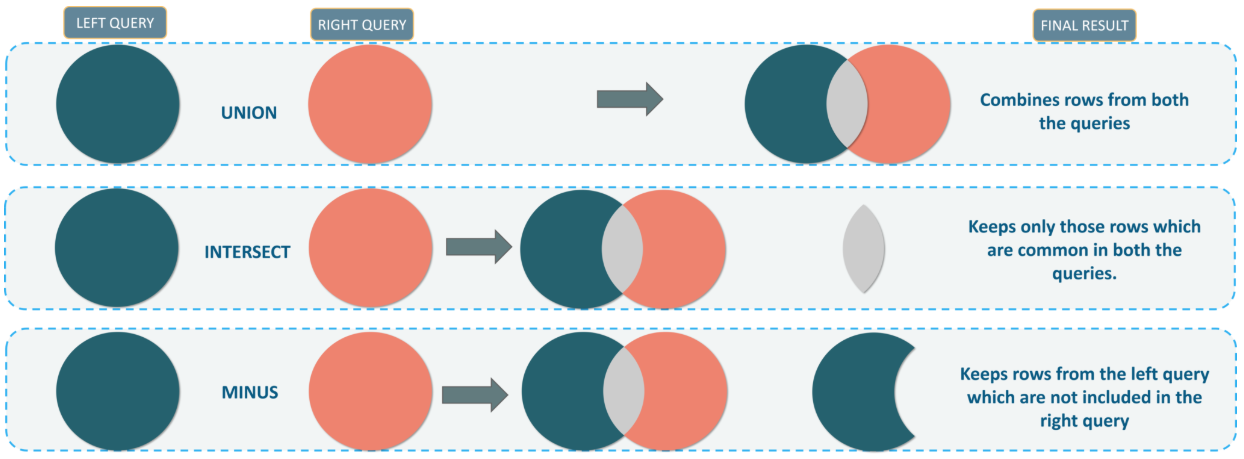
Set Operators
Set Operators
The UNION operator
- The UNION ALL operator
- The UNION (DISTINCT) operator
- Difference between a Join and UNION
The INTERSECT Operator
- The INTERSECT (DISTINCT) operator
- The INTERSECT ALL operator
The EXCEPT operator
- The EXCEPT (DISTINCT) operator
- The EXCEPT ALL operator
Precedence
Circumventing unsupported logical phases
(INCLUDE SYNTAX WITH EVERYTHING)
(INCLUDE NOTES FROM SQL COOKBOOK, Udemy)
Set operators
Set operators are used to combine rows returned from two query result sets (or multisets) into a single result. T-SQL supports the following set operators: UNION, UNION ALL, INTERSECT, and EXCEPT (MINUS in the case of Oracle PL/SQL). The general syntax of a query with set operators is as follows:
(Include syntax from page 217)
The syntax comprises of two (or more) SELECT queries, with a set operator in the middle. The two queries involved with the set operator cannot have ORDER BY clauses. However, even though the input queries using the set operator cannot have ORDER BY clauses, we can optionally add an ORDER BY clause to the result of the set operator. TOP and OFFSET-FETCH are other optional clauses that can be applied to the result of a set operator.
The result of the two input queries must have the same number of columns in the same column order, and the corresponding columns must also be of the same or compatible data type. By compatible we mean the data type of lower data-type precedence must be implicitly convertible to the higher data type. Alternatively, we can also use the CAST or CONVERT functions to convert the data type of one column to the data type of the corresponding column from the other query.
The column names from the first input query becomes the column names of the result set returned by the set operator. Therefore, if we’re assigning aliases to the result columns, we need to apply those to the columns of the first input query.
An interesting feature of set operators is that instead of an equality operator, set operators compares rows between two inputs using a distinct predicate. This predicate evaluates to TRUE when comparing two NULLs. In other words, set operators treat all NULLs as equal. So, set operators will treat NULLs as the same record.
ANSI-standard SQL supports two flavors for set operators: DISTINCT (the default) and ALL. The DISTINCT clause removes duplicates and returns a set, whereas the ALL clause keeps duplicates to return a multiset. All set operators in T-SQL support the distinct version implicitly, but only the UNION set operator supports the ALL version. T-SQL doesn’t allow us to specify the DISTINCT clause explicitly, but rather that is implied when we don’t explicitly specify ALL.
Out of the three kinds of set operators, UNION operator is irreplaceable. There is no other way to combine results from two queries into a single result without using UNION. INTERSECT and EXCEPT can be replaced with JOINs. In fact, we may find that the JOIN version of the queries runs more efficiently than EXCEPT and INTERSECT and is more versatile as we can include fields from the left table that aren’t in the right.
