User Defined Function & Tables Value Functions
(INCLUDE SYNTAX WITH EVERYTHING)
(INCLUDE NOTES FROM Advanced SQL book, SQL COOKBOOK, Udemy)
User Defined Functions:
- Scalar functions
- Inline table-valued functions
- Multistatement table-valued functions
User-Defined System functions
Other UDF considerations
User-defined functions
SQL Server supports three types of routines: user-defined functions, stored procedures, and triggers.
A user-defined function (UDF) is used to encapsulate logic that calculates something, by accepting input parameters and then returning a result. Two types of UDFs include: scalar UDFs and table-valued UDFs. Scalar UDFs return a single value, whereas table-valued UDFs return a table. Scalar UDFs can be used anywhere in a query where an expression returns a single value (for example, in the SELECT list). Table UDFs can be used in the FROM clause of a query.
UDFs are not allowed to have side effects, and they cannot apply any schema or data changes in the database. Possible side effects may come from invoking functions such as RAND and NEWID. When RAND or NEWID are invoked in a query, SQL Server needs to set some information aside to be taken into consideration in the next invocation of these functions. Because functions like RAND and NEWID have such side effects, they cannot be used inside UDFs.
User-defined functions cannot make permanent changes to the data or modify database tables. UDF can change only local objects for this UDF, such as local cursors or variables.
User-defined functions can be invoked from a query like built-in functions such as OBJECT_ID, LEN, DATEDIFF, or can be executed through an EXECUTE statement like stored procedures. UDF functions may not be used in dynamic SQL. UDFs may create table variables, but they cannot create or access temp tables. Another important point is the UDFs can and should be created using the WITH SCHEMA BINDING option exactly how we would when we create views when we use that WITH SCHEMA binding option. It’s going to essentially prevent those underlying objects that are being referenced by columns in our function to be changed. So essentially, it’s going to protect the integrity of our functions. Without that option, they can make changes to those underlying objects and then our functions may not work anymore the way they were meant to or might have expected those to.
UDFs can be deterministic or nondeterministic. A deterministic function is essentially when we know that every time we call the function the result is going to be the same as long as the inputs are the same. The result value will be the same each time we execute it. Nondeterministic functions are functions that may return different results every single time we execute that function. We cannot determine the value until the function runs. An example of this is the GETDATE() function. Every single time we run the GETDATE() function, we are going to get a different value than the last time we ran it, and we don’t know what result that’s going to be until we execute it. Nondeterministic functions may not be used on computed columns or in indexed views, whereas the deterministic functions may be. Another important point about nondeterministic functions is that they’re usually going to be ran once per statement that is executed. For example, if we are bringing back 10,000 rows from our Person.Person table and we execute the GETDATE() function and add that as a new row (maybe as Datetime of retrieval of those records), every single row that we have retrieved from that Person.Person table is going to have the exact same value in that GETDATE() column because it’s a nondeterministic function and typically nondeterministic functions is only going to be ran once for the statement. From a performance perspective, this is good because it’s not going to be ran on a row-by-row basis. Another example of a nondeterministic function is the RAND() function. If we ever tried to use the RAND() function on SQL Server against a large dataset and wondered why does every single row have the same random number generated, it is because it’s a nondeterministic function and run only once for the entire statement and not on a row-by-row basis. Non-deterministic functions run once per statement, not once per row.
SQL Server will allow NULL values to be passed into our functions, and it will still execute those functions. If the input parameter is NULL, then generally the result set itself will actually be NULL. Since the function that we’re creating are getting executed once for every single row that’s coming back in that result set, and if half of those records are NULL, we don’t want that function to execute and waste precious resources. We have an option in SQL Server to turn on return NULL on NULL input. In other words, if the input going in is NULL, do not execute that function and get return a NULL value because in general it’s going to return a NULL value anyway.
SQL Server cannot compile the function as inline code. It cannot take that function, parse it out, and then run it inline inside of the query. It actually calls the function for every single row that’s being passed in. So there’s no optimization in SQL Server to compile that code. There may be queries that take hours to run because we have these scalar functions created that were being used inside the code, and were causing performance issues and alternative methods are required.
The execution plan itself isn’t really going to tell us the function is causing as much of a performance problem as it is, which is very unfortunate. But we can still look and find that from inside the execution plan by going into the Properties, and find out the true impact that these scalar functions are ultimately having on our query and results.
There are three types of UDF in SQL Server 2017:
Scalar functions
Scalar functions return a single data value (not a table) with the RETURNS clause. Scalar functions can use all scalar data types, with exception of timestamp and user-defined data types. We can use them inside our queries, inside constraints, and also in computed columns. They can accept zero or more input parameters, but they don’t support output parameters. The RETURN clause is used to specify the return value of the function and to abort any further activity. The function body, hosting the code, is defined in the boundaries of a BEGIN END block. When referring to a UDF scalar function, we must supply its two−part name, including the function’s owner and name, (e.g., dbo.f1()). This requirement prevents ambiguity between user−defined and built−in scalar functions with the same name.
