We adjust the factorial query to calculate 20! (factorial 20) and we run into a problem:
WITH Factorial(N,
Factorial)
AS (SELECT 1,
1
UNION ALL
SELECT N + 1,
(N + 1) * Factorial
FROM Factorial
WHERE n < 20)
SELECT N,
Factorial
FROM Factorial;

To fix the overflow we can do the same thing we did for the Fibonacci sequence and cast the anchor query to BIGINT:
WITH Factorial(N,
Factorial)
AS (SELECT 1,
CAST(1 AS BIGINT)
UNION ALL
SELECT N + 1,
(N + 1) * Factorial
FROM Factorial
WHERE n < 20)
SELECT N,
Factorial
FROM Factorial;
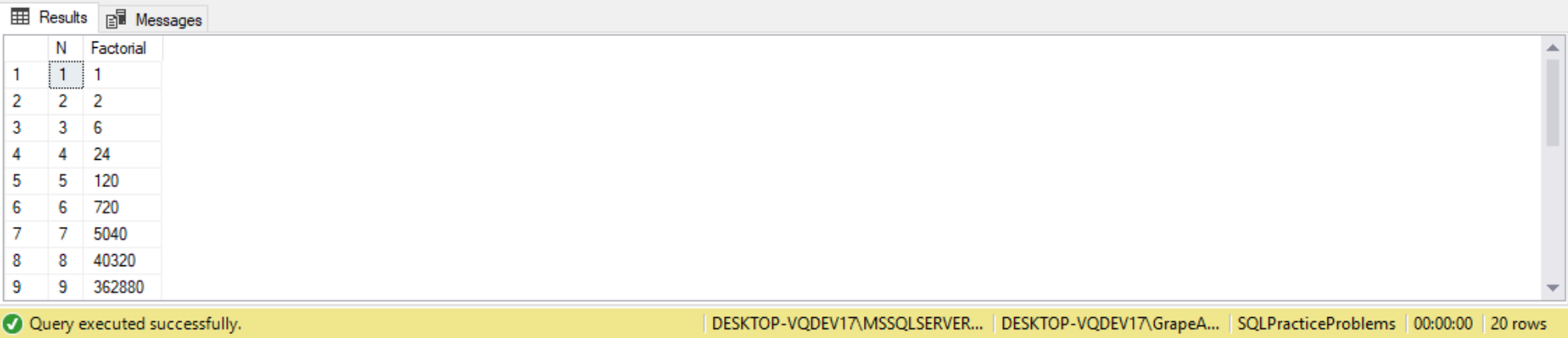
Casting the anchor query factorial value to BIGINT allows us to get to factorial 20, but how far can we go before another overflow? The answer is no further. Factorial of 21 causes an overflow of the BIGINT, so the way around it is to cast to NUMERIC(38,0) data type instead.
WITH Factorial(N,
Factorial)
AS (SELECT 1,
CAST(1 AS Numeric(38,0))
UNION ALL
SELECT N + 1,
(N + 1) * Factorial
FROM Factorial
WHERE n < 21)
SELECT N,
Factorial
FROM Factorial;
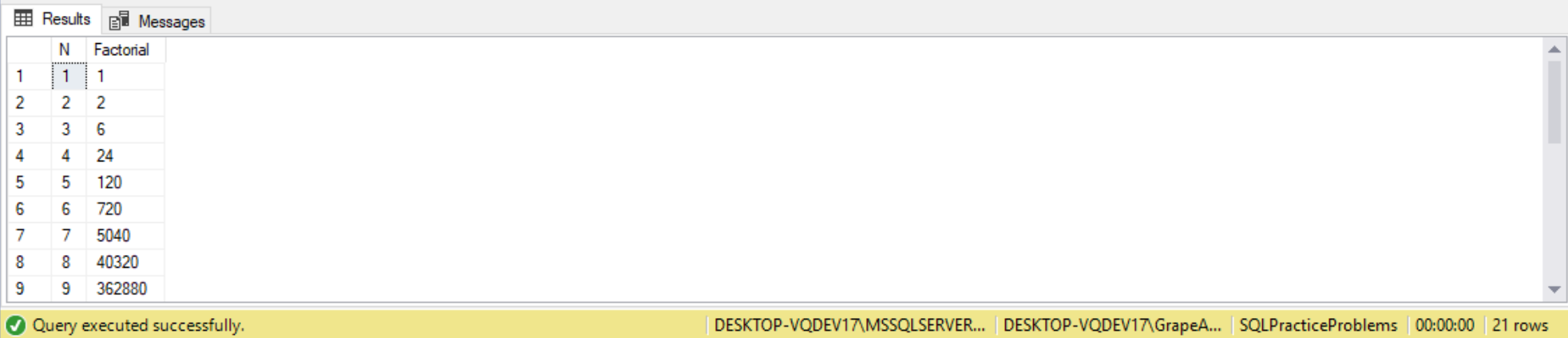
Now we can go beyond factorial 20, but how far can we take it? Well, using NUMERIC(38,0) we can go as far as factorial 33 without running into any problems.
WITH Factorial(N,
Factorial)
AS (SELECT 1,
CAST(1 AS Numeric(38,0))
UNION ALL
SELECT N + 1,
(N + 1) * Factorial
FROM Factorial
WHERE n < 33)
SELECT N,
Factorial
FROM Factorial;
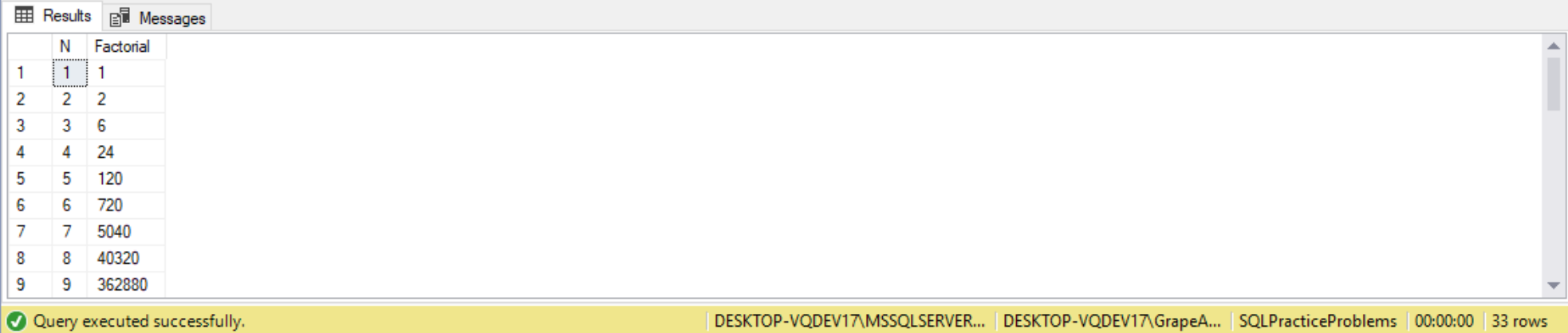
As we can see, with mathematical recursive CTEs it is very common to overflow the default data types. If that happens, we can just CAST the anchor query to a larger data type size and that size will ripple through the recursive query.