The UNION operator
The UNION operator is used to combine the results of two input queries. A row appearing in any one of the input query results will be returned in the result set of the UNION operator. T-SQL supports both UNION (implicitly DISTINCT) and UNION ALL flavors of the UNION operator.
The UNION operator doesn’t need to return all columns from the input queries, just the ones specified in the SELECT list.
UNION ALL will almost always show more results, as it does not remove duplicate records. As a result of this, UNION is often slower than UNION ALL, because there is an operation to remove duplicate values (a.k.a DISTINCT), which is often a costly step in a query.
The UNION ALL operator
The UNION ALL operator combines the results of two input queries without discarding duplicate rows. If the first query returns x rows and the second query returns y rows, then the UNION ALL operator will return (x + y) rows.
For example, the following query is used to unify employee and customer locations:
(Include code, explanation, and results from page 218)
The result returns 100 records, 9 from the Employees table, and 91 from the Customers table.
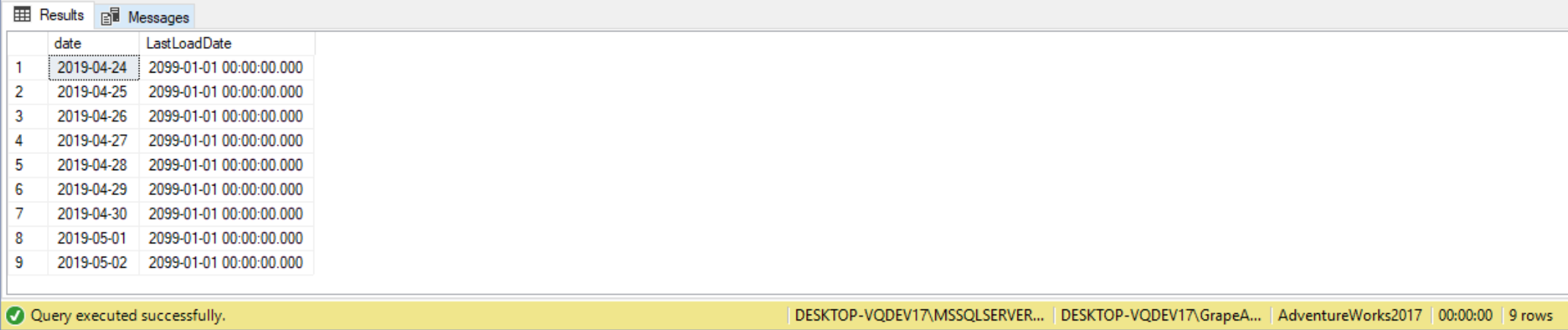
UNION all is typically seen in recursive recursive CTE, like the following query:
USE AdventureWorks2017;
--Drop table 'ControlTable' if it exists
IF OBJECT_ID('dbo.ControlTable') IS NOT NULL
DROP TABLE dbo.ControlTable;
GO
--Recursive CTE
WITH dates([Date])
AS (SELECT CONVERT(DATE, DATEADD(dd, -10, GETDATE())) AS [Date] --Start Date
UNION ALL
SELECT DATEADD(day, 1, [date])
FROM dates
WHERE [Date] <= DATEADD(dd, -3, GETDATE())) --End Date
--Create ControlTable
SELECT date,
CAST('1/1/2099' AS DATETIME) AS LastLoadDate --Hard-coded value
INTO ControlTable --Creates the table 'ControlTable' here
FROM dates OPTION(MAXRECURSION 32767); --Don't forget to use the maxrecursion option!
SELECT *
FROM ControlTable;
The UNION DISTINCT operator
The UNION (implicit DISTINCT) combines the results of two input queries while discarding duplicate rows to return a set. In other words, if a row is present in the result set of both input queries, it will only appear once in the result set of the UNION operator.