In the following example, we’re passing in a parameter, which after passed in the function will return the address that we expect:
--ufn is short for User Function
CREATE FUNCTION dbo.ufc_GetPersonAddress
(@BusinessEntityID INT
)
RETURNS VARCHAR(100)
AS
--BEGIN and END blocks are required for syntax
BEGIN
DECLARE @Address VARCHAR(100);
SELECT @Address = AddressLine1
FROM Person.Person AS p
JOIN Person.BusinessEntityAddress AS bea ON p.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a ON bea.AddressID = a.AddressID
WHERE p.BusinessEntityID = @BusinessEntityID;
RETURN @Address;
END;
--Invoke dbo.ufn_GetPersonAddress
--Must use same schema as function
--Must pass a parameter
SET STATISTICS IO, TIME ON;
SELECT p.FirstName,
dbo.ufn_GetPersonAddress(p.BusinessEntityID)
FROM Person.Person AS p;
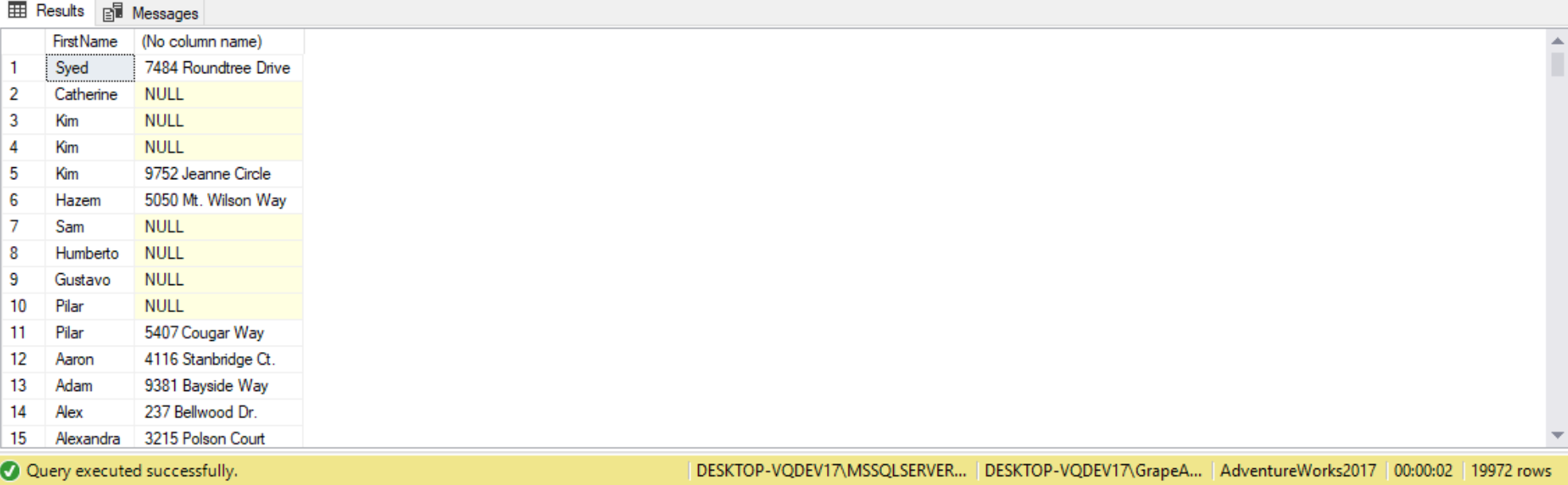

The Query Plan is not showing that the Scalar function is the cause of the performance problem:

We can right-click on that Compute Scalar operator and select the Properties window to further look into the defined values by clicking on the elipses next to Defined Values:
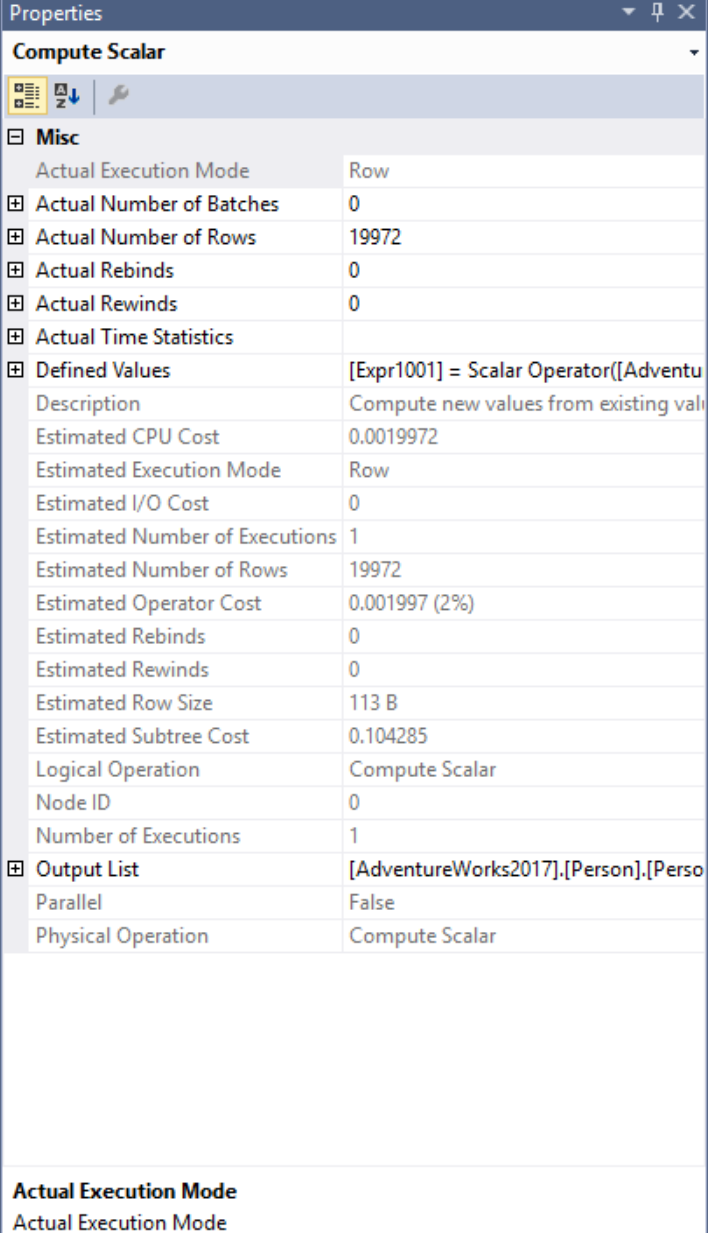
What we’re trying to see if SQL Server did ultimately go in there and inline this code or is it making a separate function and call for every single row. If we see the function being called inside of the scalar operator function, then we know that it is being called once per row.