For example, suppose we want a list of all AdventureWorks2017 product categories and subcategories. To do this we could write two separate queries and provide two separate results, or we can simply use the UNION clause to deliver one combined result:
SELECT C.Name FROM Production.ProductCategory AS C UNION ALL SELECT S.Name FROM Production.ProductSubcategory AS S;
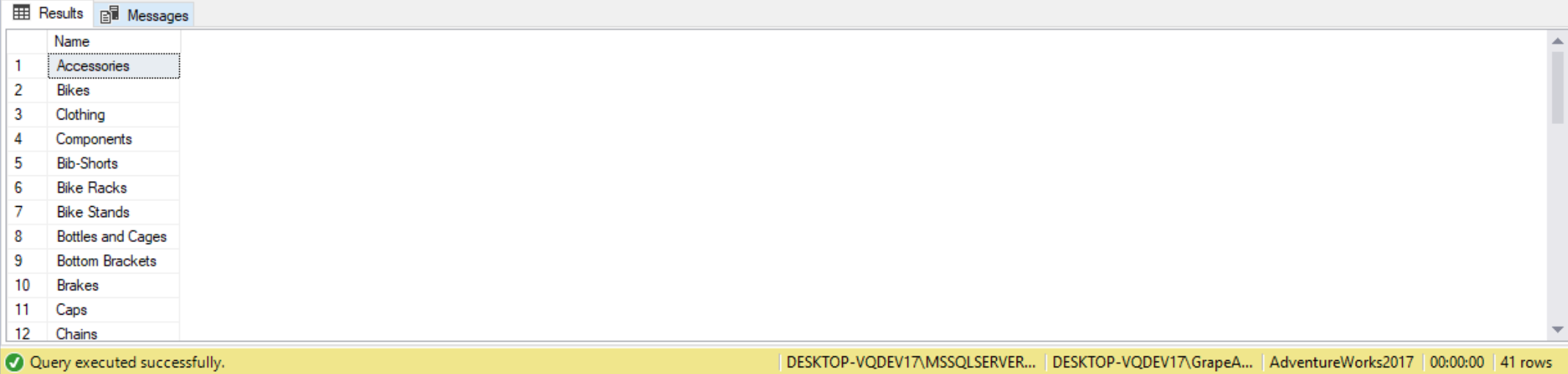
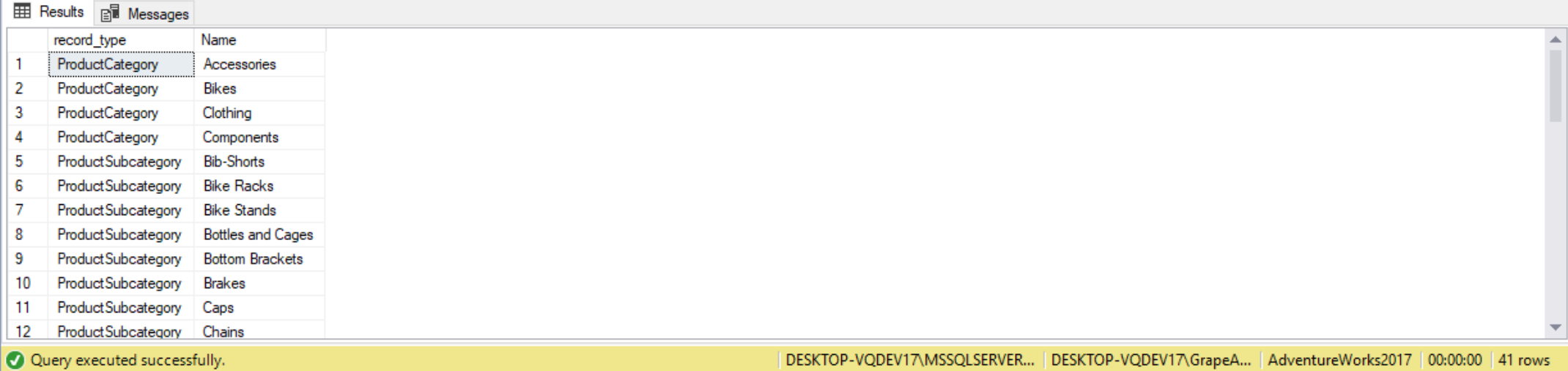
From the result we get a combined list of names, we can’t tell which record came from which table. Suppose we wanted to know which name were categories versus subcategories. To do this we can add a new column indicating the category type. The new columns will add a static value to each query to indicate which table it came from, or what type of record it is. As long as the number and type of columns match, the query will work.
SELECT 'ProductCategory' AS record_type,
C.Name
FROM Production.ProductCategory AS C
UNION ALL
SELECT 'ProductSubcategory',
S.Name
FROM Production.ProductSubcategory AS S;
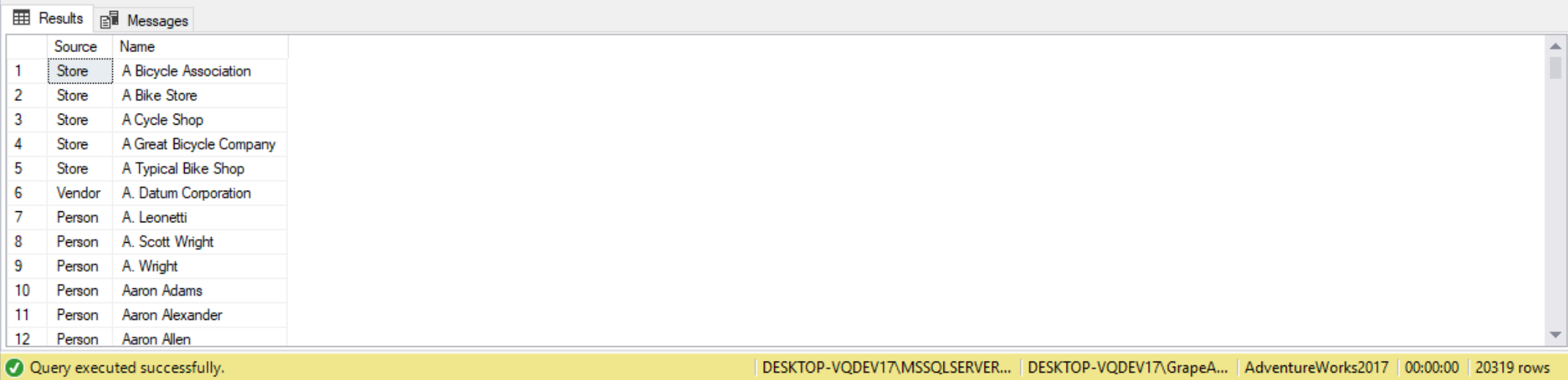
As another example, suppose we want a combined list of people, vendors, and store names identified by source. To do this we create three separate queries and then use the union clause to put them together. We then order the list.
SELECT 'Person' AS Source,
FirstName+' '+LastName AS Name
FROM person.Person
UNION
SELECT 'Vendor',
Name
FROM Purchasing.Vendor
UNION
SELECT 'Store',
Name
FROM Sales.Store
ORDER BY Name;
At first glance we may think the ORDER BY clause would only apply to the last select statement, but in fact it applies to all the results returned by the union. The database engine first process all the union statements then the order by.
If it’s possible that duplicate rows may be returned between the two input queries and we wish to remove them, then we should use the UNION operator; duplicates are not only eliminated between rows from each