--Invoke dbo.ufn_GetPersonAddress
SET STATISTICS IO, TIME ON;
SELECT p.FirstName,
dbo.ufn_GetPersonAddress(p.BusinessEntityID)
FROM Person.Person AS p;
--Performance difference when getting same result set using JOIN
SELECT p.BusinessEntityID,
a.AddressLine1
FROM Person.Person AS p
JOIN Person.BusinessEntityAddress AS bea ON p.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a ON bea.AddressID = a.AddressID;
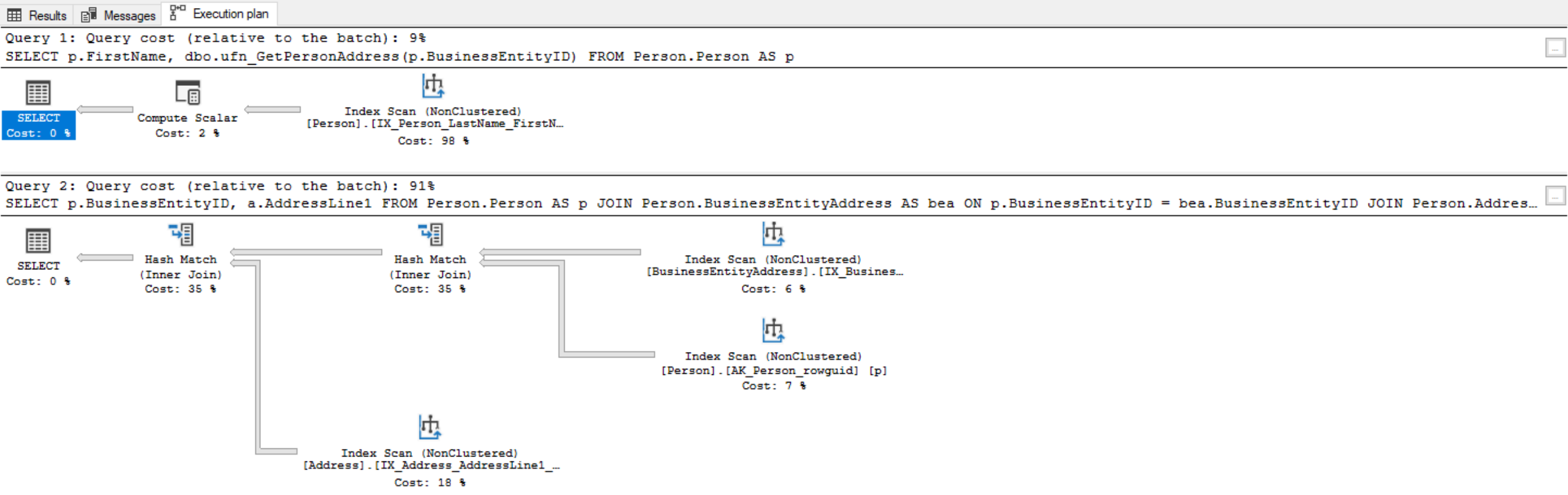
We don’t have to call a scalar function from within a select statement, since everything we need is already in the code of the function. If we pass a @BusinessEntityID parameter, we should get @Address returned. The following code runs well because we’re only putting in one value as the parameter:
SELECT dbo.ufn_GetPersonAddress(10);

The following UDF will return the creation date for a given database (we should specify database name as parameter for this UDF):
CREATE FUNCTION dbo.DBCreationDate (@dbname SYSNAME)
RETURNS DATETIME
AS
BEGIN
DECLARE @crdate DATETIME
SELECT @crdate = crdate
FROM master.dbo.sysdatabases
WHERE name = @dbname
RETURN (@crdate)
END
--This is the example for use:
SELECT dbo.DBCreationDate('AdventureWorks2017')
GO

The UDF will return the creation date for a given object in the current database:
CREATE FUNCTION dbo.ObjCreationDate (@objname SYSNAME)
RETURNS DATETIME
AS
BEGIN
DECLARE @crdate DATETIME
SELECT @crdate = crdate
FROM sysobjects
WHERE name = @objname
RETURN (@crdate)
END
GO
--This is the example for use:
SELECT dbo.ObjCreationDate('Sales.SalesOrderHeader')
GO
This UDF will return the date part of datetime value:
CREATE FUNCTION dbo.DatePart (@fDate DATETIME)
RETURNS VARCHAR(10)
AS
BEGIN
RETURN (CONVERT(VARCHAR(10), @fDate, 101))
END
GO
--This is the example for use:
SELECT dbo.DatePart('11/11/2013 11:15AM')
GO

This UDF will return the time part of datetime value:
CREATE FUNCTION dbo.TimePart (@fDate DATETIME)
RETURNS VARCHAR(10)
AS
BEGIN
RETURN (CONVERT(VARCHAR(7), RIGHT(@fDate,7), 101))
END
GO
--This is the example for use:
SELECT dbo.TimePart('11/11/2013 11:15AM')
GO

This UDF will return the number of working days between two dates (not including these dates):
CREATE FUNCTION dbo.GetWorkingDays (
@StartDate DATETIME
,@EndDate DATETIME
)
RETURNS INT
AS
BEGIN
DECLARE @WorkDays INT
,@FirstPart INT
DECLARE @FirstNum INT
,@TotalDays INT
DECLARE @LastNum INT
,@LastPart INT
IF (DATEDIFF(day, @StartDate, @EndDate) < 2)
BEGIN
RETURN (0)
END
SELECT @TotalDays = DATEDIFF(day, @StartDate, @EndDate) - 1
,@FirstPart = CASE DATENAME(weekday, @StartDate)
WHEN 'Sunday'
THEN 6
WHEN 'Monday'
THEN 5
WHEN 'Tuesday'
THEN 4
WHEN 'Wednesday'
THEN 3
WHEN 'Thursday'
THEN 2
WHEN 'Friday'
THEN 1
WHEN 'Saturday'
THEN 0
END
,@FirstNum = CASE DATENAME(weekday, @StartDate)
WHEN 'Sunday'
THEN 5
WHEN 'Monday'
THEN 4
WHEN 'Tuesday'
THEN 3
WHEN 'Wednesday'
THEN 2
WHEN 'Thursday'
THEN 1
WHEN 'Friday'
THEN 0
WHEN 'Saturday'
THEN 0
END
IF (@TotalDays < @FirstPart)
BEGIN
SELECT @WorkDays = @TotalDays
END
ELSE
BEGIN
SELECT @WorkDays = (@TotalDays - @FirstPart) / 7
SELECT @LastPart = (@TotalDays - @FirstPart) % 7
SELECT @LastNum = CASE
WHEN (@LastPart < 7)
AND (@LastPart > 0)
THEN @LastPart - 1
ELSE 0
END
SELECT @WorkDays = @WorkDays * 5 + @FirstNum + @LastNum
END
RETURN (@WorkDays)
END
GO
--This is the example for use:
SELECT dbo.GetWorkingDays('11/13/2013', '12/27/2014')
GO

For example, the following code creates a UDF called dbo.GetAge that returns the age of a person with a specified birth data (@birthdate argument) and a specified event date (@eventdate argument):
(Include code, explanation and results from page 405)
The function calculates age as a difference (in years) between birth year and event year, minus 1 year in cases where the event month and day is less than the birth month and day. The expression (100 * month + day) is a trick we use to concatenate the month and day. For example, for the twelfth day in the month of February, the expression returns the integer 212.
Note that along with a RETURN clause in its body, a function can also have code with flow elements, calculations, and more. But the function must contain a RETURN clause that returns a value.
The following query against the HR.Employees table invokes the GetAge function in the SELECT list to calculate the age of each employee, as a difference between their birth date and the current date:
(Include code, explanation and results from page 405)
Note that the values we get in the age column depend on the date we run the query.
Inline table-valued functions
Inline table-valued functions return the result set of a single SELECT statement. The definition of an inline table-valued function is permanently stored as a database object, similar to a view would. They accept parameters the same way scalar functions do and return the result of a SELECT statement, which can incorporate the parameters supplied to the function. Note that the same rules that apply to views regarding the requirement that the result will have only unique column names and that there will be no columns without a name, apply to functions that return rowsets.
Inline Table Value functions are similar to views in the sense that the returned table is defined by a query specification inside of the function. Inline Table Value functions are also actually called “parameterized views”. So they’re views that have parameters on them with the same rules and requirements involved in creating views.
Whenever we’re writing an inline table value UDF, the BEGIN and END block of that function is not required. Rather, a single RETURN clause appears, followed by the SELECT statement. Its return type is a table, but we need not declare this table variable because the function uses the columns and datatypes used in the SELECT statement. SQL Server evaluates the inline value function and it is able to access the code in the background of that UDF. Scalar function is not inline code, meaning that the SQL Server optimizer is not able to take that function and access the underlying objects as part of the SQL Server plan. It actually has to execute the function one time for every record that we pass into it. Inline Table Value UDFs on the other hand, are inline code, so SQL Server can access the underlying database objects of that code, combine it with the outer query and execute that code more efficiently. In other words, Inline Table Value functions will perform better than scalar functions. Inline Table Value functions will not allow we to do data modifications. We are constrained with the same type of rules as with views, we have a single SELECT statement that returns a table. One of the great advantages of the inline table−valued function is that the query’s code inside the function is merged internally with the calling query’s code in the same way that a SELECT statement in a view is. Thus, we get an efficient, integrated optimization with the calling query.