result, but also from within. Otherwise, we use UNION ALL. If the input queries do not return duplicate rows between them, then the UNION and UNION ALL operators will return the same result set. In such a case, it’s good practice to use UNION ALL over UNION, to avoid unnecessary performance penalty associated with checking for duplicates.
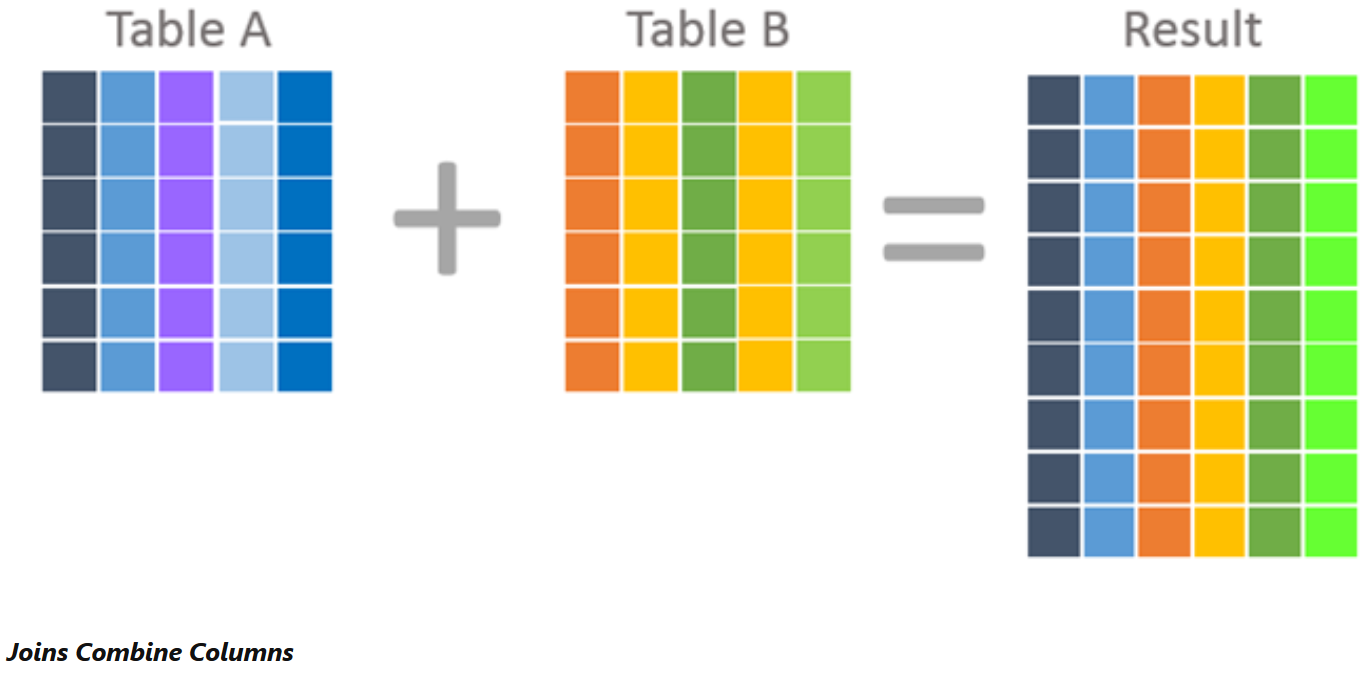
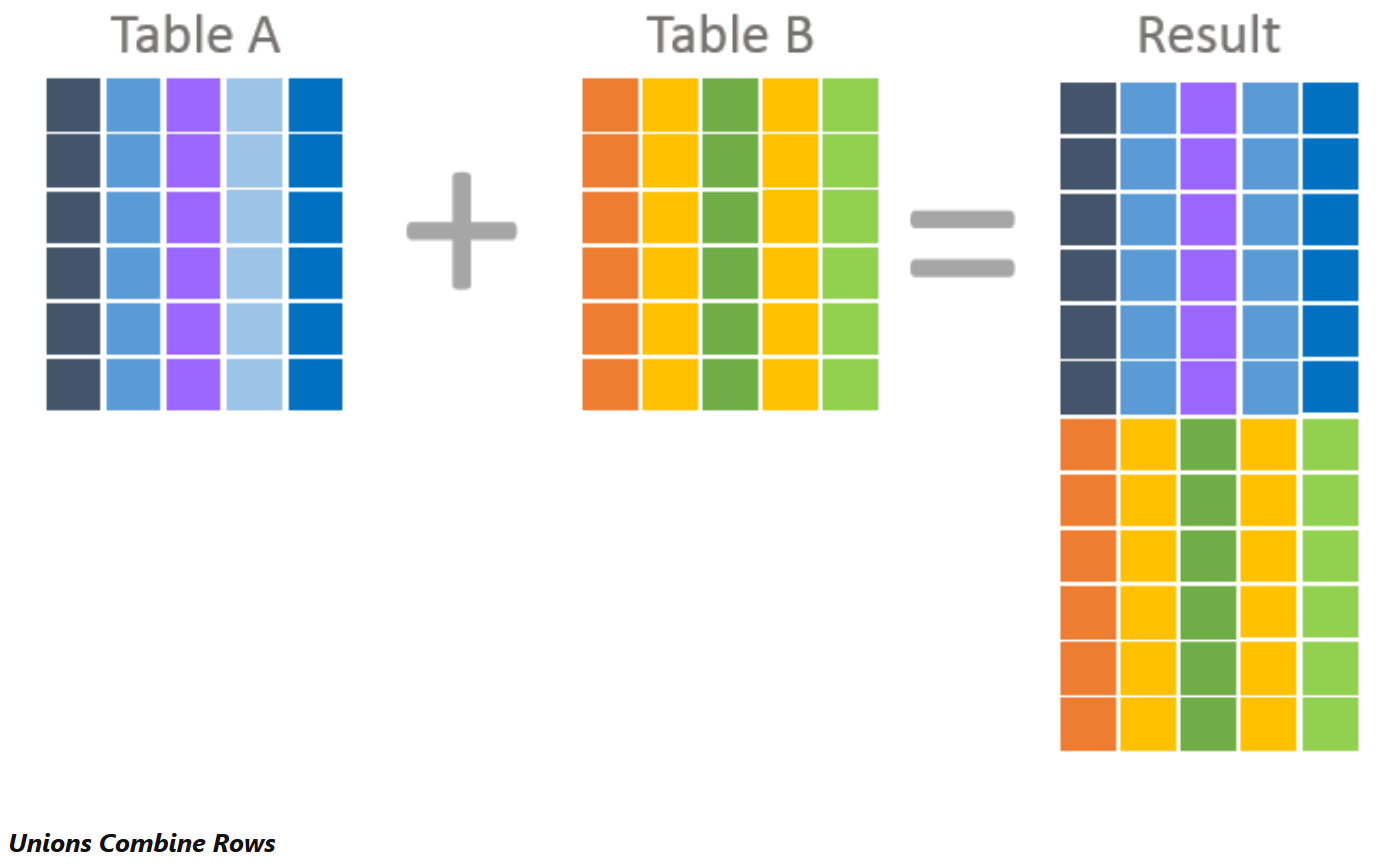
Difference between a JOIN and UNION
JOINs and UNIONs can be used to combine data from one or more tables. The difference lies in how the data is combined. Joins combine data into new columns; if two tables are joined together, then the data from the first table is shown in one set of column alongside the second table’s column in the same row. Unions combine data into new rows; if two tables are “unioned” together, then the data from the first table is in one set of rows, and the data from the second table in another set. The rows are in the same result. So in summary, UNION combines data into separate rows, and JOIN combines data into separate columns.
The INTERSECT operator
The INTERSECT operator returns only rows that appear in the results of both input queries.
The INTERSECT (DISTINCT) operator
The INTERSECT (implied DISTINCT) set operator returns distinct rows that appear in the result set of both input queries. If the row appears at least once in both the input queries result, it will appear as a single unique row in the result set of the INTERSECT operator.
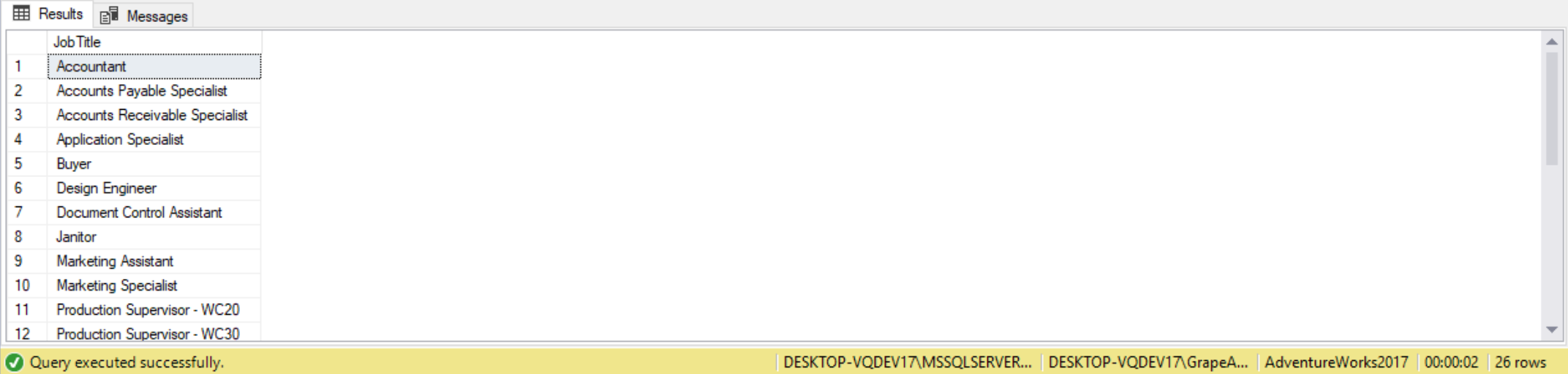
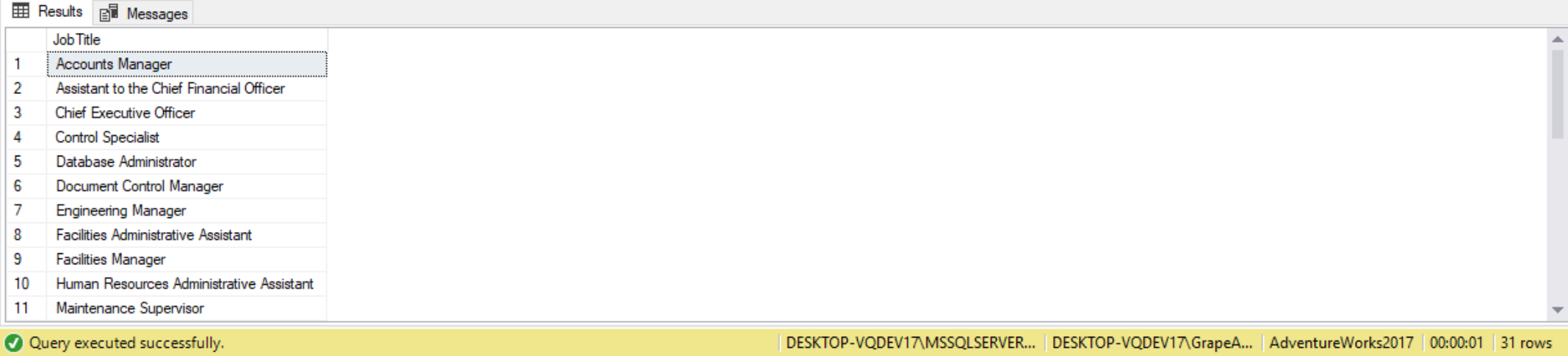
Suppose we want to find all job titles for positions held by both male and female employees. The first set is to compose the queries to find positions held by males, then to do the same for females. To finish we use the INTERSECT operator to find out which titles are in common, as shown in the following query. To order the result by JobTitle we can use an ORDER BY clause. Note that this works on the final row set returned by the interest operator.