--Inline Table Value UDF
--No BEGIN or END block
CREATE FUNCTION dbo.SalesByStore
(@StoreID INT
)
RETURNS TABLE
AS
RETURN
(
SELECT p.ProductID,
p.Name,
SUM(sod.LineTotal) AS 'Total'
FROM Sales.SalesOrderDetail AS sod
JOIN Production.Product AS p ON sod.ProductID = p.ProductID
JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID
JOIN Sales.Customer AS c ON soh.CustomerID = c.CustomerID
WHERE c.StoreID = @StoreID
GROUP BY p.ProductID,
p.Name
);
--Returns list of products sold for StoreID=1020, and the total sales for each product
SELECT * FROM dbo.SalesByStore(1020);

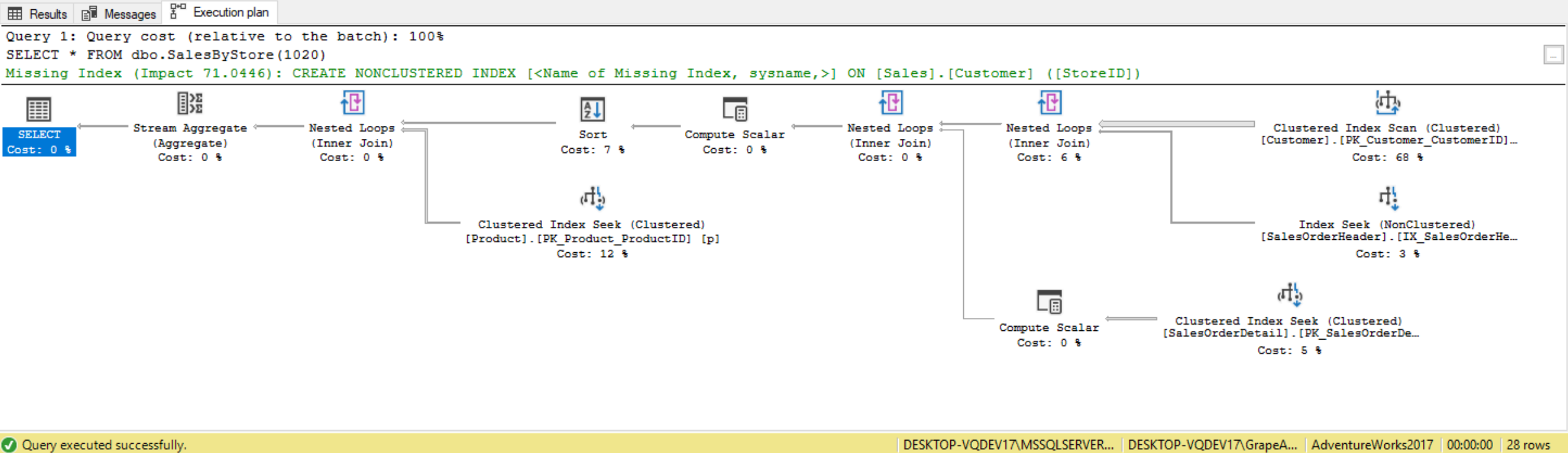
SQL Server, when it generates a plan it is able to access the underlying objects. What we don’t see is the name of the function that we’re passing, because in the background SQL Server is able to read the underlying objects of that code and optimize that code.
There are scenarios where we can optimize scalar functions, by replacing the scalar function with an inline Table Value function, so we get the benefit of performance and encapsulating that code.
--Table value function can be used to solve the row by row problem.
CREATE FUNCTION dbo.GetPersonAddress
(@BusinessEntityID INT
)
RETURNS VARCHAR(100)
AS
BEGIN
DECLARE @Address VARCHAR(100);
SELECT @Address = AddressLine1
FROM Person.Person AS p
JOIN Person.BusinessEntityAddress AS bea ON p.BusinessEntityID = bea.BusinessEntityID
JOIN Person.Address AS a ON a.AddressID = bea.AddressID
WHERE p.BusinessEntityID = @BusinessEntityID;
RETURN;
@Address;
END;
GO
The scalar function is a row by row execution. Every time we pass in a row we invoke that scalar function that we’ve created (Line 42). The second query (line 44) is a table value function involving a join on the BusinessEntityID. Here is the execution plan for both queries:
(Include Execution plan from PW -REWATCH THE VIDEO LECTURE!)
Notice for the scalar value function the query optimizer is not showing that we’re invoking the function, and in fact is showing us that the cost of the function is 0%. When we see the plan for the Table Value function, we can see it’s scanning the Person, Address, and BusinessEntityAddress tables. It’s merge joining them together then a hash match. We don’t see actually executing the underlying Table Value function, what we see is that it’s able to inline that function and access the underlying objects and therefore generate a more efficient plan. When looking at Messages, we see the scalar value function had logical reads of 3838 and CPU time 2329 ms and total elapsed time of 2428 ms. On the other hand, the inline table value function has a CPU time of 15 ms and elapsed time of 382 ms, which is a significant difference in performance. The combined logical reads of the table is also significantly less.
Both queries are doing the same thing, but SQL Server is able to optimize the code and access the underlying objects of the inline table value function. We optimized a scalar function by replacing it with an inline table value function, and this gives us the opportunity to encapsulate that logic that we need while also enable significantly better performance. So, scalar functions are generally bad for performance.
Multistatement table-valued functions
Return fully declared table variable that is defined after the RETURNS keyword in the function’s header. This type of function has a function body with a BEGIN END block, and in its body, we can use T−SQL code with flow−control elements. The purpose of the code elements inside the function’s body is to fill the table variable that will be returned from the function with rows.
The Multi-Statement UDF are required whenever the implementation of that function cannot be expressed in the single query. Instead, it’s going to require some type of procedural logic or code similar to what we might see in a stored procedure. An example of this may be when we’re declaring and populating variables when using a while loop, we have this top-down procedural code that we need to implement. In such a case we’re required to use a Multi-State UDF.
Multi-Statement Value UDFs requires that we must identify a BEGIN and END block for that function. Multi-Statement Value UDFs will return a table variable. Anytime we want to have these different statements of procedural code implemented, we will have to return that into a table variable, it won’t just return a table. Similar to scalar functions, the execution plan is not going to be accurate here, because the SQL Server optimizer cannot read through that procedural code. It’s not able to tell us the true impact of performance from using that function that we’re implementing here.