SELECT JobTitle FROM HumanResources.Employee WHERE Gender = 'M' INTERSECT SELECT JobTitle FROM HumanResources.Employee WHERE Gender = 'F' ORDER BY JobTitle;
The INTERSECT operator evaluates to TRUE when comparing two NULLs. If instead of INTERSECT we used an INNER JOIN or correlated subquery, we need to add a special treatment for NULLs. For example, assuming e is an alias for the Employees table and c is an alias for the Customers table, we can use the predicate e.region=c.region OR (e.region IS NULL AND c.region IS NULL). With the INTERSECT operator, we don’t explicitly compare corresponding attributes and there is no special treatment for NULLs.
The INTERSECT ALL operator
While ANSI-standard SQL supports the ALL flavor for the INTERSECT operator, T-SQL does not. However, we can write our own logical equivalent in T-SQL.
INTERSECT ALL returns rows that appear in the result set of the two input queries, and duplicate instances for those rows are also returned. More specifically, INTERSECT ALL returns the number of duplicate rows matching the lower of the counts between both input queries.
We can write our own T-SQL equivalent to INTERSECT ALL using the ROW_NUMBER function to number the occurrences of each row in each input query. We then apply the INTERSECT operator between the two input queries with the ROW_NUMBER function. Because the occurrences of the rows are numbered, the intersection is based on the row number along with the original attributes. This is how such a query would go:
(Include code, explanation, and result from page 222)
The standard INTERSECT ALL operator does not return any row numbers. To exclude row numbers from the output, we define a table expression based on the above query, and in the outer query we select only the attributes we want returned in the result set. The code would look like follows:
(Include code, explanation, and result from page 222)
(Note: For window ranking functions like ROW_NUMBER, a window order clause is required. If we don’t care about the ordering, we can use ORDER BY (SELECT<constant>) as the window order clause. SQL Server understands in such a case the order doesn’t matter).
The EXCEPT operator
The EXCEPT operator accepts two input queries, and returns only rows that appear in the result set of the first input query but is absent in the second. In other words, it returns rows that are unique to one result.
The EXCEPT (DISTINCT) operator
The EXCEPT (implied DISTINCT) operator returns distinct rows that appear in the result set of the first input query but is absent in the second. In other words, it returns unique rows from the left query that aren’t in the right query’s results. Unlike with UNION and INTERSECT, the order in which we specify the input queries is important with the EXCEPT set operator. EXCEPT is asymmetrical, meaning (input 1 EXCEPT input 2) is NOT the same as (input 2 EXCEPT input 1). Out of the 3 set operations, EXCEPT is the only one that’s asymmetrical. For EXCEPT, we can’t just transverse the order of the inputs and expect the same result. For example, suppose we want to find all job titles for positions held by males but not female employees. The first set is to compose the queries to find positions held by males, then to do the same for females, as shown in the following query. To order the result by JobTitle we can use an ORDER BY clause. Note that this works on the final row set returned by the except operator.
SELECT JobTitle FROM HumanResources.Employee WHERE Gender = 'M' EXCEPT SELECT JobTitle FROM HumanResources.Employee WHERE Gender = 'F' ORDER BY JobTitle;
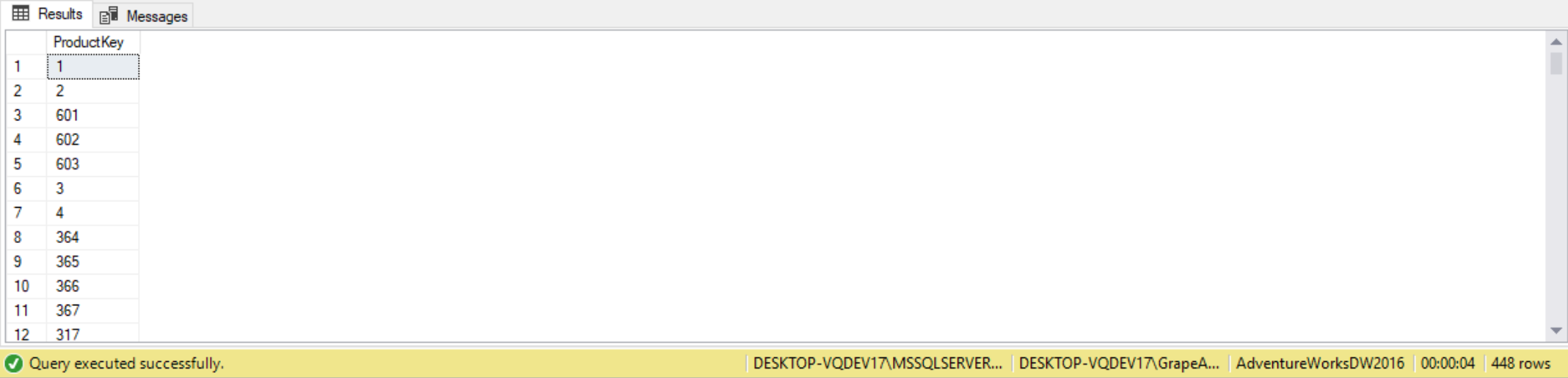
As another example, the following query uses the AdventureWorksDW2016 database, to return all products never sold on the internet:
USE AdventureWorksDW2016; --Return all products never sold on the internet SELECT ProductKey FROM DimProduct EXCEPT SELECT ProductKey FROM FactInternetSales;
Alternatives to the EXCEPT operator include using outer joins that filter for outer rows, as well as using the NOT EXISTS predicate with a subquery. However, with EXCEPT and other set operators, the comparison is implied, and comparing two NULLs evaluates to TRUE. NULLs aren’t values, therefore NULL = NULL will always evaluate to false. Given this, the INNER/OUTER JOIN will fail to match on joins; however, the EXCEPT operator does match NULLS. Therefore, when using joins and subqueries we need to be explicit with the comparisons, as we also need to explicitly add special treatment for NULLs.
The EXCEPT ALL operator
The EXCEPT ALL operator is similar to EXCEPT, but it also takes into account the number of occurrences of each row. If row R appears x times in Query1 and y times in Query2, the EXCEPT ALL operator will return (x-y) records of R.
T-SQL does not support the EXCEPT ALL operator, but we can write our own equivalent like how we wrote one for INTERSECT ALL. We add a ROW_NUMBER calculation to each input query to number the occurrences of rows, and then use the EXCEPT operator between the two input queries. Only rows with unmatched instances are returned. For example, the following query returns employee locations having no corresponding occurrences of customer locations:
(Include code, explanation, and result from page 225)
Precedence
SQL defines precedence among the set operators. INTERSECT precedes UNION and EXCEPT, and UNION and EXCEPT are evaluated in the order they appear in a query. Using the ALL variant of the set operators have no influence on their precedence. For example:
USE AdventureWorksDW2016; --ProductKey not found in both FactInternetSales and FactResellerSales (606 rows) SELECT ProductKey FROM DimProduct EXCEPT SELECT ProductKey FROM FactInternetSales INTERSECT -- ProductKey found in both FactInternetSales and FactResellerSales (142 rows) -- (606 - 142 = 464 rows) SELECT ProductKey FROM FactResellerSales;
Even though INTERSECT is the second set operator appearing in our query, it is evaluated first because it has precedence over EXCEPT. The query returns supplier locations that are not employee and customer locations.
We can control the order of evaluation of the set operators by using parentheses, since parentheses have the highest precedence. Use of parentheses also improves readability of the code. For example, the following query returns supplier locations that are not employee locations, and are also customer locations:
(Include code, explanation, and result from page 226)
Circumventing unsupported logical phases
Input queries involved with set operators support all logical-query processing phases, except for the ORDER BY clause. The ORDER BY clause is only accepted on the result of the set operator.
Other logical phases besides the ORDER BY clause are not allowed on the result of a set operator. We can circumvent this limitation by using table expressions. We can define a table expression based on a query with a set operator, and then apply any logical query processing phases in the outer query. For example, the following query returns the number of distinct locations that are either employee or customer locations for each country:
(Include code, explanation, and result from page 227)
The above query uses the GROUP BY operator on the result of a UNION operator. Other logical-query clauses can be applied to the result of a set operator in similar fashion.
While we cannot directly use ORDER BY, TOP, or OFFSET-FETCH clauses, we can again use table expressions to circumvent this limitation. We can apply the ORDER BY in an inner query with TOP or OFFSET-FETCH. For example, the following query uses the TOP clause to return the two most recent orders for employees 3 and 5:
(Include code, explanation, and result from page 228)
(^^ Test the above query without the UNION ALL, instead use WHERE empid IN (3,5). See if it returns the same result set)