--Multistatement table-valued UDF
CREATE FUNCTION dbo.MS_SalesByStore
(@StoreID INT
)
RETURNS @table TABLE
(ProductID INT,
Name VARCHAR(50),
Total NUMERIC(16, 2)
)
AS
BEGIN
INSERT INTO @table
SELECT p.ProductID,
p.Name,
SUM(sod.LineTotal) AS 'Total'
FROM Sales.SalesOrderDetail AS sod
JOIN Production.Product AS p ON sod.ProductID = p.ProductID
JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID
JOIN Sales.Customer AS c ON soh.CustomerID = c.CustomerID
WHERE c.StoreID = @StoreID
GROUP BY p.ProductID,
p.Name;
RETURN;
END;
--Return list of products sold and total sales for StoreID=1020
SELECT * FROM dbo.MS_SalesByStore(1020);
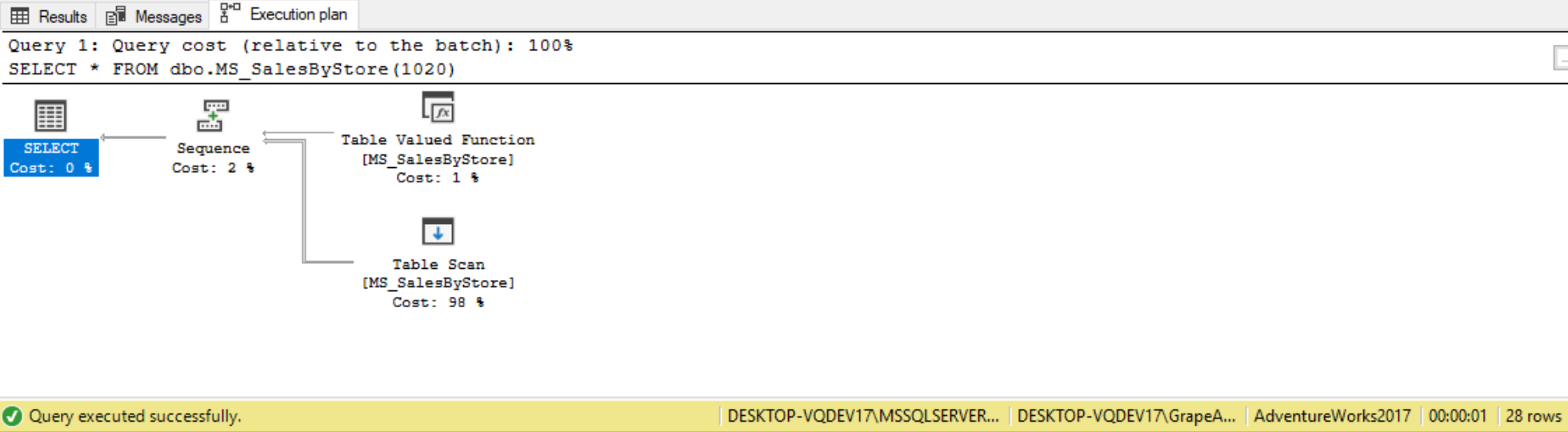
In the execution plan of this Multi-Statement Table Value UDF, we see that the SQL Server optimizer is invoking that Table Value function, and is saying the cost is 1% which is unfortunately is not going to be accurate here, because the SQL Server optimizer cannot identify and parse through that procedural code that we’re using in that TVF.
Performance comparison between Inline UDF vs Multi-Value UDF:
SET STATISTICS IO, TIME ON;
--Query 1
SELECT CustomerID,
StoreID,
TerritoryID,
AccountNumber,
--Last 3 columns from dbo.SalesByStore inline UDF
ProductID,
Name,
Total
FROM Sales.Customer
--StoreID from Sales.Customer table
CROSS APPLY dbo.SalesByStore(StoreID);
--Query 2
SELECT CustomerID,
StoreID,
TerritoryID,
AccountNumber,
--Last 3 columns from dbo.SalesByStore Multi-Value UDF
ProductID,
Name,
Total
FROM Sales.Customer
--StoreID from Sales.Customer table
CROSS APPLY dbo.SalesByStore(StoreID);
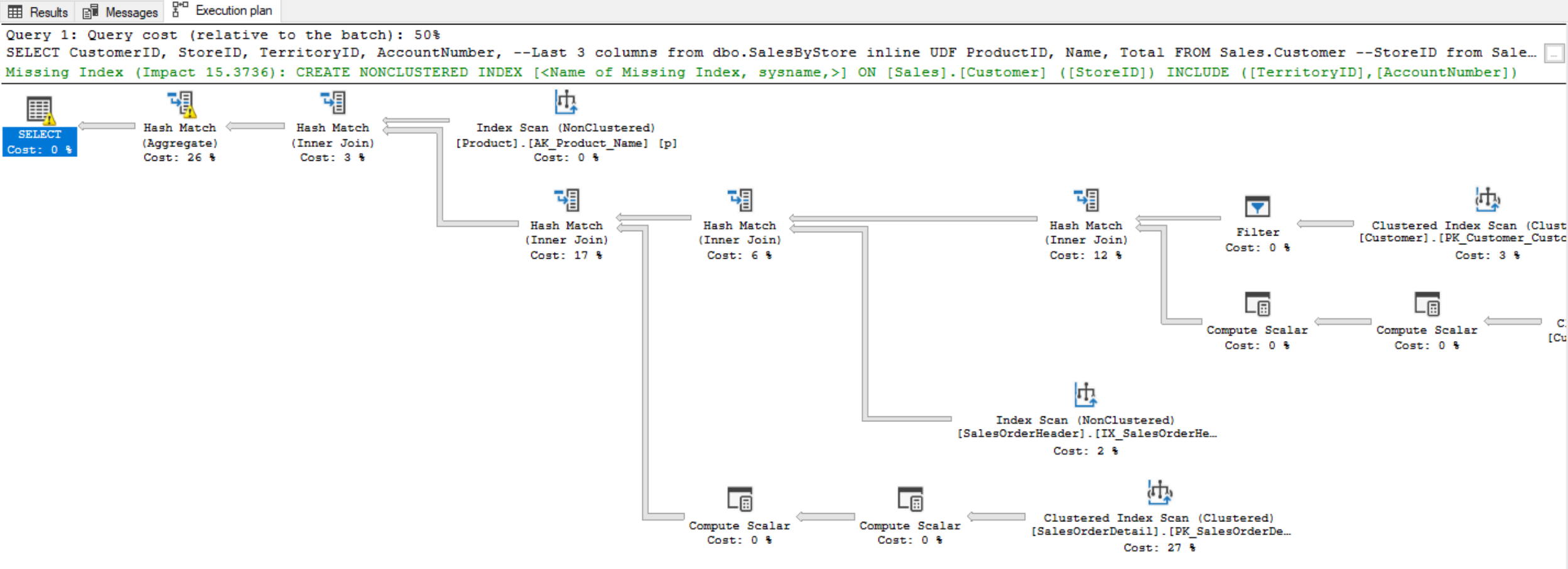
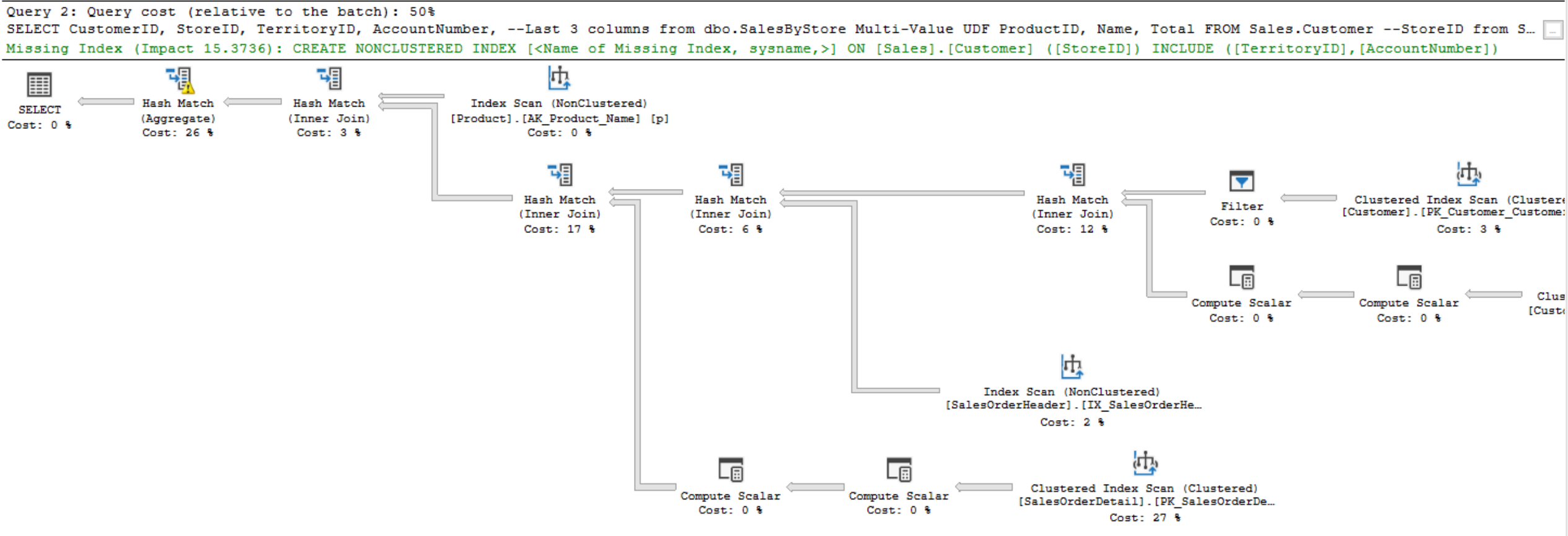
If we look at the bottom execution plan (for Multi-Value function), we see that SQL Server optimizer is still calling in the Table Value function. It is using Nested Loops, which is a good indication that the Table Value Function is being invoked for every single row for the outer query. The Sales.Customer table is bringing in the StoreID, which is being passed in from the Nested Loop into our Table-Value function on a row-by-row operation.
If we look at the top execution plan (for Inline UDF), we’re not able to see the Table-Value function being executed, because the SQL Server optimizer plan is able to go in there and parse out that code and directly access those underlying objects. The Multi-Table function is 73% query cost relative to the batch, while the Inline function is 27%, which may not be accurate because it’s not really understanding the performance impact of the Table Value function. The Multi-Value function is 73% because of the nested loop and the impact that is having on performance.
Statistics information:

For the Multi-Value function, the logical reads is 19820 and CPU time is 2297 ms. For the Inline function, the CPU time is 312 ms. For the exact same work, the Multi-Value function took 10 times longer than the Inline function.
A good use-case for Multi-Value Table Value functions we need to do procedural code that we want to encapsulate (things like declaring variables, using WHILE loops) where we require a top-down approach. We’re not doing set-based operations, but top-down approach.
USE AdventureWorksDW2016;
IF OBJECT_ID(N'dbo.ufn_ListofDates') IS NOT NULL
DROP FUNCTION dbo.ufn_ListOfDates;
GO
CREATE FUNCTION dbo.ufn_ListOfDates
(@StartDate DATE
)
RETURNS @table TABLE(ProcessDate DATE)
AS
BEGIN
DECLARE @counter INT= 0;
WHILE @counter < 10
BEGIN
INSERT INTO @table
SELECT FullDateAlternateKey AS ProcessDate
FROM DimDate
WHERE FullDateAlternateKey = @StartDate;
SET @counter = @counter + 1;
SET @StartDate = DATEADD(dd, -1, @StartDate);
END;
RETURN;
END;
GO
SELECT * FROM dbo.ufn_ListOfDates('1/11/2008')

As mentioned before, scalar functions cannot be inline by the SQL Server optimizer. Every record that gets passed in from the outer query gets executed row-by-row against that function. We see similar behavior with Multi-Value Table functions, but they are considered inline because SQL Server can access those underlying database objects.
As another example of a multi-statement table valued function, you will create a simple function that returns a certain manager and that manager’s subordinates in all levels from the Employees table in the Northwind database
USE Northwind;
GO
CREATE FUNCTION get_mgremps
(@mgrid AS INT
)
RETURNS @tree TABLE
(EmployeeID INT NOT NULL,
LastName NVARCHAR(20) NOT NULL,
FirstName NVARCHAR(10) NOT NULL,
Title NVARCHAR(30) NULL,
TitleOfCourtesy NVARCHAR(25) NULL,
BirthDate DATETIME NULL,
HireDate DATETIME NULL,
Address NVARCHAR(60) NULL,
City NVARCHAR(15) NULL,
Region NVARCHAR(15) NULL,
PostalCode NVARCHAR(10) NULL,
Country NVARCHAR(15) NULL,
HomePhone NVARCHAR(24) NULL,
Extension NVARCHAR(4) NULL,
Photo IMAGE NULL,
Notes NTEXT NULL,
ReportsTo INT NULL,
PhotoPath NVARCHAR(255) NULL,
lvl INT NOT NULL
)
AS
BEGIN
DECLARE @lvl AS INT;
SET @lvl = 0;
INSERT INTO @tree
SELECT *,
@lvl
FROM Employees
WHERE EmployeeID = @mgrid;
WHILE @@rowcount > 0
BEGIN
SET @lvl = @lvl + 1;
INSERT INTO @tree
SELECT E.*,
@lvl
FROM Employees AS E
JOIN @tree AS T ON E.ReportsTo = T.EmployeeID
AND T.lvl = @lvl - 1;
END;
RETURN;
END;
GO
SELECT T1.* FROM get_mgremps(5) AS T1;

The function get_mgremps() accepts the employee ID of a manager and returns a rowset in the form of a table variable. Notice that the table variable is defined with similar columns to those in the Employees table in the Northwind database. There is also an additional column called lvl, which stores the depth level of the employee, starting with 0 for the top-level manager, and advancing by one for each subordinate level.
You start by setting the @lvl variable to 0. Next, you insert into the table variable the employee row for the manager, supplied as an argument to the function. All the rest is a loop that inserts the subordinates of the employees from the current level into the table variable. Note that you increment the @lvl variable in each iteration of the loop. The loop is stopped when @@ROWCOUNT equals 0, meaning that there were no rows in the last insert.
User-Defined System Functions
System stored procedures have a very special behavior. They can be invoked from any given database without prefixing their name with the database name, and they refer to system objects in the context of the database from which they are invoked. SQL Server has similar support for functions.
SQL Server supplies two kinds of system functions. The first kind includes the functions that are implemented as part of the SQL Server executable program, such as GETDATE(). We can use these functions in wer T−SQL statements, but their code is not accessible. The second kind includes the functions that are implemented as user−defined functions and are provided with the SQL Server installation. We can actually see the list of those functions by clicking the User Defined Functions node under the master database in the SQL Server Enterprise Manager. This section covers the latter kind user−defined system functions and examines both the functions supplied with SQL Server and ways we can create wer own.
SQL Server provides a few user−defined system functions that have the following characteristics:
- They are created in master.
- Their names start with “fn_”.
- Their names use only lowercase letters.
- They are owned by the user system_function_schema.
SQL Server also supplies functions that are owned by dbo, but an important benefit of functions that are owned by system_function_schema is that they can be invoked from any database without prefixing the function name with the database name.
To see the list of the user−defined functions in the master database, we can run the query shown below, which retrieves both scalar functions (type is ‘FN’) and table−valued functions (type is ‘TF’) with either system_function_schema or dbo as the owner.
USE master;
GO
SELECT *
FROM sysobjects
WHERE type IN('FN', 'TF') --scalar,inline table-valued,table-valued
AND uid IN(USER_ID('system_function_schema'), USER_ID('dbo'));

Invoking a system function owned by system_function_schema is similar to invoking any other system function. We can invoke it from any database without prefixing it with the database name or owner. For example, to check whether a certain character is a whitespace, we can use the fn_chariswhitespace() function.
(Include code from Advanced SQL book after trying werself page 296)
On the other hand, invoking a function that is not owned by system_function_ schema, or does not meet all of the system function characteristics mentioned earlier, requires prefixing it with the owner name when invoking it from the same database where it was created, and prefixing it also with the database name when it is invoked from other databases. For example, the function dbo.fn_varbintohexstr() in master converts the hex digits in a binary string to a character string representation. To invoke it from any database, we can use the form shown below.
(Include code from Advanced SQL book after trying yourself)
(Include the rest from Advanced Book?)